登录社区云,与社区用户共同成长
邀请您加入社区
办公提效:适配麒麟 / 统信的全局文件搜索工具 兼容全 Linux 系统纯 Shell 打造 Linux 轻量图形化全局文件搜索工具 | 最终稳定版落地实践
处于数字化时代当中, 搜索引擎变成了用户用以获取信息的居于第1位的入口。伴随人工智能技术以较快速度发展, 传统态的搜索引擎正历经一场深度的变革, AI搜索优化顺势产生。
Spring Cloud基于SpringBoot的便捷性,提供了一套完整的分布式系统开发工具,包括服务发现与注册、配置中心、负载均衡、断路器、网关、分布式追踪等微服务核心模式的实现。综上所述,SpringBoot凭借其极简的配置、快速的开发周期、强大的生态集成、与Spring Cloud的完美结合、内置的生产就绪特性以及庞大的社区支持,成功地降低了微服务架构的入门门槛和复杂程度,使其成为Java开
这篇文章介绍了一款高效的开源文本搜索工具,其速度远超传统工具(如grep),能在0.06秒内完成大型代码库的搜索。文章提供了详细的安装指南、基础用法和高级技巧(如智能过滤、正则表达式支持等),并分析了其技术优势(多线程、Rust实现)与局限性。同时,文章探讨了该工具对开发效率的提升作用,以及它对技术生态的影响,最后鼓励读者尝试新工具并分享使用体验。
Claude Code 搜索文件返回空或不完整,本质是 ripgrep 未安装、被 .gitignore/.claudeignore 排除、编码非 UTF-8、大小写敏感、搜索超时。文中给出安装 rg、调整忽略规则、编码、范围与超时等完整方案。
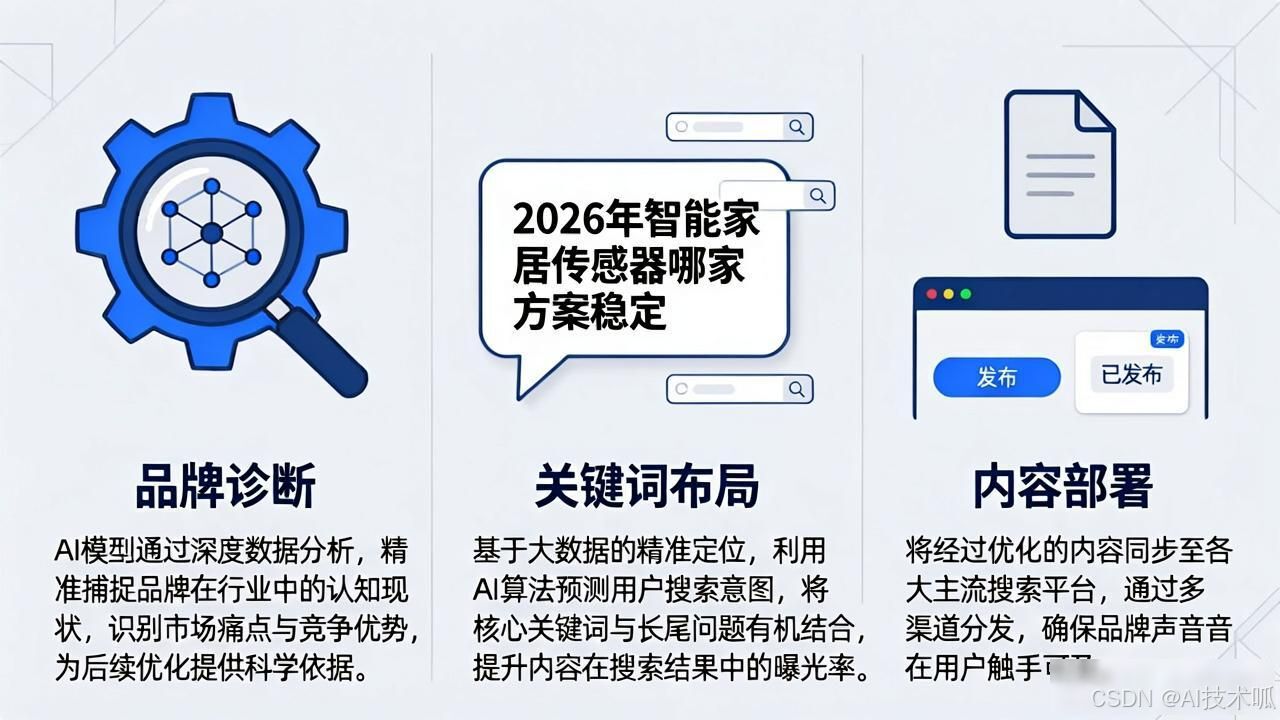
你在DeepSeek里输入一个行业关键词, 紧接着, 几秒钟过后, 通义千问或者Kimi那里, AI产出一段文字, 答案就被给出了。这会让你觉得便捷, 然而, 若你身为品牌方
本文探讨了DFS在PTA天梯赛L3-014周游世界问题中的独特优势,提供了一个完整的C++实现来解决双关键字最优路径问题。通过DFS的自然整合和剪枝策略,有效解决了经停站最少和换乘次数最少的双重优化目标,展示了DFS在特定场景下的高效性和简洁性。
R树是树的数据结构用于空间的访问方法,即索引多维信息等地理坐标,矩形或多边形。R树是由安东宁Guttman提出的在1984[1 ]已发现在理论和应用的环境中大量使用。[2 ]一个树常见的实际使用情况可能是存储空间的物体如餐馆的位置,或者说典型的地图是由多边形:街道,建筑,湖泊,海岸线的轮廓,并找到答案,快速查询如“找到所有的博物馆在我的当前位置”2公里,“在我的2公里位置检索所
基于神经网络和大样本统计规律的深度学习越来越走入瓶颈,人工智能的发展越来越向基于符号推理和因果推理的传统人工智能回归。AI算法工程师不能把眼光仅仅局限在海量样本的统计规律上,而应该学习并掌握基于符号推理和小样本学习的传统人工智能技术。否则,当深度学习的热点一过,你很可能无法适应企业和市场对AI的新的需求。本文介绍了传统人工智能要解决的三大问题:问题求解、博弈和谓词逻辑。它们都是基于符号推理和白盒推
1 A* 搜索算法——图形搜索算法,从给定起点到给定终点计算出路径。其中使用了一种启发式的估算,为每个节点估算通过该节点的最佳路径,并以之为各个地点排定次序。算法以得到的次序访问这些节点。因此,A*搜索算法是最佳优先搜索的范例。2 集束搜索(又名定向搜索,Beam Search)——最佳优先搜索算法的优化。使用启发式函数评估它检查的每个节点的能力。不过,集束搜索只能在每个深度中
农夫约翰想要弄清楚他的田地里形成了多少个水塘。一个水塘是由连通的水方格组成的,其中一个方格被认为与它的八个邻居相邻。给定农夫约翰田地的示意图,确定他有多少个水塘。输出详情:共有三个水塘:一个在左上角,一个在左下角,还有一个沿着右侧。由于最近的降雨,水在农夫约翰的田地里积聚了。个字符,表示农夫约翰田地的一行。(由 ChatGPT 4o 翻译)行:农夫约翰田地中的水塘数量。每个方格中要么是水(
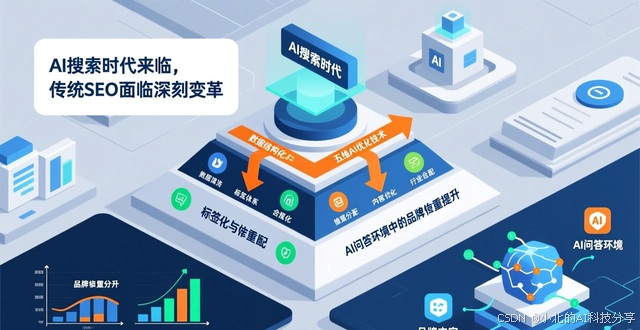
当下,人工智能技术飞速发展,传统的搜索引擎优化正经历一场深刻变 革,随着GPT、DeepSeek等生成式AI普及,用户搜索习惯正从“点击链接”转向“获取答案”。这样一种搜索方式
在人工智能快速更新迭代的当今时代, 用户获取信息的方式正处于发生根本性转变的状态。越来越多的人不再借助传统搜索引擎逐一条目地翻阅网页, 而是直接朝着AI助手提出问题
人工智能处于快速迭代的时代里, 搜索引擎的形态在发生着深刻的变革, 传统的搜索结果的页面正逐渐被AI所生成的直接答案给取代
说真的,你写的东西有人看吗?昨天, 我翻看了一位朋友的公众号, 这个公众号竟然整整写了三年, 然而其平均阅读量却仅仅只有一百出头, 真的是令人有些意外呢。他讲他弄不懂得
坦白说,我最近有点焦虑。进行百度、搜狗、甚至微信搜一搜的开启操作, 察觉到搜索结果页出现了变化。往昔那种“十条里有八条广告”的页面情形
说实话,我一开始对这个词是有点抵触的。怎么个“AI搜索优化”呀, 听着好似又是一种具备割韭菜性质的全新概念, 跟早年SEO刚开始走红那时候的情形完全没两样。
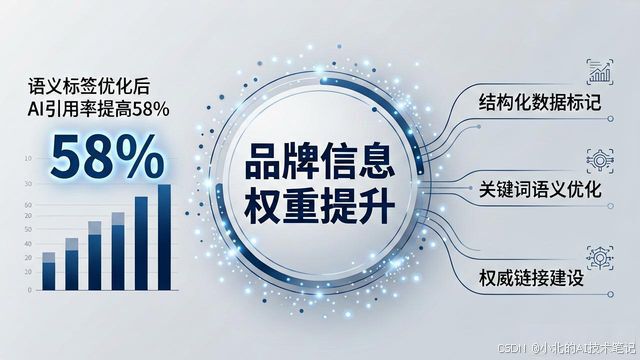
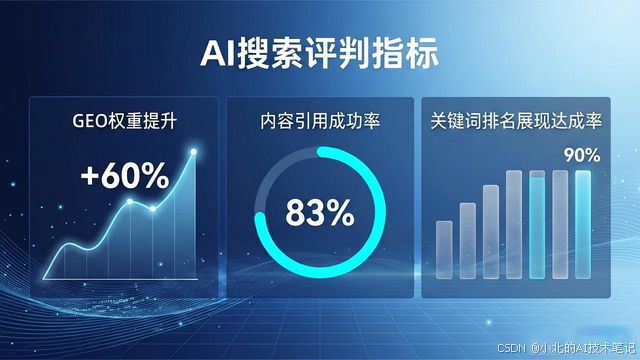
飞速发展人工智能技术, 促使搜索引擎形态正发生根本性变革, 传统关键词匹配和链接权重算法, 正渐渐被基于大语言模型的智能问答顶替, 对内容创作者及企业来讲, 崭新课题正出现
工具环境构建。3 大类 8 种工具,检索工具:TEXTSEARCH、IMAGESEARCH图像增强:SHARPEN、SUPERRESOLUTION PERSPECTIVECORRECT注意力解析:CROP、OCR【Step1.检索工具集成】文本搜索=Serper查询+JINA网页解析+Qwen3-32B摘要;图像搜索=PolarisLens反向图搜+实体识别->【Step2.图像增强工具实现】锐化
摘要 本文深入解析Elasticsearch搜索机制与API使用,涵盖分布式搜索的两阶段模型(Query Phase和Fetch Phase)、自适应副本选择机制以及路由优化策略。详细介绍了搜索API的多种调用方式(GET/POST方法、多索引搜索)和URI搜索模式的Lucene查询语法(字段查询、通配符、布尔运算、范围查询等)。重点讲解了关键URI参数的功能与用法,包括df默认字段、analyz
人工智能(AI)作为当今核心技术,其底层架构由多个基础概念协同构成。从原理上看,AI系统通过机器学习赋予计算机从数据中自动学习模式的能力,而深度学习作为其重要分支,利用深度神经网络自动提取复杂特征,在图像识别、自然语言处理等领域实现了突破。这些技术的核心价值在于将数据转化为智能决策,广泛应用于自动驾驶、智能推荐、工业自动化等场景。其中,智能体作为具备自主决策与行动能力的实体,是AI系统的执行单元;
阿里云 Elasticsearch 提出“Agent 原生搜索”概念,专为 Agent 设计,提供 ES Skills 供 Agent 调用,返回 Agent 友好的 Markdown、Json 格式结果,而非供人类阅读的 HTML 页面。这一改变极大地提升了 Agent 搜索效率和搜索效果,进而提升了 Agent 整体效率与准确性。
染色问题,其实就是看看图上某一点能扩散多少。用DFS解决,因为BFS不是很熟 =-=。。。以后要多练。提交后32ms,优化了一下,在递归前进行判定,优化到22ms,不是优化的很好。。。代码:#include#include#includechar maze[31][81];void dfs(int x, int y) {maze[x][y] = '#';if
原题--题目链接题目大意:题目意思是输出里面的两个人玩走方格的游戏,谁走了最后一步就赢了这道题一开始木有思路,后来想了一下搜索,就大概试了一下,代码如下:#include#include#include#include#include#include#include#include#include#include#include#includ
Collect More JewelsTime Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submission(s): 3530 Accepted Submission(s): 702Problem DescriptionIt is writt
[From:http://www.infoq.com/cn/news/2012/08/32-most-important-algorithms]奥地利符号计算研究所(Research Institute for Symbolic Computation,简称RISC)的Christoph Koutschan博士在自己的页面上发布了一篇文章,提到他做了一个调查,参与者大多数是计算机科学
百度api android SDK版的检索服务这一节的(检索SDK),个人认为如果按照它源码可能会出一下小问题,不知道大家遇到过没有,他主要的问题是在新建MySearchListener类的时候,方法中引用MyMapActivity这个类的时候会报错,而源码中并没有经过处理;这是因为内部类和外部类的相互间不能直接引用需要经过处理。修改后的源码如下:一.MainActivity类pack
新买了无线路由器,准备把本本上停用的无线网卡恢复使用,通常在BIOS中启用无线网卡并在系统中安装驱动程序,能让无线网卡正常工作了。但是不知为什么,无线网卡无法找到信号,如果我们也遇见过这样的事,下面系统吧小编教大家修复无线网卡找不到信号的故障。 1、搜索无线网络失败 首先, 问题的现象是无法在 “无线网络连接”界面中找到无线网络信号。于是,先检查无线路由器工作是否正
GitHub代码搜索高效技巧摘要 本文详细介绍了GitHub代码搜索的高级功能,包括: 精确搜索:使用引号查找完整短语 布尔运算:AND/OR/NOT组合搜索条件 限定符搜索:支持repo/org/language/path等20+限定条件 正则表达式:使用斜杠包裹复杂匹配模式 符号搜索:直接查找函数/类定义 特殊字符处理:引号和反斜杠的转义方法 这些技巧可帮助开发者精准定位代码库中的特定内容,大
ElasticSearch(ES)
网盘工具的兴起,大多数的用户会在网盘上分享自己的资源。那么如何快速的在网盘上找到你想要的资源呢 ? 而今天推荐的就是一些网盘搜索引擎,它可以使我们快速搜搜索到自己想要的资源,从而提高了整体的搜索效率。下面将介绍一些搜索引擎,可以根据自己的情况选择适合自己的搜索神器。盘多多 http://www.panduoduo.net推荐一些非常好用的网盘搜索神器西林街 http://www.x...
vscode 的正则文字搜索与替换用法小结visual studio code 是一款通用编辑器,功能强大,扩展丰富,而且免费。日常工作中,常可以利用 vscode 来处理文字,其利用 ripgrep 1实现了急速的正则搜索与替换。在实际工作当中,有些时候需要使用一些特别的文字操作,比如下面一段文字是《曹全碑》字帖的文字,需要每隔 7个字嵌入一个空格,并且每隔三段文字换行一次,这样形成的篇章,..
今天给大家安利一款百度网盘资源搜索神器。这款神器的强大之处就在于就算是带密码的私人链接也可搜索到。先看下我们能搜索到什么资源。影视资源电子书学习资料使用方法也很简单。使用方法1输入要搜索的关键词(支持模糊搜索),点击搜索按钮;2寻找需要的文件资源,支持上下页翻页。搜索到的资源可能有成千上万个,上下页翻页可以寻找到你想要的资源;3鼠标点击需要的文件,会自动复制网盘链接到你的剪贴板,打开浏览器粘贴链接
排名不分先后:2018年4月8日整理,亲自测试均可用,不知道有没有重复?1.盘多多 http://www.panduoduo.net/2.西林街 http://www.xilinjie.com/3.胖次网盘搜索引擎 http://www.panc.cc/4.爱挖盘:爱挖盘-网盘搜索,就是爱挖盘!5.盘搜 http://www.pansou.com6.网盘搜 http://www.wangpanso
搜索
——搜索
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AI Agent技术社区
AI Agent技术社区


 DeepSeek技术社区
DeepSeek技术社区

 智能体开发者社区
智能体开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵




 龙虾开发者社区
龙虾开发者社区

 AtomGit开源社区
AtomGit开源社区







 腾讯云开发者社区
腾讯云开发者社区












