- @weixin_41368414
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
简 介条件推理树(Conditional inference trees)。条件推断树的算法如下:(1) 对输出变量与每个预测变量间的关系计算p值。(2) 选取p值最小的变量。(3) 在因变量与被选中的变量间尝试所有可能的二元分割(通过排列检验),并选取最显著的分割。(4) 将数据集分成两群,并对每个子群重复上述步骤。(5) 重复直至所有分割都不显著或已到达最小节点为止。条件推理树与决策树有什..
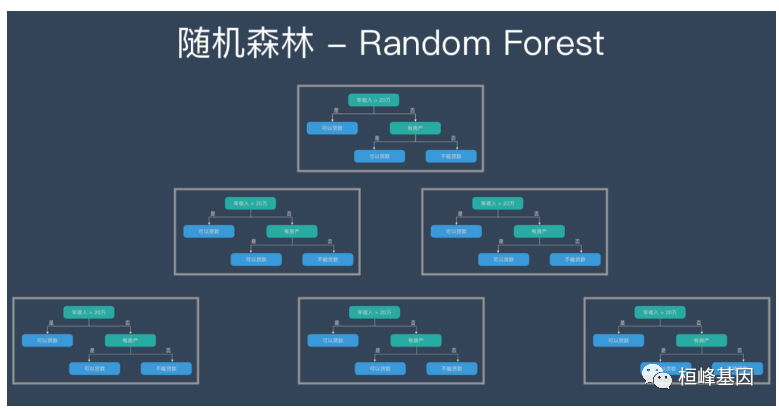
简介条件随机森林(cforest) 是一个R中用于建立随机森林(Random Forest) 模型的函数。随机森林是一种机器学习算法,通过集成多个决策树来进行预测和分类。创建一个大量决策树的模型,每个决策树都是相互独立的。最后的预测使用来自单个树的所有预测并将它们组合起来。在本文中,我们将介绍 cforest 的用法,并提供一些示例代码。软件包安装软件包安装方式:if(!require("par.
这期分享一篇 2024年1月发表于 Briefings in Bioinformatics (IF 9.5)的文章,作者基于深度学习整合bulk转录组和单细胞转录组揭示肝细胞癌的预后和治疗选择中的焦亡特征。该文章使用桓峰基因公众号里面生信分享教程即可实现,有需要类似思路的老师可以联系我们!摘 要虽然已经报道了一些与焦热相关 (PR) 的癌症预后模型,但在肝细胞癌 (HCC) 的单细胞水平上..
这期分享一篇2024年9月发表在 IF 6+ Frontiers in lmmunology 的文章 Novel prognostic signature for hepatocellular carcinoma using a comprehensive machine learning framework to predict prognosis and guide treatment,作者使
这期分享一篇 2024年1月发表于 Theranostics (IF 12.6)的文章,作者基于单细胞和大量转录组学的综合分析开发了一个强大的神经内分泌细胞内在特征来预测前列腺癌的进展。该文章使用桓峰基因公众号里面生信分享教程即可实现,有需要类似思路的老师可以联系我们!摘 要神经内分泌前列腺癌(NEPC)通常意味着严重的致命性和有限的治疗选择。NEPC细胞的精确鉴定对于研究和临床应用具有至关重..
简介弹性网络(Elastic Net):是一种用于回归分析的统计方法,它是岭回归(Ridge Regression)和lasso回归(Lasso Regression)的结合,旨在克服它们各自的一些限制。弹性网络能够同时考虑L1正则化(lasso)和L2正则化(岭回归),从而在特定情况下对于高维数据集具有更好的性能。前面学习了 Ridge 回归与 Lasso 回归两种...
点击“添加分割变量”后,该变量会在元数据框(meta data.frame)中被创建,且所有值默认为“未命名”。由于新的空间分割变量与其他分组变量一样是元特征,因此适用于它的规则和选项与这些分组变量相同,包括getGroupNames()、renameGroups()和relevelGroups()。在转录组学研究中,分组变量通常由聚类算法生成,并以因子的形式存储在元数据框(meta data.f
点击关注,桓峰基因桓峰基因公众号推出机器学习应用于临床预测的方法,跟着教程轻松学习,每个文本教程配有视频教程大家都可以自由免费学习,目前已有的机器学习教程整理出来如下:MachineLearning1.主成分分析(PCA)MachineLearning2.因子分析(FactorAnalysis)MachineLearning3.聚类分析(ClusterAnalysis...
简介机器学习方法通常用于对由数百个属性描述的对象进行分类。在许多这类应用中,很大一部分属性可能与分类问题完全无关。更重要的是,通常人们不能先验地决定哪些属性是相关的。为什么变量选择很重要?删除冗余变量有助于提高准确性。同样,纳入相关变量对模型精度也有积极影响。太多的变量可能导致过拟合,这意味着模型不能泛化模式。太多的变量导致计算速度慢,反过来又需要更多的内存和硬件。R中有很多用于功能选...
SCI 发文章量最大的机器学习算法,癌症诊断机器学习之随机森林(Random Forest)