




- @sadfasdfsafadsa
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
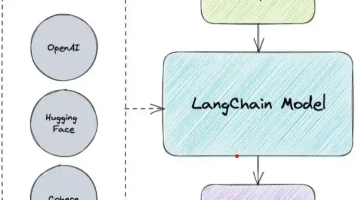
LangChain的ModelI/O模块将大语言模型抽象为三种类型:LLMs(非对话模型)适用于单次文本生成任务,输入输出为文本字符串;ChatModels(对话模型)支持多轮对话,使用结构化消息对象维护上下文;EmbeddingModels(嵌入模型)将文本转换为向量表示。该模块统一了不同模型的调用方式,适用于文案创作、客服机器人、语义搜索等多种应用场景。开发者可通过简单API实现模型调用,支持
LangChain 1.0框架正式发布,标志着这一成熟AI应用开发平台的重要升级。作为2022年推出的经典框架,LangChain提供组件、链、模型I/O等核心功能,帮助开发者快速构建基于大语言模型(LLM)的本地应用。1.0版本将体系调整为LangChain、LangGraph、DeepAgents和LangSmith四大模块,强调产品级稳定性。文章通过阿里百炼平台API调用示例,展示了如何使用
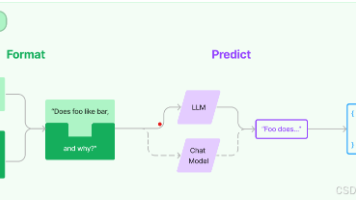
摘要:LangChain框架中的提示词模板是构建和管理大语言模型交互的核心工具,它通过参数化设计实现灵活、可复用的提示管理。提示模板分为多种类型,包括LLM提示模板、聊天提示模板、样本提示模板等,具有提高可读性、增强可重用性、简化维护等特点。使用示例展示了如何通过PromptTemplate和ChatPromptTemplate创建模板并调用模型生成响应。提示模板类似于短信/邮件模板,包含指令、示
文本嵌入模型将文本转换为数值向量,使计算机能够处理语义信息。LangChain框架通过Embeddings类为多种嵌入模型提供统一接口。嵌入模型解决了计算机无法直接理解文本的问题,通过向量化实现语义相似度计算、同义词识别等功能。模型工作原理包括文本分词、神经网络编码和向量生成过程,生成的向量具有语义保持性、上下文敏感性等特点。通过向量空间中的距离计算(如余弦相似度)可评估文本相似度。实际应用中,可

输出解析器(OutputParsers)是处理大型语言模型(LLM)输出的关键工具,用于将自由格式文本转换为结构化数据(如JSON、字典等)。主要作用包括:1)标准化输出格式,解决LLM返回内容不一致问题;2)提供错误处理机制;3)简化下游程序处理。常见解析器类型包括基础解析器(如StrOutputParser、JsonOutputParser)和高级解析器(如StructuredOutputPa
本文介绍了LangChain框架中的向量存储组件,该组件通过将文本转换为向量表示来实现高效的非结构化数据存储和检索。文章详细阐述了向量存储的工作原理、支持的多种数据库(如Chroma、FAISS、Pinecone等)以及核心操作方法,包括文档管理、基本检索和高级搜索策略。同时提供了使用阿里云DashScope嵌入模型和FAISS向量数据库的代码示例,展示了如何实现文档分割、向量转换和相似性检索等功

LCEL(LangChain表达式语言)是LangChain引入的声明式编程语言,用于简化LLM工作流的构建。它通过管道符号(|)连接组件,将提示模板、模型和输出解析器等模块化元素组合成链式结构。相比传统方式,LCEL代码更简洁且支持流式处理、异步调用、并行执行等特性,同时内置LangSmith跟踪和LangServe部署能力。其核心优势在于实现开发与生产环境的无缝切换,通过职责分离(提示模板化、

本文介绍了检索增强生成(RAG)技术及其在政府网页智能问答系统中的应用。RAG通过给大模型添加"知识外挂",无需微调即可调用特定领域知识。系统采用LangChain框架,整合网页爬取、文本分割、向量化存储(FAISS)、智能检索和回答生成(通义千问)全流程。实战演示了如何搭建该系统,包括环境准备、核心代码解析及常见问题解决。该系统具有轻量化、易用性等特点,可快速适配政务、金融等

本文介绍了一种基于向量检索的本地文档语义搜索系统构建方法。通过LangChain的DirectoryLoader/TextLoader加载本地TXT文档,使用BCE嵌入模型将文本转换为向量,并利用FAISS实现高效相似度匹配。系统支持批量文档处理和带评分的语义检索,得分越低表示匹配度越高。该方法完全离线运行,保障数据安全,可扩展支持PDF、Word等多种格式,适用于企业文档检索和个人知识管理。核心

本文详细介绍了PyPDFLoader在LangChain中的使用方法。PyPDFLoader是处理PDF文档的核心工具,支持本地和远程PDF加载,提供load()、load_and_split()和lazy_load()三种加载方式,返回包含文本内容和元数据的Document对象。文章还展示了如何指定页码范围加载内容,并给出了结合DeepSeek大模型实现PDF内容总结的完整代码示例,包括环境配置
