登录社区云,与社区用户共同成长
邀请您加入社区
HDFS 是 Apache Hadoop 项目中的核心组件之一,专为大规模数据集的存储和处理而设计。它采用了主从架构(Master-Slave Architecture),其中 NameNode 是中心节点,负责管理文件系统的命名空间和客户端对文件的访问控制。DataNode 是从节点,负责实际的数据存储和读写操作。高容错性:通过副本机制确保数据的可靠性和可用性。适合批量处理:优化了顺序读取和写入
JuiceFS 是一个面向云原生的高性能 POSIX 文件系统,它将数据与元数据分离:元数据存储在 Redis 或 SQL 数据库中,数据则存储在对象存储(如 S3、Ceph RADOS)中。- JuiceFS + Ceph:总耗时 12 秒(平均 120ms/文件)- NFS:总耗时 58 秒(平均 580ms/文件)## 遇到的大坑与解决方案### 坑 1:Redis 内存爆炸现象:文件数超过
使用 cephadm + Docker 镜像在三台服务器上部署 Ceph 集群(含网络规划与 OSD DB/WAL 分离)
Ceph 需要在工作节点(Worker Nodes)上拥有未格式化的裸盘(Raw Devices)或独立的分区。例如/dev/sdb。在目标节点上执行lsblk -f命令。FSTYPEMOUNTPOINTFSTYPE如果磁盘有残留的文件系统签名,可以使用(替换为实际盘符) 进行擦除。:所有 K8s 节点需要安装lvm2包。:Ceph 对内存和 CPU 消耗较大,建议每个 OSD(对应一块硬盘)预留
对象存储将数据存储为对象Key(键):对象的唯一标识(类似文件名)Data(数据):文件的实际内容Metadata(元数据):描述对象的属性(如 Content-Type、自定义键值对)特点块存储(RBD)文件存储(CephFS)对象存储(RGW)数据组织固定大小的块层级目录树扁平桶+对象访问协议SCSI、iSCSINFS、POSIX适合场景数据库、虚拟机共享文件、HPC海量非结构化数据、备份、静
本文档详细介绍了在Kubernetes集群中部署高可用Loki日志系统的读写分离架构方案,主要特点包括: 采用读写分离架构(Write/Read/Backend)支持TB级日志处理 使用Ceph S3对象存储作为后端存储 实现Nginx日志与其他业务日志的物理分离 部署步骤包含: Ceph S3(RGW)环境准备与配置 创建保留策略的StorageClass 通过OBC为Loki创建专属Bucke
Rook是一款开源的云原生存储编排工具,专为Kubernetes设计,可将Ceph分布式存储系统与K8s深度集成。它通过Kubernetes Operator模式自动化管理Ceph集群,包括部署、扩容、版本升级和故障恢复等复杂运维操作,大幅降低人工管理成本。作为CNCF毕业项目,Rook已通过生产验证,支持Helm或YAML安装,提供稳定的存储服务。对于需要在K8s上运行有状态应用的企业,Rook
先把背景说清楚,后面算费用才有意义。和。V4-Pro 是这次的主角。1.6T 参数,但采用 MoE(Mixture of Experts)架构,每次推理只激活 49B 参数。这个设计直接决定了它的成本优势——计算量只有 Dense 同参数模型的一小部分,但性能却能打到接近顶级。DeepSeek 官方的说法是,V4-Pro 在主流 benchmark 上比 Claude Sonnet 4.5 高,与
/ 触发自动压缩的 token 阈值。// Layer 3: 如果调用了 compact 工具,执行手动压缩。// Layer 2: 如果 token 数超过阈值,自动压缩。// Layer 3: 如果调用了 compact 工具,执行手动压缩。// Layer 2: 如果 token 数超过阈值,自动压缩。// Layer 3: 如果调用了 compact 工具,执行手动压缩。
我们有一块普通的硬盘,想在上面存 Ceph 的对象(比如一张图片)。操作系统教我们:先格式化一个文件系统(比如 XFS),然后open一个文件,把数据write进去。灵魂拷问 1直接用操作系统的文件系统存数据,有什么不对吗?在早期的ceph(FileStore时代),我们就是这么干的。但运行久了,发现了几个及其别扭的“拧巴”现象:拧巴点一:写 4KB 数据,磁盘写了两次。拧巴点二:修改文件中间的1
Ceph Reef ARM镜像兼容性问题改用 Quincy 17.2.8。
不得不说,COMSOL这玩意儿真是个神器,尤其是当你需要同时考虑电场和温度场的时候。总之,COMSOL在有限元仿真中的应用非常广泛,尤其是在多物理场耦合方面,它的强大功能可以帮我们解决很多实际问题。所以,搞明白它的温度场和电势分布,对设计和优化绝缘子来说至关重要。通过这几步,我们就可以得到一个瓷绝缘子的电热耦合模型,并观察到它的温度场和电势分布。当然,这只是一个简单的模型,实际应用中可能还需要考虑
焊缝跟踪 abb机器人二次开发上位机由C#+halcon联合编程提供源码讲解,abb编程及通讯、工业相机标定、halcon图像处理、C#与halcon联合编程等。
基本做云平台的,VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。基本做云平台的,VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程
本次来聊一聊isa-l,即ceph的纠删码插件之一。当然这个值曾经默认是jerasure。关于纠删码的原理其实就像是线性代数中解线性方程组。这部分就不赘述。本次重点关注isa-l中的两个函数。本次主要关心的问题:在已经知道旧的校验块后和旧的数据块和修改后的数据块后怎么快速得到新的校验块。首先isa-l库是可以独立单独运行的,首先从https://github.com/ceph/...
集群配置以及用户授权配置使用cephadm安装完成ceph之后,会在/etc/ceph目录中自动生成ceph的配置文件ceph.conf,采用ini file格式,使用#或者;对配置进行注释global 全局配置,对所有的服务和客户端有效,优先级最低mon mgr osd等都是ceph相关组件的配置配置修改登录后复制#...
本文系统讲解Kubernetes存储体系,内容涵盖: 核心概念演进:从基础Volume到PV/PVC/StorageClass的完整链路,实现存储与应用的解耦 存储生命周期:详细解析Provisioning→Binding→Using→Reclaiming四个阶段 基础Volume类型:包括emptyDir、hostPath、configMap/secret、downwardAPI等特性与应用场景
组件功能MON维护集群状态映射(Cluster Map),通过Paxos算法保证一致性,奇数个节点构成仲裁OSD对象存储设备,实际存储数据,处理数据复制、恢复和再平衡MGR提供集群监控、Dashboard Web界面和REST APIMDS元数据服务器,仅为CephFS服务,管理文件名、目录、权限等元数据RADOS可靠自主分布式对象存储核心,实现CRUSH算法进行数据分布部署规划MON节点奇数个(
如果 RAID 卡再额外对这些盘进行读缓存、写回缓存、I/O 重排或延迟落盘,就会在主机和磁盘之间增加一层 Ceph 无法感知和控制的缓存语义,轻则影响性能判断,重则影响故障场景下的数据一致性和恢复行为。而机械硬盘的自身写缓存大多属于易失性缓存,通常缺少可靠的掉电保护,一旦意外断电,尚未来得及落盘的缓存数据就可能丢失,因此在对数据一致性要求较高的场景下,通常建议开启企业级 SSD 的自身缓存,而关
Ceph 作为一款开源的分布式存储系统,以其高可靠性、高扩展性和高性能的特点,在云计算、大数据等领域得到了广泛应用。然而,Ceph 的部署与配置过程相对复杂,涉及操作系统配置、网络设置、硬件优化等多个环节,对于初学者和运维人员来说具有一定的挑战性。本文旨在提供一份详细的 Ceph 集群部署与操作指南,从最基础的环境准备开始,逐步讲解 Ceph 的安装、配置、优化及基本使用。
Ceph 对象网关是一个构建在librados之上的对象存储接口,Ceph 对象存储支持两个接口:兼容 S3 :通过与 Amazon S3 RESTful API 的大部分子集兼容的接口提供对象存储功能。兼容 Swift:提供对象存储功能,其接口与 OpenStack Swift API 的大部分子集兼容。Ceph 对象存储使用 Ceph 对象网关守护进程 ( radosgw),它是用于与 Cep
虚拟磁盘存储(用于虚拟机)Linux内核挂载(krbd模块)QEMU/KVM和OpenStack Cinder启动支持快照、克隆、精简配置:使用存储桶(bucket)和对象:使用容器(container)和对象RGW守护进程(radosgw)提供HTTP/HTTPS服务,支持多站点部署和负载均衡。CephFS是一个兼容POSIX的分布式文件系统,构建在RADOS之上。支持多活MDS(元数据服务器)
Ceph是一个开源的统一分布式存储系统,基于RADOS核心提供对象、块和文件存储服务。文章介绍了Ceph的架构、访问方式(原生API/块设备/对象网关/文件系统)和核心组件(MON/OSD/MGR/MDS)。重点讲解了使用cephadm工具部署Ceph集群的完整流程,包括环境准备、集群初始化、节点添加、服务部署(MON/MGR/OSD)和验证方法。还涉及集群配置管理和组件操作,如禁用自动扩展、删除
开源、分布式、软件定义存储(SDS)极高可用性、扩展性、易用性,用于存储海量数据可部署在通用服务器(x86 或 ARM)上,支持异构集群。
📌 OpenClaw2.7.5快速安装指南 ✅ 45.7MB安装包下载 ✅ 4步完成安装配置 ✅ 基础命令验证与使用 ✅ 常见问题解决方案 🔗 下载链接:[获取OpenClaw2.7.5] 💡 提示:确保网络畅通+英文路径安装 🚀 新手友好,轻松开启开发之旅! ✨ 完整教程+emoji交互体验 ⚡ 高效开发从安装开始
定义:开源、软件定义存储(SDS),可运行在通用x86/ARM服务器上。核心优势RADOS:可靠的自主分布式对象存储,作为Ceph的心脏。去中心化:客户端通过CRUSH算法直接计算对象存储位置,无需中心查表。自动扩展:集群可自动进行数据再平衡和恢复。通过第一章的理论学习,我们掌握了Ceph的角色划分、RADOS核心架构、CRUSH算法以及四种访问方式。第二章则动手实践了基于Cephadm的集群部署
开源软件定义存储(SDS),纯分布式架构,面向海量数据场景。核心优势:高可用、高扩展、易运维,支持x86 / ARM混合架构服务器部署。底层基础:基于RADOS(可靠自主分布式对象存储),统一提供对象、块、文件三种存储服务。核心底层:RADOS(可靠自主分布式对象存储),Ceph 一切功能的基础,数据以对象形式存储,具备自我管理、自我修复能力。上层访问接口:基于 librados 封装,提供对象、
在配置RGW网关之前,首先需要检查一下网关服务是否正常。首先通过docker exec mon ceph -s 查看集群的状态是否HEALTH_OK,同时需要看看rgw组件是否正确启动,本案例,我设置的rgw端口号是20003,即地址是: http://{服务器IP}:20003,正常可以显示信息。
Linux 驱动开发的本质,其实就是给操作系统写一个硬件的“专属翻译官”。因为硬件(比如显卡、网卡、传感器)只听得懂底层的电信号和寄存器指令,而 Linux 内核和应用软件只懂标准的系统指令。驱动就是夹在中间的那层软件,负责把上层的指令“翻译”成硬件能懂的操作,再把硬件的反馈“翻译”回上层。物理设备并不是驱动“变”出来的,而是原本就存在的。驱动注册后,内核会帮你在系统里“找到”这些设备。热插拔发现
✨ 适配系统:Windows 10/11 64 位✨ 当前版本:v2.7.5(虾壳云版)✨ 核心优势:全程可视化操作,无需命令行或手动配置 Python/Node.js,内置全部运行依赖,约 5 分钟完成部署,新手也能轻松上手!核心前置提醒(安装成功关键)安装 / 解压 / 运行前,请务必彻底关闭所有杀毒软件(360 安全卫士 / 腾讯电脑管家 / 火绒 / Windows Defender 实时
Ceph分布式存储系统部署指南 Ceph是一个开源的分布式存储系统,通过软件定义方式将多台服务器的硬盘整合为统一存储资源池。本文详细介绍了Ceph集群的部署流程: 核心组件部署 监控节点(MON):部署3个节点实现高可用,负责集群状态管理 管理节点(MGR):部署主备节点,提供监控和管理功能 存储节点(OSD):每个节点配置2块硬盘,通过CRUSH算法实现数据分布 部署步骤 环境准备:网络划分、时
Ceph Monitor是Ceph集群的管理核心,负责维护集群状态信息(Cluster Map)并确保各组件间的一致性。它基于Paxos算法实现多Monitor节点间的数据同步,通过Leader选举机制,保证高可用性。Monitor包含多种类型:AuthMonitor负责认证授权、HealthMonitor监控自身状态、MDSMonitor管理元数据服务器、OSDMonitor维护OSD状态、PG
本文复盘一例 Ceph OSD 高时延问题:在集群健康、主机资源和网络正常的情况下,通过 `ceph osd perf`、`iostat`、`blktrace` 逐步定位到 BlueStore `db/wal` 直通机械盘的小块同步写确认过慢;改造成单盘 RAID0 并启用 RAID 缓存后,时延显著下降,验证了问题根因在介质与写入模型不匹配。
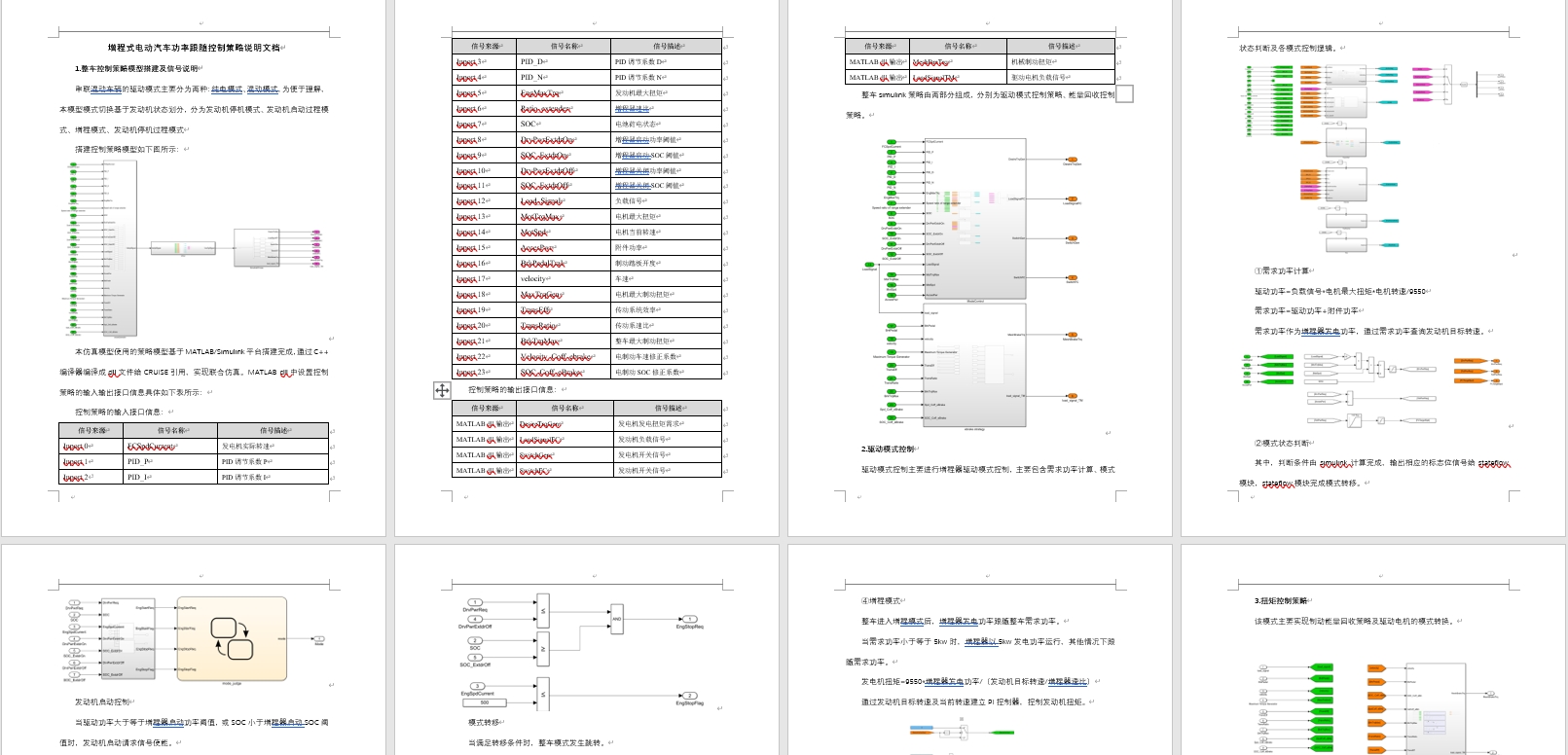
这个模型是基于增程混动架构搭建的Cruise仿真模型,它的控制策略是功率跟随控制,这里跟随的对象呢,就是整车需求功率。整个模型是以Cruise/Simulink搭建的base模型为基础。策略模型在MATLAB/Simulink平台上完成搭建,然后通过C++编译器编译成dll文件,供CRUISE引用,进而实现联合仿真。
本文详细介绍了使用Helm3部署Ceph CSI插件,实现Ceph Quincy 17.2.9与Kubernetes 1.23.17对接的完整流程。主要内容包括:Helm3的二进制安装方法;通过官方Ceph CSI Helm Chart进行部署的步骤,包含添加仓库、搜索和下载特定版本Chart;以及详细的values.yaml配置文件示例,涵盖了RBAC、ServiceAccount、CSI连接配
一键部署 Ceph 集群!Ansible 运维实战教程
ceph
——ceph
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区





 DeepSeek技术社区
DeepSeek技术社区
 openEuler 社区
openEuler 社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵







 AtomGit开源社区
AtomGit开源社区





 AI Agent技术社区
AI Agent技术社区



 龙虾开发者社区
龙虾开发者社区





 腾讯云开发者社区
腾讯云开发者社区
