登录社区云,与社区用户共同成长
邀请您加入社区
本期重点测最颠覆的 AI 代理:把目标网址和你要的字段用中文描述一遍,它先生成结构化 schema 让你确认,再自动写出采集逻辑,点一下测试运行,几分钟就拿到了干净的表格化数据——我一行代码没写。而自愈只要用大白话描述"哪里采不到了",它就自动分析、重写受影响代码,数分钟修复并一键发布,不限你用哪种方式建的爬虫。最后我们还用 CLI 命令行直接跑通了同一个爬虫,把结果导出成 JSON——说明它既能
'latin-1' codec can't encode characters in position 5-17: ordinal not in range(256)编码问题
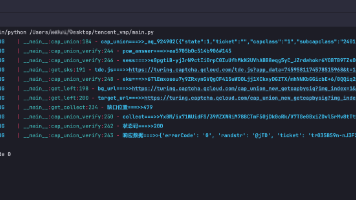
腾讯滑块(天御) vmp逆向
本文介绍了如何基于Scrapy和Redis构建分布式爬虫系统。主要内容包括:1)分布式爬虫原理,通过多节点协同工作突破单机性能瓶颈;2)环境配置,安装Scrapy、Scrapy-Redis和Redis服务器;3)实现步骤,包括创建项目、修改配置、编写爬虫代码和存储管道;4)启动方法,通过Redis队列分发任务;5)优化策略,如反爬应对、性能调优和监控方案。该架构能高效完成海量数据爬取,同时提供了扩
通过以上系统学习,您将能够从零基础逐步掌握Python网络爬虫开发,最终达到精通水平。建议每个阶段都动手实践,通过实际项目巩固所学知识。网络爬虫(Web Crawler)是一种自动化程序,用于从互联网上抓取数据。首先,您需要在计算机上安装Python和PyCharm 2021。3.8+),安装时务必勾选"Add Python to PATH"选项。6.1 处理动态加载内容(使用Selenium)6
本文介绍了网络爬虫的基本概念与应用场景,详细讲解了robots协议(爬虫规则)的重要性,并以TIOBE编程语言排行榜为例演示了爬虫入门程序。内容包括:爬虫的定义(自动抓取网络数据的程序)、典型应用场景(搜索引擎、舆情监控等)、robots协议解析(通过robots.txt文件规定爬虫访问权限),以及使用Python的requests库实现简单爬虫的代码示例。重点强调了遵守robots协议的必要性,
传统多线程爬虫依托操作系统线程调度实现并发,虽然相比串行爬虫效率显著提升,但线程存在系统资源开销、线程数量上限、线程切换损耗等短板。当面对上千条链接批量采集、海量图片下载场景,多线程依旧存在性能天花板。协程(Coroutine)基于用户态实现并发,由程序自身调度任务,无需操作系统切换线程,内存占用极低、可同时维持数千并发连接,是当前 IO 密集型爬虫最优高性能方案。Python 生态中aiohtt
AI 模型的训练效果高度依赖数据的规模、多样性和质量。无论是 LLM 的预训练语料、计算机视觉的图像数据集,还是推荐系统的行为数据,公开网络都是最大的数据源。
使用 Bright Data CLI 与 MCP,将 Claude Code 接入实时 Web Scraping 能力,实现 Amazon 多站价格抓取、SERP 搜索和 AI Agent 自动化
网络爬虫(Web Crawler),也称为网页蜘蛛(Spider)、网络机器人(Bot),是一种自动化程序,用于按照一定的规则自动浏览万维网(WWW),并获取网页内容。爬虫技术在当今互联网时代扮演着至关重要的角色,它是搜索引擎、数据挖掘、内容聚合、舆情分析等众多应用的基础。在2026年,爬虫技术已经发展到一个新的高度。随着人工智能和大数据技术的快速发展,爬虫不再仅仅是简单的网页内容抓取工具,而是成
《泛程序概念爆火:整合型技术模式重塑行业体验》摘要: 近期科技圈热议的"泛程序"是一种整合多功能的创新技术模式,其核心在于将各类服务封装成可灵活调用的"数字百宝箱"。以电商行业为例,泛程序能整合社交、推荐、物流等全流程功能,使平台用户留存率平均提升20%。专家指出,企业需根据规模匹配应用策略——小型企业可简化使用,而大型企业则能通过泛程序实现业务系统整合。这
本文摘要主要介绍了音乐推荐系统的技术背景、开发环境和核心功能。音乐推荐系统利用人工智能和机器学习技术解决数字音乐时代的信息过载问题,通过分析用户行为和音乐元数据实现个性化推荐。系统基于Java语言开发,采用SpringBoot框架简化配置,MySQL5.7作为数据库。管理员可通过后台路径访问系统,核心功能包括用户行为分析、音乐内容过滤及推荐算法实现。系统界面展示了歌曲管理、用户偏好分析等模块,关键
这次的脚本采集功能用到的是Bright Data的网页爬虫APIs,它封装了采集zillow的数据接口,能自动处理IP代理、验证码、JS动态渲染,可以稳定地通过关键词、url进行数据采集。因为我经常需要用Agent搜集网页数据,比如谷歌、推特、领英之类的网站,Agent虽然可以写爬虫代码,但没法处理IP检测、反爬机制等问题,所以需要配置爬虫MCP或者采集API。Bright Data的采集方案还有
摘要 二手书籍售卖管理系统基于Java与Spring Boot框架开发,结合MySQL数据库,旨在解决传统二手书籍交易中的效率低、信息不对称等问题。系统面向高校学生及低收入群体,提供书籍分类、品相评估、智能定价等功能,支持在线发布、搜索、支付及物流一体化服务。通过促进书籍循环利用,系统符合可持续发展理念,同时降低用户购书成本。技术实现上采用模块化设计,集成云计算与大数据优化交易流程,具备高扩展性与
该项目是一个网页爬虫的python包,使用LLM和直接图逻辑(direct graph logic)来为网页和本地文档(XML, HTML, JSON)创建爬取管道(pipeline)。一句话足矣~本文主要是通过Scrapegraph-ai集成gpt3.5实现一个简单的网页爬取并解析的demo应用,其中涉及到gpt3.5免费申请,Scrapegraph-ai底层原理简介,demo应用源码等。之后会
反爬机制是一种技术,用于防止爬虫在不允许的情况下访问网站。它可以采取各种形式,例如验证码、IP封锁、请求频率限制等等。这些反爬机制的目的是防止爬虫访问网站并获取数据,从而保护网站数据的安全。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱
gospider 是一个golang 爬虫神器,它内置了多种反爬虫模块,是golang 爬虫必备的工具包。
cpolar+ngrok内网穿透完美白嫖!(免费,免费,免费)
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。🧡AI职场汇报智能办公文案写作效率提升教程 🧡专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的
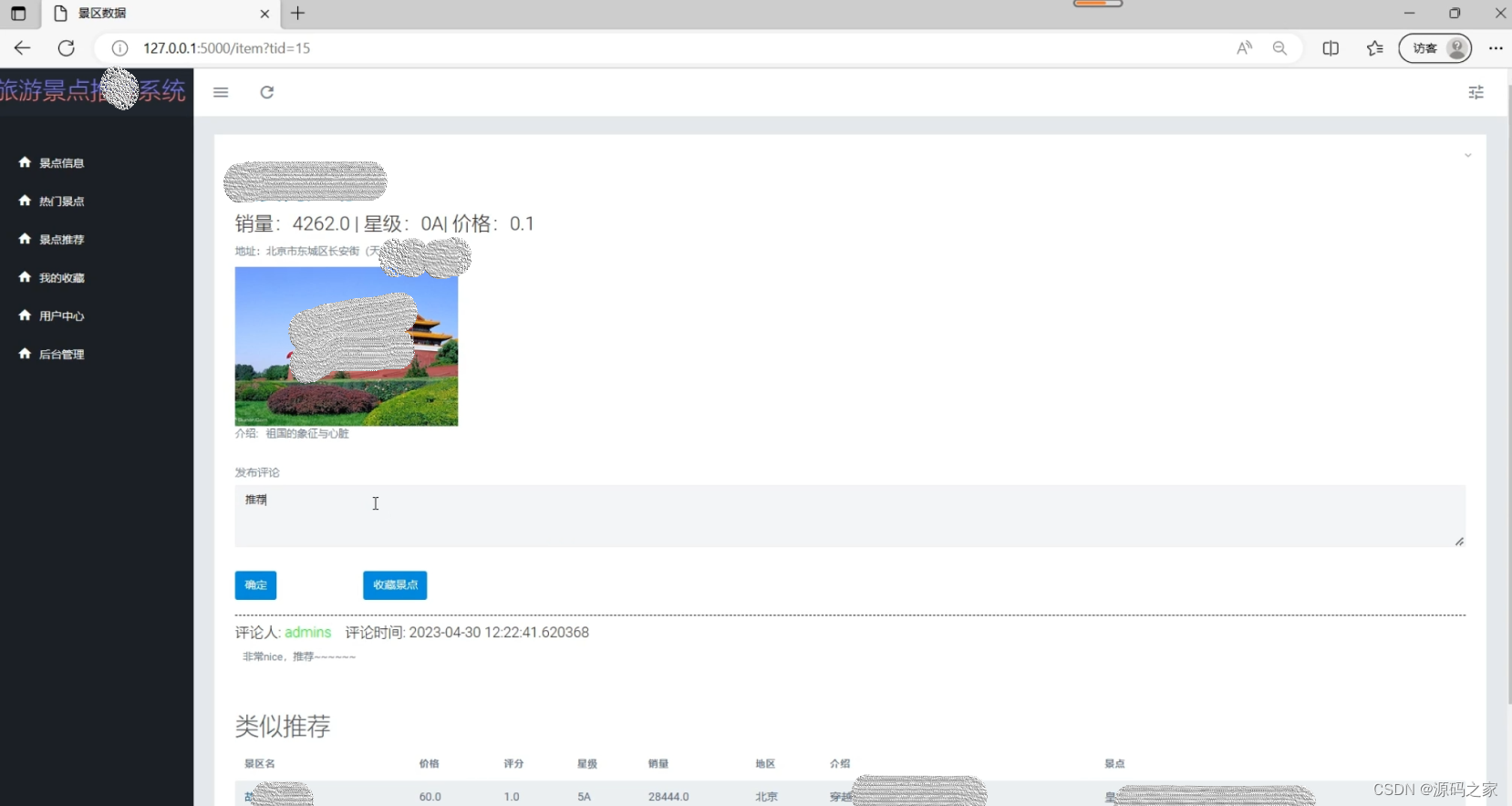
deepseek毕业设计:基于python热门旅游景点推荐系统 协同过滤推荐算法 爬虫技术+可视化 +Flask框架 计算机毕业设计(附源码)✅
本文主要是通过Scrapegraph-ai集成gpt3.5实现一个简单的网页爬取并解析的demo应用,其中涉及到gpt3.5免费申请,Scrapegraph-ai底层原理简介,demo应用源码等。
本文摘要: 企业资产管理系统(EAM)的开发背景源于传统人工管理方式效率低、易出错的问题,尤其在资产规模扩大、种类复杂的企业中表现突出。系统基于Java语言(面向对象、多线程)和Spring Boot框架(简化配置、集成化)构建,搭配MySQL数据库(高效、安全、易用),实现资产全生命周期数字化管理,涵盖采购、维护、折旧等环节。系统支持多终端操作,通过物联网和AI技术提升故障预测能力,并满足合规性
企业招聘平台系统开发摘要 本项目基于Java+SpringBoot+MySQL技术栈开发智能化企业招聘平台,旨在解决传统招聘效率低、匹配度不足等痛点。系统采用SpringBoot框架简化配置,集成MySQL数据库实现高效数据管理,并利用人工智能技术优化简历筛选与职位匹配功能。 核心模块包括:多角色权限管理(企业/求职者/管理员)、智能算法推荐岗位、在线简历投递与视频面试、企业人才库管理及数据分析看
亿家购物商城系统摘要 亿家购物商城系统是基于Java和Spring Boot开发的电商平台,旨在为中小企业和消费者提供高效、安全的在线交易服务。系统整合人工智能推荐、区块链安全交易、云计算等技术,支持PC端、移动端及小程序多终端访问,并融入社交电商模式(如拼团、直播带货)。采用MySQL数据库确保数据稳定存储,结合智能仓储和自动化物流优化用户体验。项目顺应电商数字化趋势,响应国家政策,助力中小企业
本文介绍了健康档案管理系统的选题背景,该系统旨在解决传统纸质档案管理模式的不足,满足现代医疗信息化需求。随着人口老龄化和慢性病增多,传统方式难以高效管理医疗数据。政策支持和技术进步为系统建设提供了条件,如中国的"健康中国2030"和美国的HITECH法案。系统可应用于个人健康管理、医疗机构协作和公共卫生监测等领域,但仍面临数据标准化、隐私保护和基础设施等挑战。未来,结合5G、物联网等技术,系统将向
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
荔枝网wasm加密逆向
Archive.today 是一个网页存档服务,允许用户保存网页的快照,即使原网站删除了内容,存档仍可访问。它特别擅长绕过付费墙,让读者免费访问付费内容。例如,当你想查看《经济学人》的付费文章时,只需将链接粘贴到 Archive.today,即可查看完整内容。这种功能让它成为许多读者的「救星」,但也让它成为媒体公司的眼中钉。维基百科等平台长期依赖它来验证引用来源,因为许多新闻网站会删除旧文章,而
思路来自ai:Nginx可以通过多种方式来限制爬虫的行为:1. **User-Agent限制**:可以通过检查HTTP请求的User-Agent头部来识别并限制某些爬虫。例如,可以在Nginx配置文件中使用`if`语句来检查User-Agent,并使用`return`指令拒绝特定的User-Agent。
计算机毕业设计hadoop+spark+hive智慧交通 交通客流量预测 大数据毕业设计(源码+论文+PPT+讲解视频)
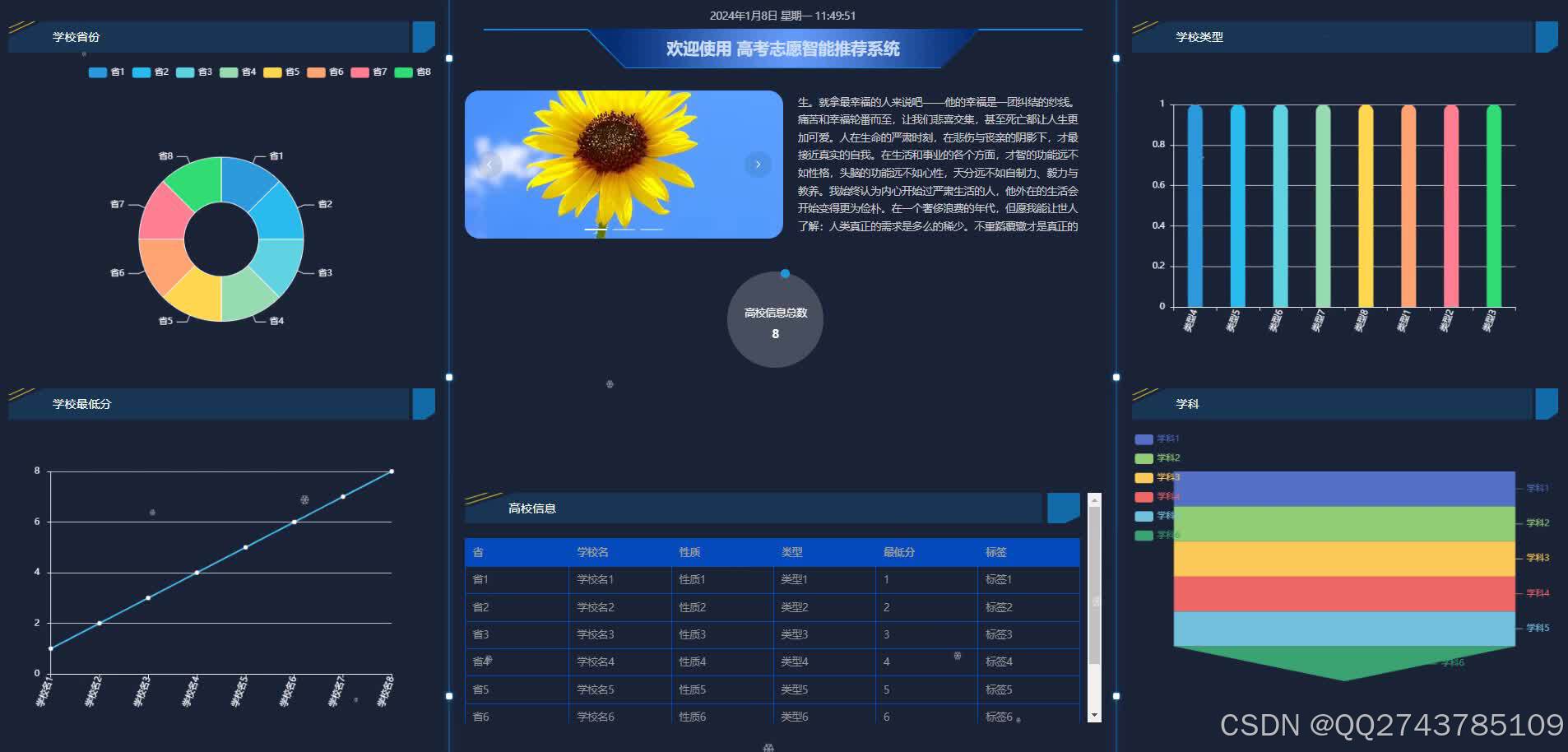
该系统通过爬虫技术从各省市教育考试院网站、高校招生网站等渠道采集高考相关数据,包括分数线、录取情况、专业设置等关键信息。然后,利用Spring Boot框架构建后端服务,对数据进行清洗、整合和分析。最后,通过前端用户界面,为考生提供智能的志愿推荐和详细的志愿填报指导。
点击顶部导航栏的"设置"按钮可以配置以下选项:默认导出格式PDF页面大小和边距Word样式模板图片处理方式下载文件保存路径自动清理临时文件周期点击"保存设置"按钮。
作为专业智能创作助手,我将为您详细解析如何使用aiohttp库构建异步爬虫,以实现高效爬取百万级数据的目标。aiohttp基于Python的asyncio框架,利用异步I/O避免阻塞,显著提升爬取效率。核心优势在于:通过并发处理多个请求,减少等待时间,时间复杂度可优化至$O(n)$(其中$n$为请求数量),而传统同步爬虫则为$O(n \times t)$($t$为平均响应时间)。实际测试中,在10
WASM(WebAssembly) 是一种在浏览器中运行的 高性能、低级别的二进制代码格式,它让你可以用如 C/C++、Rust 等语言编写程序,然后编译后在网页上运行,就像 JavaScript 一样。
随着互联网技术的发展和人们旅游需求的多样化,传统旅游信息获取方式已无法满足用户个性化和高效化的需求。本文建立海南旅游的个性化推荐系统的实例,系统采用B/S架构,前端采用Vue框架,后端采用Java以及SpringBoot技术主要框架在Java平台上实现,数据存储采用MySQL。同时该系统实现了针对管理者和一般游客的不同需求,其中的管理工作包括用户管理、海南旅游景点管理、景点分类管理、旅游路线管理、
掌握GitHub开源项目从0到10k+ Stars的系统化运营方法论学会撰写高转化率的README,提升项目首页留存率至70%+建立完善的贡献者流程,将潜在贡献者转化率提升3倍构建活跃开源社区,实现月活贡献者50+、Issue响应时间<24h通过技术博客和社交媒体实现有机流量增长,获得持续曝光
而基于 Java 异步编程模型构建的爬虫,能充分利用网络 IO 等待时间,并发处理多个请求,大幅提升数据获取效率。而异步模式下,线程发起请求后无需等待响应,可立即处理下一个请求,响应返回时通过回调函数处理结果,线程利用率提升数倍。高并发:单线程可处理数百个并发请求,相比同步爬虫(单线程仅能处理 1 个请求),效率提升显著;异步爬虫利用网络 IO 等待时间并发处理请求,耗时仅为同步爬虫的 1/6,且
爬虫
——爬虫
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深圳城市开发者社区
深圳城市开发者社区

 深开鸿 技术专区
深开鸿 技术专区







 openEuler 社区
openEuler 社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 智能体开发者社区
智能体开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵

 AtomGit AI 社区
AtomGit AI 社区


 MCP技术社区
MCP技术社区

 AI编程社区
AI编程社区