登录社区云,与社区用户共同成长
邀请您加入社区
让我们先看一组真实的数据。作为独立开发者,我们经常在应用商店的评论区看到这样的现象:一个用户给出了三星评价,评论内容是"功能还不错,但希望能支持深色模式"。这位用户其实并不想打三星——他只是找不到一个地方来表达他的需求。于是,应用商店评论区变成了一个"功能请求信箱",而开发者得到的却是一个拉低评分的负面评价。这暴露了一个深刻的命题:如果你的应用里没有一个说得过去的反馈通道,用户就会去你能看见的地方
HarmonyOS 应用开发者高级认证的价值,不只是增加一行证书经历,而是迫使开发者把碎片化知识整理成完整能力结构。以官方大纲为基线;以官方课程和文档为主要资料;以 ArkTS 编程保持基础手感;以项目验证架构和性能;以错题本减少重复错误;以模考训练时间;以合规方式参加考试;通过后继续积累工程经验。不要相信“背一套题就能掌握高级开发”,也不要因为大纲范围广就焦虑。把知识拆成模块,把模块放进项目,把
步骤1:基于TKernel创建算子工程创建算子描述文件,定义输入输出、属性及计算逻辑步骤2:编写算子实现代码在中实现自注意力计算的核心逻辑,利用昇腾矢量指令(如vaddvmul// 示例:自注意力QKV投影计算// 昇腾矢量指令加速矩阵乘法步骤3:编译与部署算子将编译生成的*.o文件注册到MindSpore算子库,完成自定义算子部署这是一张图片,ocr 内容为:优化效果实测。
文章摘要(145字) 本文系统总结了鸿蒙应用性能优化知识体系,涵盖启动、布局、列表、内存、动画、包体积、功耗7大领域。通过ROI分析指出最高效的优化策略:图片转WebP(收益5星/成本1星)、列表使用LazyForEach(4星/2星)、代码混淆(3星/1星)等Top10优化项。强调性能优化应遵循"发现→定位→优化→验证"的闭环流程,建立性能基线和文化。最后为"民族图鉴"项目提供可直接落地的优化C
本文主要探讨机器人开发中的性能优化策略。作者通过一个视觉伺服系统的案例,强调性能优化的核心原则:基于profiling数据而非猜测进行优化。介绍了Linux下的perf和FlameGraph等性能分析工具,并详细列举了从算法、数据结构到编译器优化的多层次优化手段(包括算法复杂度改进、缓存友好性处理、SIMD指令使用等)。文章特别指出,优化后必须进行量化对比验证,并提供了Google Benchma
虽然方案 4 在逻辑上"读了两遍表"(一次聚合 + 一次回查),但两遍扫描是并行分布在不同线程执行的,且第二遍扫描通过 Hash Join 的过滤条件大幅减少了有效数据量。方案 4 在第一阶段就将 1500 万行压缩为 2,355 个品种的最大 seq_no,第二阶段仅用这些 seq_no 精确回查,JOIN 后最多返回约 4,710 行。优先消除排序:对于 “取每组最大值对应行” 的场景,先用
摘要 昇腾 CANN 推出的 ATB(Ascend Transformer Boost)加速库专为 Transformer 算子优化设计,通过算子融合、内存调度等底层优化提升计算效率。ATB 位于 CANN 软件栈中间层,提供高性能算子实现,覆盖 Multi-Head Attention、LayerNorm、RoPE 等核心模块,相比传统 PyTorch 实现减少 40%-70% 执行时间。其特点
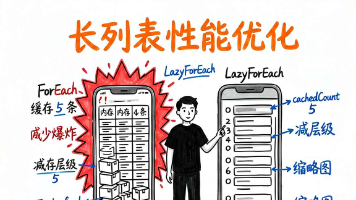
本文深入探讨了移动应用中列表性能优化的关键问题。列表作为最常见的界面形式,却常面临数据量大、滚动频繁、元素复杂和内存压力四大性能挑战。文章通过对比ForEach(全量渲染)和LazyForEach(懒加载)的核心差异,揭示了后者通过视口回收、组件复用和懒加载机制实现性能飞跃的原理。针对「民族图鉴」的56个民族列表场景,提供了具体优化方案选择建议,并系统讲解了列表项轻量化、复用机制、key的重要性等
本文摘要: 《民族图鉴》详情页的布局与渲染性能优化》深入解析了移动应用界面渲染的核心流程与优化策略。文章从渲染流程四阶段(布局→绘制→合成→提交)切入,重点讲解了重排(Reflow)与重绘(Repaint)的原理及性能影响,指出重排的递归特性会导致整棵组件树重新计算。针对常见性能问题如布局抖动、列表卡顿等,提出了层级优化、Flex布局改进、合理使用Span等解决方案,并结合实际案例演示如何减少60
本文深入解析了移动应用启动性能优化的关键问题与解决方案。主要内容包括: 启动性能的重要性:53%用户会放弃3秒以上加载的应用,启动速度直接影响用户留存。 三种启动形态: 冷启动(进程不存在,耗时最长) 温启动(进程存在但页面重建) 热启动(进程和页面都在) 启动流程分析: 系统阶段(进程创建、应用加载) 应用阶段(服务初始化、启动页加载、首页渲染) 优化重点: 冷启动是主要优化目标 启动页固定等待
本文摘要: 《性能优化入门指南》系统介绍了移动应用性能优化的核心知识体系。文章以「民族图鉴」App为例,从用户体验、业务指标和品牌形象三个维度阐述性能优化的重要性,指出性能直接影响用户留存率(页面加载3秒跳出率增加32%)、商业转化和产品品质感知。详细解析了六大核心性能指标:启动时间(冷/温/热启动)、流畅度(FPS、Jank率)、内存占用、CPU使用率、包体积和电量消耗,并给出各指标的优秀标准(
Scroll + List + ForEach/LazyForEach 构成了鸿蒙长列表性能优化的核心方案。Scroll 作为通用滚动容器,适合内容可控的场景;List 结合虚拟列表机制,专门针对大量列表数据优化。ForEach 适用于中等数据量,LazyForEach 更适合大数据量场景,其 IDataSource 接口提供了灵活的数据管理能力。在实际开发中,配合 stickyHeader、di
MCP协议为AI与数据库的深度融合铺平了道路。通过标准化的工具接口,AI应用能够安全、高效地操作数据库,将原本分散在多个工具中的操作整合到统一的对话界面中。对于开发人员,这意味着更流畅的SQL优化体验;对于DBA,这意味着更智能的运维辅助;对于企业,这意味着更高效的数据资产利用。在AI原生应用爆发的2025年,"AI直接操作数据库"不再是科幻场景,而是已经落地的技术现实。掌握MCP协议,就是掌握A
本文针对HarmonyOS应用开发中的图片加载性能优化问题,提出了一套分层解决方案。文章首先建议将图片按场景(头像、列表封面、详情大图等)分级处理,采用不同加载策略。核心优化措施包括:1)建立统一的图片请求模型;2)构建包含尺寸和场景的缓存key;3)设置内存缓存上限;4)智能预加载机制;5)完善的失败占位策略。文章还提供了详细的验证流程、常见问题排查方法和工程落地建议,强调通过请求模型、缓存管理
本文针对鸿蒙应用开发中的内存管理问题,特别是闭包陷阱与内存泄漏,提供了系统性的解决方案。文章首先介绍了HarmonyOS的ARC+GC混合内存管理机制,重点分析了闭包捕获导致的内存泄漏原理,并详细列举了6种典型内存泄漏类型及其修复方案。 在实战部分,文章深入探讨了异步回调、定时器、事件监听等常见场景下的内存管理问题,通过对比错误写法与安全写法,给出了具体代码示例。特别强调了在aboutToDisa
本文介绍了HarmonyOS应用长列表性能优化的实战方案。针对资讯流、商品流等常见长列表场景,提出了一套系统性的工程化解决方案,通过LazyForEach数据懒加载、分页加载和图片缓存治理等关键技术手段,有效解决滑动卡顿和内存上涨问题。 文章从问题拆解入手,指出长列表性能问题通常由多因素叠加造成,包括一次性加载过多数据、key不稳定、列表项过重、图片无缓存等。随后提出工程结构优化建议,将数据、渲染
本文针对AI Agent性能优化提出三步策略:1) 异步处理(流式返回与并发工具调用可降延迟50%+);2) 多级缓存(内存→磁盘→Redis三级缓存减少重复计算);3) 批处理(合并相似请求节省Token成本)。核心优化点在于LLM调用环节(占耗时60-80%),通过递进式技术组合(异步→缓存→批处理→连接池)实现QPS提升与成本控制。代码示例演示了流式响应、并行工具执行及缓存层级设计,强调独立
本文系统剖析了数据库高并发优化的全链路方案,从底层硬件到分布式架构逐层解析。首先指出硬件网卡、操作系统内核的TCP连接资源限制是高并发瓶颈的根源,详细分析了无连接池场景下频繁TCP握手/挥手的性能损耗。接着深入MySQL单机优化,提出连接池复用、SQL语句优化等核心手段。然后引入Redis缓存分层架构,详解缓存更新策略、内存淘汰机制及穿透/雪崩等问题的解决方案。最后给出分布式扩容方案,包括读写分离
本文针对HarmonyOS应用冷启动优化提出具体解决方案,通过任务拆解和性能分析工具实现首屏加速。文章明确了官方参考文档,建议将冷启动过程分为五个阶段:轻量级进程初始化、窗口创建、首屏渲染、非关键任务延后执行和性能复测。推荐采用模块化工程结构,分离启动职责,入口Ability仅处理窗口创建等核心任务,其他业务初始化通过StartupCoordinator统一管理。关键原则是:首屏必要任务同步执行且
在鸿蒙生态规模化落地的当下,应用的流畅度与多端一致性直接决定用户体验。ArkUI 作为 HarmonyOS 应用开发的核心 UI 框架,其性能表现是应用质量的核心指标。HarmonyOS 5.0 针对 ArkUI 新增了增量渲染、细粒度状态监听、跨端自适应组件等多项能力,但多数开发者仍停留在 “功能实现” 层面,未能充分释放框架性能红利。本文结合笔者多年鸿蒙应用开发实战经验,从底层原理到上层实操,
道本科技合规数知法用法平台,利用大数据与人工智能技术,采用“AI事项查法”技术,允许企业在不清楚具体法规的情况下,直接输入相关事项,快速获取数字化结果。正是在这样的背景下,天津市道本科技有限公司——一家成立于2008年、深耕企业法务合规数字化建设领域的国家高新技术企业——打造出覆盖“合规管理—合同风控—法务数智化”的一体化解决方案。从金融业的监管数据报送,到制造业的合同履约管控,从反洗钱到数据安全
多智能体系统(Multi-Agent System)是由多个自治智能体组成的协作框架,通过任务分配和协调机制解决复杂问题。其核心原理是将不同能力的AI模型视为独立智能体,利用各自优势实现整体效能优化。在AI工程实践中,这种架构能显著提升技术价值,特别是在平衡性能与成本方面表现出色。应用场景涵盖代码开发、内容创作、数据分析等领域,其中Claude团队提出的Advisor模式和Orchestrator
在软件开发领域,代码优化是提升程序性能的关键技术,涉及算法复杂度分析、内存管理和并发编程等多个层面。其核心原理在于通过识别性能瓶颈并应用针对性改进,减少资源消耗并提高执行效率。从技术价值看,优化能显著改善用户体验、降低服务器成本并增强系统可扩展性。在游戏开发、高频交易和嵌入式系统等对性能敏感的场景中尤为关键。本文聚焦C++语言,结合AI辅助工具,探讨基于模式识别的代码转换、算法选择优化、编译期计算
AI Agent作为人工智能领域的重要演进,其核心在于通过大语言模型(LLM)赋予系统自主规划、工具调用与任务执行的能力。其工作原理通常遵循感知-规划-执行-反思的认知循环,技术价值在于将传统自动化提升至具备认知与决策能力的智能水平,广泛应用于流程自动化、智能客服、数据分析等场景。本文聚焦于构建高可用、高性能的生产级AI Agent平台,深入探讨了其核心架构范式,包括垂直、水平与混合协作模型,并详
本文深入分析了ChatGPT界面变慢或卡顿的六大原因,包括网络延迟、服务器过载、模型推理时间、客户端问题等,并提供了优化使用体验的实用技巧。通过实测数据和专业解释,帮助用户理解AI交互中的性能瓶颈,提升ChatGPT的使用效率。
AI编程助手作为现代开发流程中的智能协作工具,其核心原理基于强化学习与上下文感知技术。通过建立清晰的权限结构和渐进式训练体系,开发者可以显著提升AI助手的代码生成质量与响应效率。在工程实践中,合理配置记忆管理系统和奖惩机制能够优化资源利用率,降低错误传播率。特别是在持续集成、自动化测试等DevOps场景中,经过深度调教的AI编程助手可以成为提升研发效能的关键组件。本文以GitHub明星项目Open
在AI工程实践中,模型推理性能与内存管理是影响系统稳定性的关键因素。通过流式输出、混合精度推理等技术可显著提升响应速度,而会话生命周期管理和插件沙箱机制则能有效控制内存占用。这些优化手段在金融客服等实时交互场景中尤为重要,例如OpenClaw系统经过调优后响应时间提升7倍、内存占用降低73%。针对生产环境中的卡顿和OOM问题,本文提供了从模型选型到监控告警的全链路解决方案。
列表是性能重灾区。一个聊天记录几千条、商品列表无限滚动——如果用错方式,轻则滑动卡顿,重则内存爆炸直接崩。我做过不少列表优化,这篇文章把最实用的几招讲清楚:用懒加载、控制单次渲染量、复用组件、减少布局层级。照着做,列表丝滑起来。LazyForEach 懒加载、cachedCount 加缓冲、布局减层级、图片用缩略。其中 LazyForEach 是性价比最高的一招,几乎所有长列表卡顿,第一步都是换它
从 Jetpack Compose 到 CMP,声明式 UI 在 KMP 全栈中的局部性体现为 commonMain共享 +局部适配;性能优化则需针对平台渲染差异、状态重组与内存模型(尤其 iOS/Native)采取分层治理。合理运用上述策略,可在保持高代码复用率(UI 达 70%–90%)的同时,逼近原生体验。
在上一篇文章中,我们实现了编辑记录本地存储功能,通过Preferences将用户的每一步编辑操作(包括滤镜、缩放、裁剪等)持久化保存,用户可以在“历史记录”页面浏览和恢复之前的编辑状态。核心代码实现了单例,它封装了和put方法,确保每次编辑操作都被记录为一个包含操作类型、参数和时间戳的JSON对象。虽然功能已经趋于完整,但我在测试过程中发现了一个严重问题:当连续编辑多张大图(如4000x3000像
【摘要】本文深入讲解RK3588S三核NPU的多线程推理优化。揭示默认单实例只用一个核心的根本原因,提出两大策略:1)单模型三核并发,通过rknn_set_core_mask设置RKNN_NPU_CORE_0_1_2,单次推理延迟降低约40%;2)多模型多实例并发,三线程各绑一核,三路视频总吞吐提升3倍。给出完整的生产级C++多线程推理框架代码,含任务队列、条件变量同步、回调式异步API用法。附r
生产级Agent应用实战指南:架构设计与优化策略 本文全面剖析了从Demo到生产级Agent应用的转变过程,提供了完整的架构设计方案和优化策略。 核心要点: 生产级架构设计:采用分层架构(接入层、应用层、能力层、基础设施层),确保系统的扩展性、稳定性和可观测性 性能优化六大招:包括流式输出、语义缓存、模型路由、并行工具调用等关键技术,显著提升响应速度 成本控制策略:通过模型分级、语义缓存、Prom
本文探讨了在骁龙X2 Elite平台上优化大模型推理的系统级技术,重点介绍了异构协同推理架构。通过高通AI引擎调度器,将计算密集型算子(如矩阵乘法)分配给NPU,控制密集型算子(如Softmax、KV Cache管理)分配给CPU,实现高效协同。文章还概述了流式推理、KV Cache优化、内存管理等关键技术,并提供了Transformer层的异构算子分配代码示例,展示了如何在不同计算引擎间分配任务
Per-token量化python# SGLang启用RadixAttentionimport sglang as sglbackend = sgl.Runtime( model_path="meta-llama/Llama-4-70B", enable_prefix_caching=True, # 关键 chunked_prefill_size=4096,)# 多请求共享前缀prompts =
在人工智能飞速发展的当下,用户获取信息的方式发生了巨大转变,GEO优化应运而生。陕西维度引擎科技作为专注此领域的平台,其效果备受关注。
性能优化
——性能优化
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台






 DAMO开发者矩阵
DAMO开发者矩阵


 华为开发者空间
华为开发者空间

 HarmonyOS开发者社区
HarmonyOS开发者社区





 MCP技术社区
MCP技术社区





 智能体开发者社区
智能体开发者社区
 openEuler 社区
openEuler 社区


 EazyDevelop社区
EazyDevelop社区
 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AI Agent技术社区
AI Agent技术社区





 AMD开发者中国社区
AMD开发者中国社区






