- @m0_47256162
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
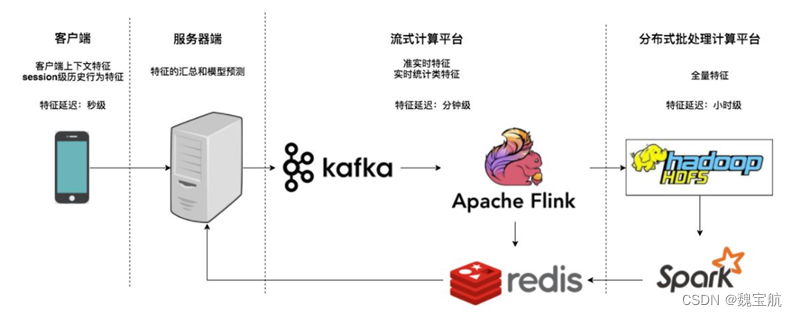
所谓流处理平台,是将日志以流的形式进行mini batch处理的准实时计算平台,流处理平台计算出的特征可以立马存入特征数据库供推荐系统模型使用,虽然无法实时的根据用户行为改变用户结果,但分钟级别的延迟基本可以保证用户的推荐结果准实时地受到之前行为的影响。...
2021-12-27 17:45:07.871890: W tensorflow/core/data/root_dataset.cc:167] Optimization loop failed: Cancelled: Operation was cancelled2021-12-27 17:45:07.877953: W tensorflow/core/data/root_dataset.cc:1
这个目录,然后进入上面的卷目录即可。查看当前目录,可以看到出现了。运行该指令后,会进入一个新的。进行卷映射时,我们使用。可以看到卷的存储位置在。

CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。当我们在进行深度学习任务时,我们有时需要使用GPU版本的框架,比如tensorflow-gpu或者mindspore-gpu版本就需要安装CUDA和CUDNN进行GPU加速支持1.下载cu
中国软件开源创新大赛·赛道二:任务挑战赛(模型王者挑战赛黄金赛段)论文:EfficientNetV2: Smaller Models and Faster TrainingPaper地址:EfficientNetV2: Smaller Models and Faster Training数据集:CIFAR-10精度基线:Percentage correct:90%论文:EfficientNetV

在Maven工程的.pom经常出现依赖代码大批发黄。

如果需要完整代码可以关注下方公众号,后台回复“代码”即可获取,阿光期待着您的光临~文章目录2021人工智能领域新星创作者,带你从入门到精通,该博客每天更新,逐渐完善推荐系统各个知识体系的文章,帮助大家更高效学习。在CRT预估中,工业界一般是会采用逻辑回归进行处理,对用户特征画像进行建模,然后计算点击概率,评估用户是否会有点击的行为。但是逻辑回归这个算法天生就会有个缺陷,它不能够区分非线性的数据,原

这个目录,然后进入上面的卷目录即可。查看当前目录,可以看到出现了。运行该指令后,会进入一个新的。进行卷映射时,我们使用。可以看到卷的存储位置在。
在开发过程中,我的应用程序直接运行在本地,可以通过localhost顺利访问Docker容器中的MySQL和Redis服务(做了端口映射)。然而,当我将应用程序也打包部署到Docker中后,发现应用程序无法再访问这些数据库和缓存服务,提示拒绝连接。

从该结果可以看出这个数据集的节点特征矩阵的维度为【19580,3】,代表这个数据集(600张图一共)有19580个节点,每个节点的特征维度为3,共有74564条边,这些数据并不是一个图的,而是ENZYMES600张图加起来一共的。ENZYMES数据集是在GNN领域是非常经典的数据集,它是一个根据生物分子蛋白质结构而构建的Graph数据集合,总共600个图,也就是对应600个样本(蛋白质分子) ,共