




- @2401_85373898
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文讲述了AI从传统语言模型(LLM)向AI Agent的革命性转变。LLM只能输出信息不能执行操作,而AI Agent通过记忆、使用工具和目标驱动能力,能够实际完成任务。MCP作为AI Agent与外部世界交互的"翻译官",解决了不同API接口的标准化问题。Agent to Agent协作模型实现了专业分工,大幅提升效率。2025年将是AI Agent和MCP的落地年,这不仅是技术升级,更是工作
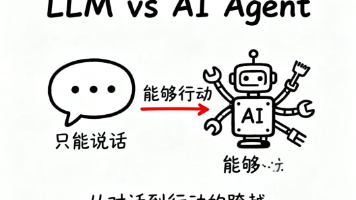
未来不在于选择其一。而在于将三者结合起来进行架构设计。用于思考的 LLMs。用于认知的 RAG。用于执行的Agent。由此才能够构建出AI智能时代。
开年至今,OpenClaw的热度愈演愈烈,「养龙虾」潮从AI圈扩散至各行各业。在GitHub上,OpenClaw突破250K+的Star,成为了GitHub上面获星最多的软件项目。社交媒体上,用OpenClaw开「一人公司」、靠OpenClaw日入斗金的消息被不断转发,仿佛2026年的财富密码就藏在这儿。不同于豆包代表的Chatbot,OpenClaw是一套可本地运行、开源免费的AI Agent框
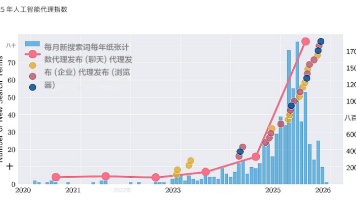
这份指数在1350 个维度上记录了 30 个代理系统,但更重要的,是它揭示了三个结构趋势:第一,安全披露高度不均。仅有极少数代理发布针对自身架构的系统卡片。大多数系统要么只披露基础模型信息,要么只强调合规认证。能力基准与安全评估之间存在明显不对称。当代理风险越来越多地来自规划能力与工具调用,而不仅是模型输出时,仅依赖模型层面的文档已不足够。第二,基础模型高度集中。几乎所有代理都依赖GPT、Clau
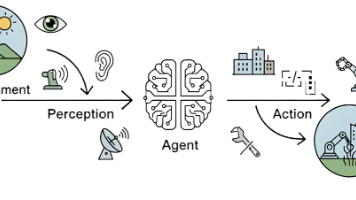
要理解智能体的运作,我们必须先理解它所处的任务环境。在人工智能领域,通常使用PEAS模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)。以上文提到的智能旅行助手为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。表 1.2 智能旅行助手的PEAS描述在实践中,LLM智能体所处的数
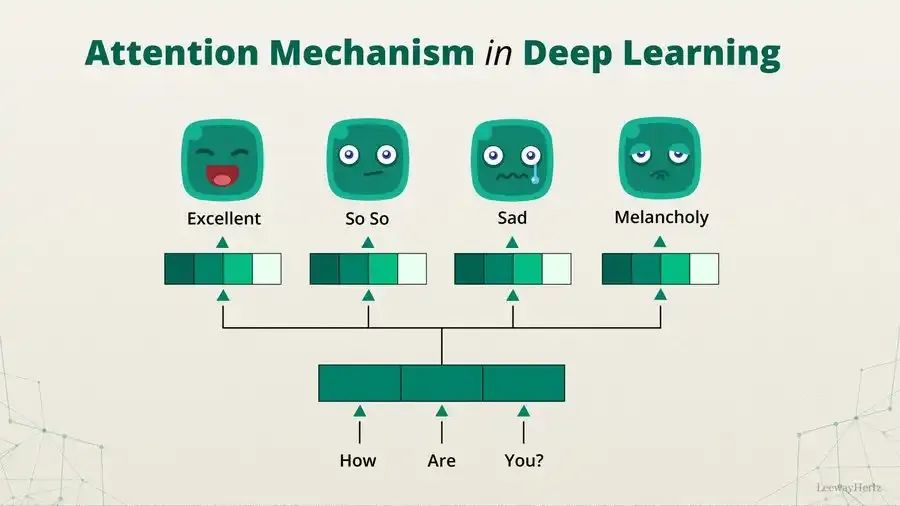
在深度学习中,注意力机制模仿了人类在处理信息时的选择性关注能力**,允许模型在处理输入数据时动态地调整其注意力权重,从而突出重要信息并忽略不重要的信息。****注意力机制通过计算****查询向量(Query)、键向量(Key)之间的相似度来确定注意力权重,然后对值向量(Value)**进行加权求和,得到最终的输出。Attention Mechanism一、注意力机制什么是注意力机制**(Atten
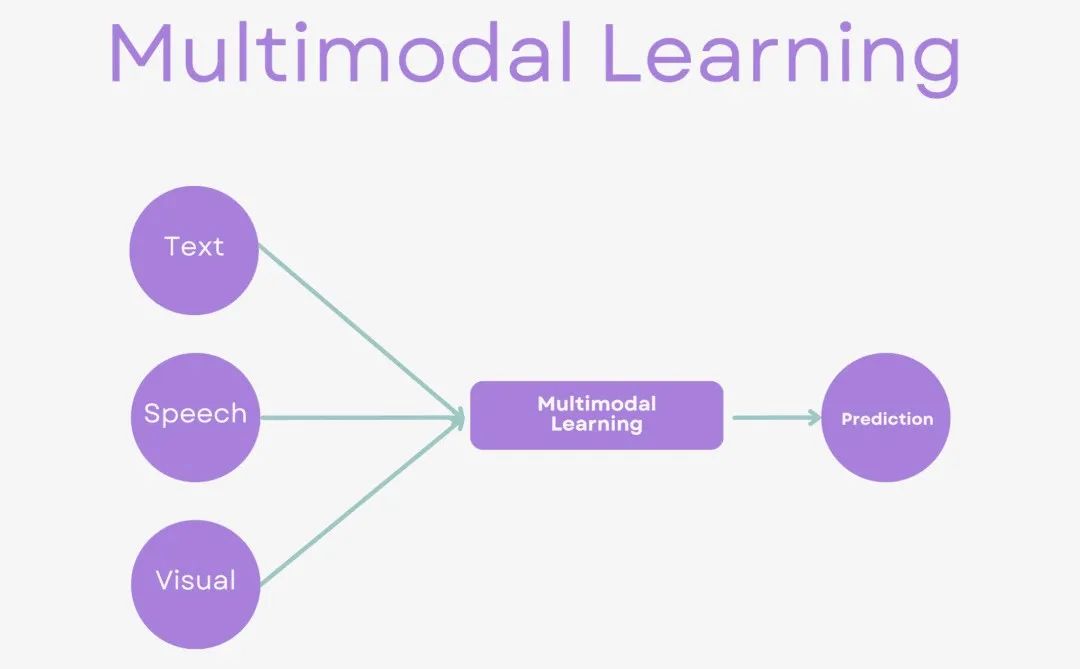
直接建立不同模态之间的对应关系,包括无监督对齐和监督对齐。无监督对齐利用数据自身特性自动发现模态间对应关系,如CCA和自编码器;监督对齐则利用标签信息指导对齐,如多模态嵌入和多任务学习模型。不直接建立对应关系,而是通过模型内部机制隐式地实现跨模态的对齐。这包括注意力对齐和语义对齐。一、注意力对齐通过注意力机制动态地生成不同模态之间的权重向量,实现跨模态信息的加权融合和对齐。
先给结论再说理由:数据分析师、AI大模型工程师、产品经理和云计算工程师。这些领域不仅因应了当前技术发展的趋势,也为程序员提供了转型的广阔舞台和职业发展的新机遇。一起来看看吧!数据分析师:数据驱动决策的关键程序员转行时,应考虑当前市场上的热门行业和岗位需求。例如,AI大模型工程师、数据分析师、前端开发工程师、全栈开发工程师等都是当前市场上需求量较大的职位。就拿数据分析师来说,因其在商业决策中的关键作
2025 年标志着人工智能(AI)发展的一个关键拐点,AI 智能体(Agent)正从前几年的实验性原型(如 AutoGPT)演变为企业战略与核心产品的基石。随着大模型技术的逐渐成熟,市场对人工智能的能力需求已从单纯的 “内容问答” 转向要解决 “实际任务”。AI 智能体作为能够自主理解意图、规划步骤、调用工具并执行复杂任务的新一代人工智能应用范式,正在成为全球科技巨头和创业公司竞相布局的战略高地。
若用户请求检测的类别(如特定花卉或新型电子设备)超出检测器的识别能力,那么无论视觉语言模型如何进行推理修正都无济于事——因为现有流程仅将 VLM 用于对初始检测结果的审核与优化。由于视觉语言模型(VLM)能审阅整个带箭头标注的图像,并理解每个杯身印刷的文字内容,它能自动过滤无关的杯子,仅保留符合查询要求的预测结果。至此,我们已完成首个关键环节的实现:通过识别查询语句中的目标对象,将其标准化并预处理
