




- @qq_35054151
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
keras支持模型多输入多输出,本文记录多输出时loss、loss weight和metrics的设置方式。模型输出假设模型具有多个输出classify: 二维数组,分类softmax输出,需要配置交叉熵损失segmentation:与输入同尺寸map,sigmoid输出,需要配置二分类损失others:自定义其他输出,需要自定义损失具体配置model变量均为模型中网络层123inputs = [
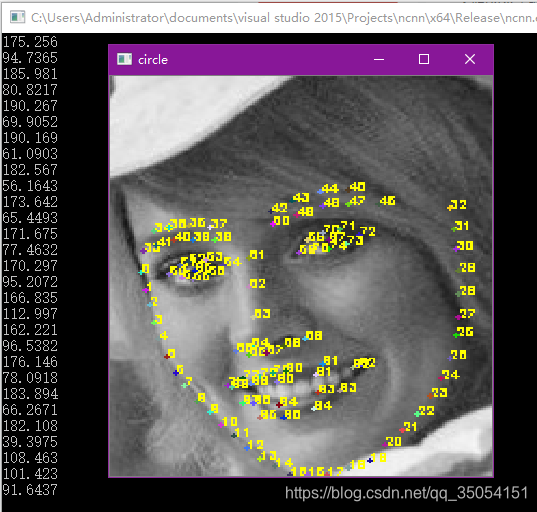
1. 代码:https://github.com/polarisZhao/PFLD-pytorch2 环境:torchvision==0.4.0numpy==1.17.2torch==1.2.0opencv_python==4.1.0.25tensorboardX==1.8onnx-simplifier3.#include <opencv2\opencv.hpp>#include &l
1.CNN的特点以及优势改变全连接为局部连接,这是由于图片的特殊性造成的(图像的一部分的统计特性与其他部分是一样的),通过局部连接和参数共享大范围的减少参数值。可以通过使用多个filter来提取图片的不同特征(多卷积核)。CNN使用范围是具有局部空间相关性的数据,比如图像,自然语言,语音1.局部连接:可以提取局部特征。2.权值共享:减少参数数量,因此降低训练难度(空间、时间消耗都少了)。3.可以完
加州大学欧文分校的这项研究,让我们更期待未来更先进的彩色夜视仪。其实是很容易想到的图像增强手段,在一些军事大片中,士兵头戴夜视仪搜索前进似乎是少不了的场景。使用红外光在黑夜中观察的夜视系统通常将视物渲染成单色图像。图源:flir.com不过,在最近的一项研究中,加州大学欧文分校的科学家们借助深度学习 AI 技术设计了一新方法,有了这种方法,红外视觉有助于在无光条件下看到场景中的可见颜色。研究共同一
量化是将数值 x 映射到 y 的过程,其中 x 的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)。8-bit 低精度推理,是将一个原本 FP32 的浮点张量转化成一个 int8/uint8 张量来处理。先看一下浮点数和 8-bit 整数的完整表示范围。模型量化会带来如下两方面的好处:减少内存带宽和存储空间深度学习模型主要是记录每个 layer(比如卷积层/全连接层
二维卷积:操作二维卷积是一个相当简单的操作:从卷积核开始,这是一个小的权值矩阵。这个卷积核在 2 维输入数据上「滑动」,对当前输入的部分元素进行矩阵乘法,然后将结果汇为单个输出像素。一个标准的卷积卷积核重复这个过程知道遍历了整张图片,将一个二维矩阵转换为另一个二维矩阵。输出特征实质上是在输入数据相同位置上的加权和(权值是卷积核本身的值)。输入数据是否落入这个「大致相似区域」,直接决定了数据经过卷积
吴恩达在推特上展示了一份由 TessFerrandez 完成的深度学习专项课程信息图,这套信息图优美地记录了深度学习课程的知识与亮点。因此它不仅仅适合初学者了解深度学习,还适合机器学习从业者和研究者复习基本概念。这不仅仅是一份课程笔记,同时还是一套信息图与备忘录。深度学习基础1. 深度学习基本概念监督学习:所有输入数据都有确定的对应输出数据,在各种网络架构中,输入数据和输出数据的节点层都位于网络的
在工地现场,对于进场的钢筋车,验收人员需要对车上的钢筋进行现场人工点根,确认数量后钢筋车才能完成进场卸货。目前现场采用人工计数的方式,如图1-1中所示:图1-1 钢筋点跟现场场景上述过程繁琐、消耗人力且速度很慢(一般一车钢筋需要半小时,一次进场盘点需数个小时)。针对上述问题,希望通过手机拍照->目标检测计数->人工修改少量误检的方式(如图1-2)智能、高效的完成此任务:主要难点:(Ma
一:polygon2bbox二:maskImg2json三.保存四边形矩形框bbox标注信息四.保存不规则边框polygon标注信息五:将labelImg标注的xml BBox文件转成json文件六:voc中txt格式的,也转为json格式七:labelme标注的json文件,打印到原图image上八:labelme的json数据转换成coco数据读取所需的json文件前言:在做视觉图像处理中,尤
将图像或影片从低分辨率转化为高分辨率,恢复或补足丢失的细节(即高频信息),往往需要用到超分辨率技术。根据所用低分辨率图像的数量,超分辨率技术可分为单幅图像的超分辨率 (SISR) 和多幅图像的超分辨率 (MISR)。网友用 AI 技术给视频上色、插帧恢复了 1920 年北京市民生活记录影像SISR 利用一张低分辨率图像,达到图像尺寸增大或像素的增加的效果,从而获得一张高分辨率图像。MISR 则是借