
用Python+Ollama轻松微调大模型(图文详解)零基础入门到Ollama本地部署,收藏这篇就够了!
想象一下,你请了个世界级大厨,他啥菜都会做,但还得学会你家的独门菜谱。你不用从头教他做饭,只需要给他看几道你的菜就行。这就是微调!微调是拿一个已经预训练好的 LLM(比如 GPT 或 Llama),它已经很懂得通用语言了,然后针对你的特定任务“调校”一下。你给它喂一些你领域的例子,它就会调整自己的知识,专门为这个领域发光发热。它咋工作的?从一个懂得英语(或其他语言)的 base model 开始,
文章详细介绍了使用Python微调大型语言模型(LLM)并在本地通过Ollama运行的完整流程。从微调概念、适用场景到具体步骤(数据收集、环境设置、模型训练、测试推理、部署),使用Unsloth工具和Google Colab免费GPU,以Phi-3 Mini为例,帮助读者打造针对特定任务的定制化模型,无需高端硬件。
作为一名对 AI 和机器学习充满热情的人,我花了不少时间研究怎么让强大的语言模型更好地完成特定任务。今天,我想分享一份详细的指南,教你如何用 Python 微调 LLM(大型语言模型),然后用 Ollama 这个工具在本地运行微调后的模型。这份指南基于我看到的一个实际操作教程,但我会加上详细的解释和例子,让它更全面、更适合新手

什么是 LLM 微调?
想象一下,你请了个世界级大厨,他啥菜都会做,但还得学会你家的独门菜谱。你不用从头教他做饭,只需要给他看几道你的菜就行。这就是微调!
微调是拿一个已经预训练好的 LLM(比如 GPT 或 Llama),它已经很懂得通用语言了,然后针对你的特定任务“调校”一下。你给它喂一些你领域的例子,它就会调整自己的知识,专门为这个领域发光发热。
它咋工作的?
从一个懂得英语(或其他语言)的 base model 开始,给它一堆“输入”(比如一个问题)和“输出”(比如完美答案)的配对。模型会调整内部 weights 来匹配这些例子。
跟 prompting 的区别?
Prompting 就像临时给指令(比如“写得像莎士比亚”),而微调是永久改变模型,让它表现更稳定。
跟 parameter tuning 的区别?
Parameter tuning 是调整像“temperature”(输出多有创意)这样的设置,就像调车上的收音机。微调则是给引擎升级,让它能跑越野。
举个例子:
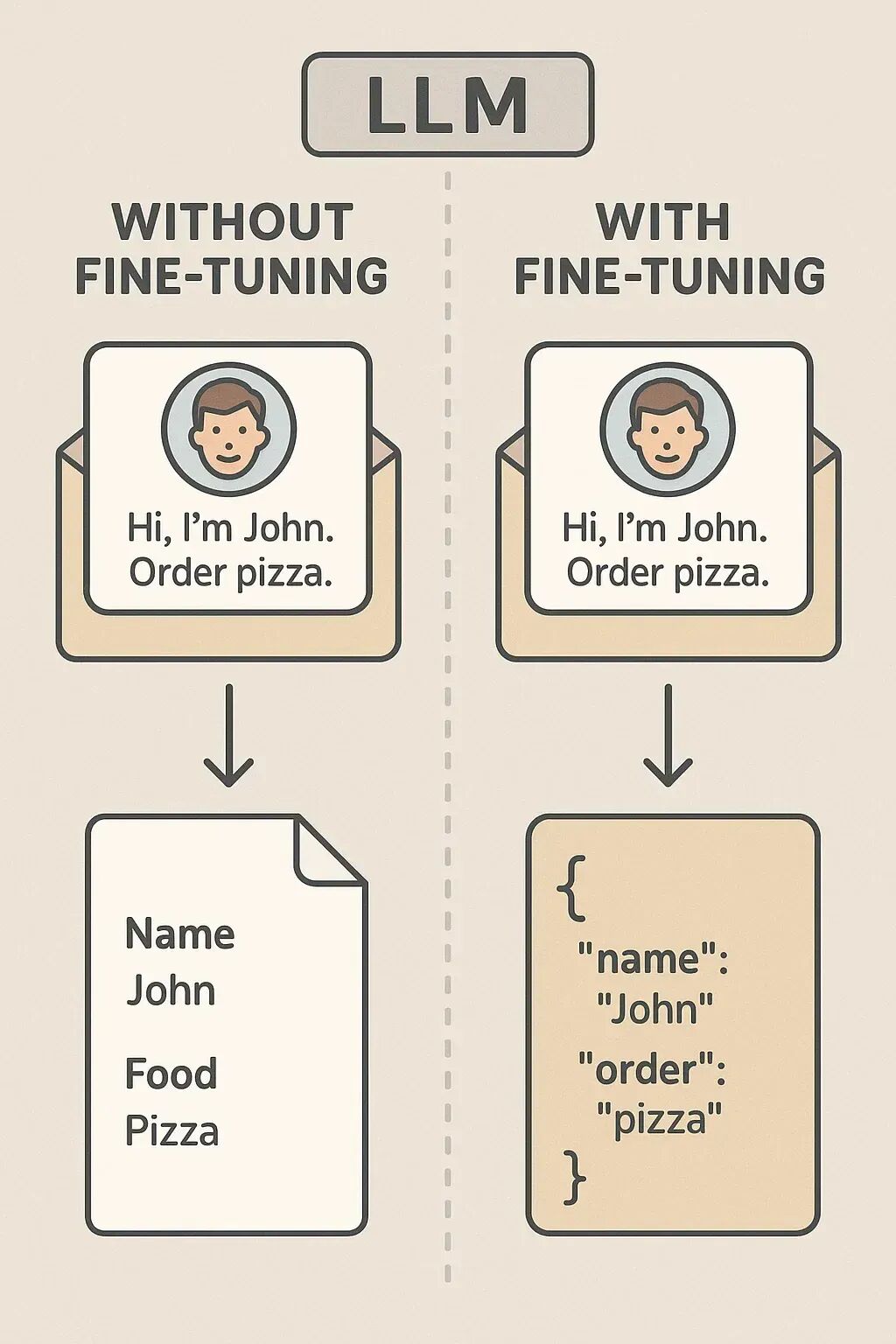
假设你想让 LLM 从乱糟糟的邮件里提取信息。
没微调前:
Prompt: “从‘嗨,我是 John。订个披萨。’中提取名字和订单。”
输出:可能很随机,比如“Name: John, Food: Pizza”或者只是个总结。
微调后:
用 100 封邮件例子训练。现在它总会输出 JSON 格式:{"name": "John", "order": "pizza"}。
什么时候需要微调 LLM?
别啥都微调,这就像买跑车去买菜,得看情况用:
- • 需要一致的格式/风格: Prompting 搞不定严格的输出,比如 JSON 或法律文档。
- • 领域专属数据: 模型没见过你的小众领域(比如医学术语或公司日志)。
- • 省钱: 用一个小的、微调过的模型,替代像 GPT-4 这样的大模型。

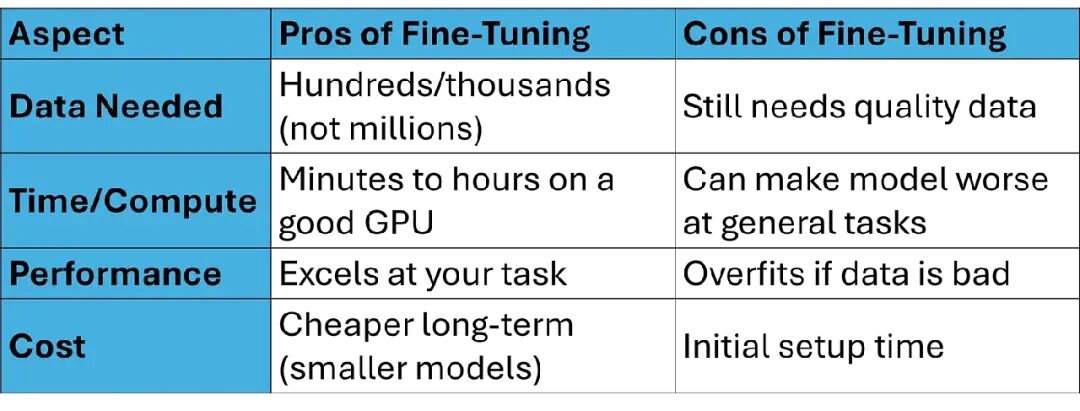
优点和缺点:
微调的替代方案:
- • Prompt Engineering: 快又免费,但不稳定。
- • Retrieval-Augmented Generation (RAG): 实时加外部数据(比如先搜文档再回答)。
- • 从头训练: 只有像 OpenAI 这样的大公司才玩得起,需要海量数据和算力。
微调 LLM 的完整步骤
下面是全流程。我们会用 Unsloth(一个免费、开源、快速微调工具)和 Google Colab(免费的云端 GPU,不用高端硬件)。Base model 用 Phi-3 Mini(又小又快)。
流程图:

步骤 1:收集数据
这步很关键,垃圾数据 = 垃圾模型。需要 JSON 格式的输入-输出配对。
示例数据集(用于 HTML 提取,比如从网页代码里提取产品信息):
文件: extraction_dataset.json
内容(简化版,500 个例子中的 2 个):
[
{
"input":"<div><h2>Product: Laptop</h2><p>Price: $999</p><span>Category: Electronics</span><span>Manufacturer: Dell</span></div>",
"output":{"name":"Laptop","price":"$999","category":"Electronics","manufacturer":"Dell"}
},
{
"input":"<div><h2>Product: Book</h2><p>Price: $20</p><span>Category: Literature</span><span>Manufacturer: Penguin</span></div>",
"output":{"name":"Book","price":"$20","category":"Literature","manufacturer":"Penguin"}
}
]
小贴士: 如果需要,可以用 AI 生成数据,但最好用真实数据,效果更佳。
步骤 2:设置环境
用 Google Colab 来用免费 GPU。
- • 打开 Colab:去
colab.research.google.com。 - • 上传你的 JSON 文件。
- • 连接 T4 GPU:Runtime > Change runtime type > T4 GPU。
- • 安装依赖(在 Colab cell 里跑):
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps xformers "trl<0.9.0" peft accelerate bitsandbytes
输出: 安装包(大概 2 分钟)。如果提示,重启 runtime。
检查 GPU:
import torch
print(torch.cuda.is_available()) # 应该输出:True
print(torch.cuda.get_device_name(0)) # 比如 Tesla T4
步骤 3:加载模型
选一个 base model(比如 Phi-3 Mini)。
代码:
from unsloth import FastLanguageModel
model_name = "unsloth/Phi-3-mini-4k-instruct"
max_seq_length = 2048# 根据需要调整
model, tokenizer = FastLanguageModel.from_pretrained(
model_name,
max_seq_length=max_seq_length,
load_in_4bit=True
)
输出: 下载模型(小型模型大概 5-10 分钟)。
步骤 4:预处理数据
把输入格式化成单一字符串。
代码:
import json
from datasets import Dataset
# 加载数据
withopen("extraction_dataset.json", "r") as f:
data = json.load(f)
# 格式化函数
defformat_prompt(item):
returnf"{item['input']}\n{json.dumps(item['output'])}<|endoftext|>"
# 创建格式化列表
formatted_data = [{"text": format_prompt(item)} for item in data]
dataset = Dataset.from_list(formatted_data)
# 打印示例
print(formatted_data[0]["text"])
输出示例:
<div><h2>Product: Laptop</h2><p>Price: $999</p><span>Category: Electronics</span><span>Manufacturer: Dell</span></div>
{"name": "Laptop", "price": "$999", "category": "Electronics", "manufacturer": "Dell"}<|endoftext|>
步骤 5:添加 LoRA Adapters
LoRA 让微调更高效(只训练一小部分)。
代码:
model = FastLanguageModel.get_peft_model(
model,
r=16, # Rank
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407
)
输出: “Unsloth: Patched 32 layers…”(很快)。
LoRA 是什么?
Low-Rank Adaptation:给模型加“侧挂”层,只训练 ~1% 的参数,省时间和内存。
步骤 6:训练模型
用 SFTTrainer 训练。
代码:
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=60, # 调整以训练更多
learning_rate=2e-4,
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
trainer.train()
输出: 进度条显示 loss 下降(500 个例子大概 10 分钟)。
步骤 7:测试推理
跑个快速测试。
代码:
FastLanguageModel.for_inference(model)
messages = [{"role": "user", "content": "<div><h2>Product: Phone</h2><p>Price: $500</p><span>Category: Gadgets</span><span>Manufacturer: Apple</span></div>"}]
inputs = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=256, use_cache=True)
print(tokenizer.batch_decode(outputs)[0])
输出:
User: <div><h2>Product: Phone</h2><p>Price: $500</p><span>Category: Gadgets</span><span>Manufacturer: Apple</span></div>
Assistant: {"name": "Phone", "price": "$500", "category": "Gadgets", "manufacturer": "Apple"}
如果结果不稳定,多训练几次!
步骤 8:导出到 GGUF 格式给 Ollama
保存成 Ollama 支持的格式。
代码:
model.save_pretrained_gguf("fine_tuned_model", tokenizer, quantization_method="q4_k_m")
然后下载:在 Colab 文件里右键 > 下载(10-20 分钟)。
步骤 9:为 Ollama 创建 Modelfile
安装 Ollama(去 ollama.com)。
在终端:
cd ~/Downloads
mkdir ollama-test
mv unsloth.Q4_K_M.gguf ollama-test/
cd ollama-test
touch Modelfile
nano Modelfile # 粘贴以下内容
Modelfile 内容:
FROM ./unsloth.Q4_K_M.gguf
PARAMETER temperature 0.8
PARAMETER top_p 0.9
PARAMETER stop "<|endoftext|>"
TEMPLATE "{{ .Prompt }}"
SYSTEM "You are a helpful AI assistant."
创建模型:
ollama create html-extractor -f Modelfile
###¥ 步骤 10:在 Ollama 中运行
ollama run html-extractor
Prompt: 粘贴 HTML 示例。
输出: 提取的 JSON(本地运行,隐私安全!)。
最佳实践和常见问题
- • 数据质量: 用多样化的例子,防止 overfitting。
- • 评估: 用没见过的数据测试。
- • 扩展: 用更大的模型(比如 Llama 3.1)效果更好。
- • 常见问题: 数据集太小会导致“hallucinations”,多加数据!
微调的伦理问题
- • 避免偏见数据(比如用多样化的数据源训练)。
- • 隐私:用匿名数据进行微调。
总结
微调 LLM 就像给你的 AI 项目加了个超级技能,把通用工具变成专属专家!按照这篇指南的简单步骤——收集好数据、设置环境、用 Unsloth 训练、用 Ollama 部署,你就能打造出精准、一致的定制模型,满足你的独特任务需求。不管是从 HTML 提取数据、写小众客服回复,还是解决领域专属难题,微调让新手也能轻松上手!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)