- @2201_75571291
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
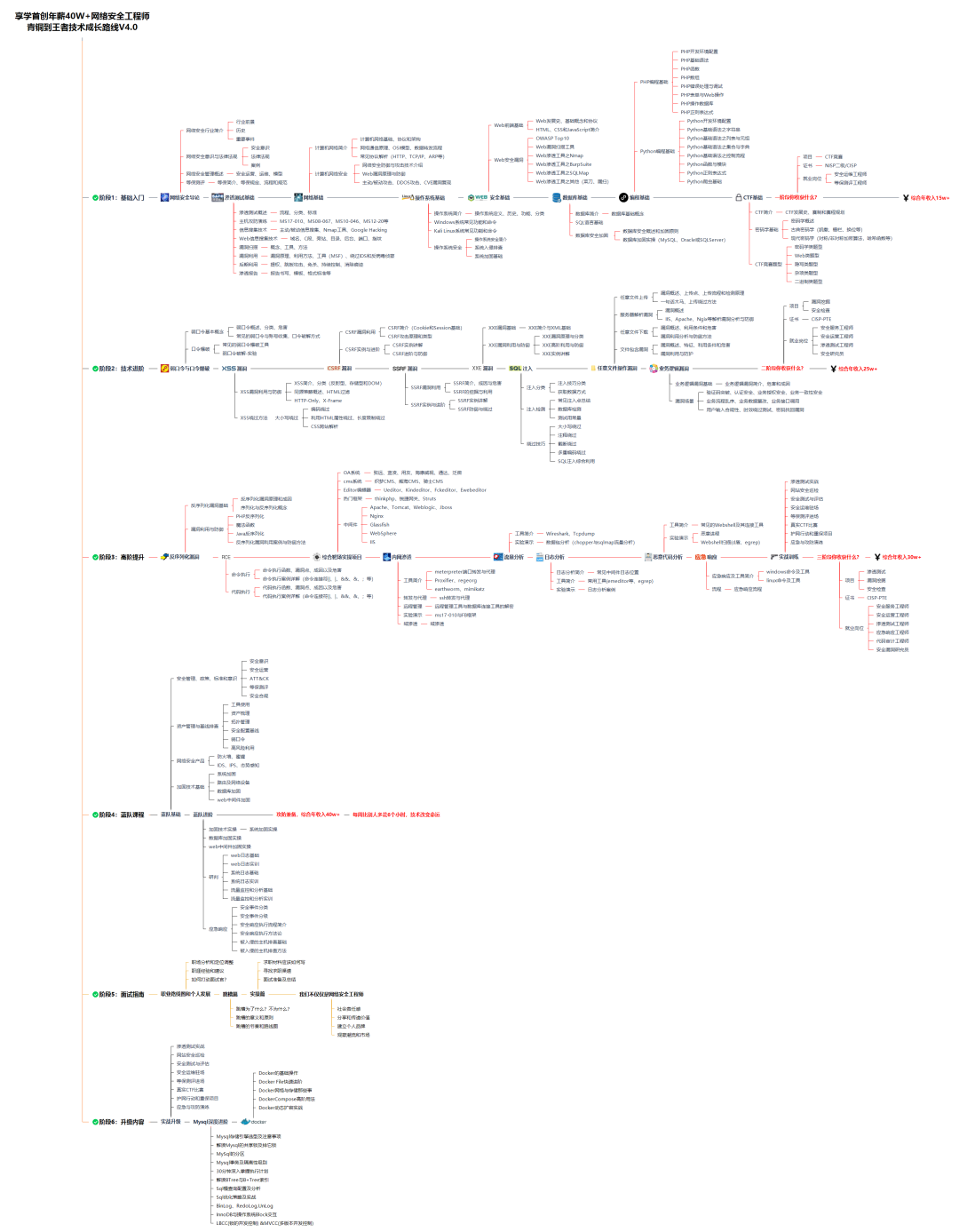
1、渗透测试是一个渐进的并且逐步深入的过程,由浅入深,一步一步的刺向目标的心脏,就是所谓的夺取靶机。2、渗透测试一方面从攻击者的角度,检验业务系统的安全防护措施是否有效,各项安全策略是否得到惯切实施,另一方面渗透测试会将潜在的安全风险以真实事件的方式凸显出来,渗透测试结束后,编写渗透测试报告反馈给客户,立即进行安全加固,解决测试发现的安全问题。这个过程包括对系统的任何弱点、技术缺陷或漏洞的主动的主
5步快速学习数据分析,Python入门完整学习流程!

Python数据可视化,完整版实操指南 !闭眼入!!
后,及时修补漏洞访谈MySQL补丁升级机制,查看补丁安装情况:1)执行如下命令查看当前补于版本:[外链图片转存中…(img-f4MnkHDM-1690167722785)]2)访谈数据库是否为企业版,是否定期进行漏洞扫描,针对高风险漏洞是否评估补丁并经测试后再进行安装。
在Python中,我们使用def函数来实现一个自定义函数。例如,如果我们要定义一个两数相加的函数,如下即可:# OUTPUT4顺便说一下,Python中的缩进是很重要的。通过缩进来定义函数作用域,就像在R语言中使用大括号{…}一样。这有一个我们之前博文的例子:产生10个正态分布样本,其中和基于95%的置信度,计算和;重复100次;然后计算出置信区间包含真实均值的百分比Python中,程序如下:re

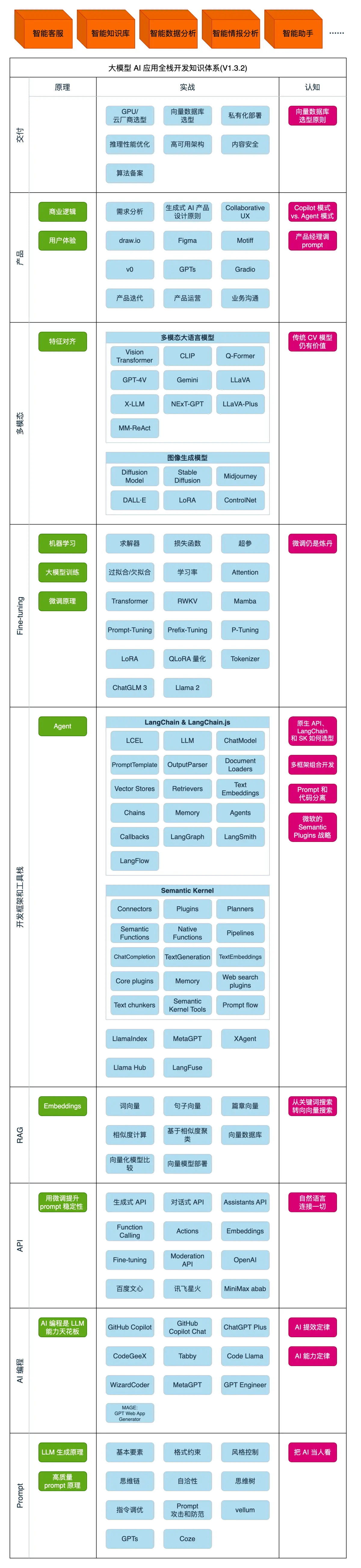
1、了解大模型能做什么2、整体了解大模型应用开发技术栈3、浅尝OpenAI API的调用AI全栈工程师:懂AI、懂编程、懂业务的超级个体,会是AGI(Artificial General Intelligence 通用人工智能)时代最重要的人。
自学黑客 / 网络渗透,一般人我劝你还是算了
AI大模型到底有多烧钱?或许最有发言权的就是OpenAI了,2022年其亏损大约翻了一番,达到约5.4亿美元。据悉,Altman曾私下建议,OpenAI可能会在未来几年尝试筹集多达1000亿美元的资金,以实现其开发足够先进的通用人工智能。国内的AI公司也不例外。不完全统计,国内头部AI公司智谱AI、百川智能、零一万物、MiniMax和月之暗面,从去年下半年至今已完成了总额超30亿美元的融资,当然,

以致于现在各行各业都有人不断的加入到Python的学习潮流之中,但是对于想要入门Python的同学仍一头雾水,虽然网上的资料很多,但是很多资料都比较片面化,且很多是纯文字文档,对于一些想要。说起编程语言,Python 也许不是使用最广的,但一定是现在被谈论最多的。即使不是程序员,能用 Python 写上一小段程序,调用几个接口,也能极大提升工作效率。无论您是计算机相关专业的大学生,还是正在从事软件
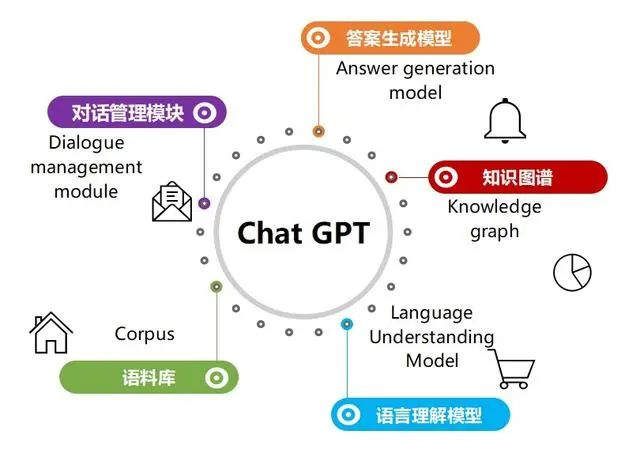
2023年,让整个人类最为振奋的AI技术就是ChatGPT。“大语言模型(Large Language Model)”这个词也随之映入人们的眼帘。ChatGPT让人觉得惊艳之处,能够结合上下文,像人一样有逻辑性地回答问题,就算生成超长的文本也不会跑偏。)是一种机器学习算法,它可以根据给定文本来预测下一个词语或字符的出现的概率,通过大量的文本数据来学习语言的统计特征,进而生成具有相似统计特征的新文本