登录社区云,与社区用户共同成长
邀请您加入社区
Windows系统中下载安装PyCharm及打开项目详细步骤。
numpy是Python的一个扩展库,可以让Python语言更加有效地操作数组。使用numpy,我们可以轻松地将Python转换为一种简单易用的科学计算环境。numpy中包含了许多高效的数学函数和可支持灵活的维度数组(多维数组)。numpy的安装需要一些技巧。在Python2.7中,我们需要进行一些准备工作,然后才能够成功安装numpy。本文由chatgpt生成,文章没有在chatgpt生成的基础
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。🧡AI职场汇报智能办公文案写作效率提升教程 🧡专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的
数组是一个有序集合。数组的特点是固定大小,其中的元素类型相同。在Python中,数组是使用列表(List)来表示的。我们可以将列表中的元素看作是一个个的数组元素,并使用索引访问它们。Python 是一种灵活的编程语言,可以用于创建各种类型的数据结构。在这篇文章中,我们介绍了如何使用 NumPy 库创建三行三列的数组。数组是一种有序,固定大小且类型相同的数据结构,在科学计算中得到广泛应用。想了解更多
os.system函数是一个非常常用的系统调用函数,它的作用是执行一个命令行语句。当你需要在Python脚本中执行一个外部命令时,就可以使用os.system函数。比如,在Windows系统下,我们可以通过os.system(“dir”)来执行dir命令,这个命令会列出当前目录下的文件和文件夹。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力
NumPy是一个Python的开源数值计算库,用于支持大规模多维数组与矩阵运算,包含了许多有用的函数,如傅里叶变换、随机数生成、线性代数、傅里叶系数和卷积等。n维数组(ndarray)复数数组(complex ndarray)各类型数组(dtype)同时,NumPy也提供简单灵活的编程接口,允许开发者轻松地组合和操作各种类型的数据。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行
趋势是数据在长期范围内变化的方向。在时间序列中,趋势是指数据点增加或减少的平均速度。通常,趋势是随时间逐渐变化的,因此趋势分析可以给我们一个数据的整体趋势方向。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”A
numpy-quaternion是一个numpy扩展,提供了用于生成和操作四元数的函数和类。它基于NumPy数组,使得可以在数值上优化代码,同时也可以充分利用现有的数学函数。numpy-quaternion还支持将四元数转换为旋转矩阵以及与其他四元数和向量进行运算。它是一种强大且灵活的工具,使得在Python中使用四元数变得更加容易。本文由chatgpt生成,文章没有在chatgpt生成的基础上进
空格输入通常指在程序中用键盘输入空格字符。在Python中,空格用于分隔字符串,在格式化输出中也是必不可少的。通过空格输入,我们可以对程序进行更精确的控制,使其能够更好地适应不同的输入数据。因此,理解空格输入在Python中的使用方法是非常重要的。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它
Python提供了非常简单的方式来实现五个一行输出。我们只需要使用for循环和列表切片即可轻松实现。如果您有兴趣学习Python编程或者需要实现其他功能,我们欢迎您访问我们的网站,您将能够获取更多有关Python编程语言的资讯、课程和实践经验。以上就是今天我们介绍的内容,希望能够对大家有所帮助。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力
在我们深入探讨numpy的正确读音之前,让我们先了解一下什么是numpy。一个强大的N维数组对象 ndarray;广播功能函数;整合C/C++/Fortran代码的工具;线性代数、傅里叶变换、随机数生成等功能。这些功能的实现都经过了优化,能够快速处理大型数组和矩阵运算。NumPy库是Python数值计算中不可或缺的重要库,因为许多Python库都是基于NumPy进行开发的。本文由chatgpt生成
rearrange函数是Python字符串库中的一个功能强大的工具。它可以用来重排字符串中的字符,以产生一个新的字符串,新的字符串可以是任何一种排列组合,无论它是否在原来的串中出现过。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是
Python Advanced Options是Python编程中可用的高级编译器选项。这些选项可用于优化Python程序的性能和效率,例如加速Python程序的运行,使其可扩展性更好,或优化内存使用等。这些选项可以通过编译器选项或环境变量来控制,或者在Python代码中使用特定的库。Python Advanced Options是Python编程中可用的高级编译器选项,可用于优化Python程序
npz 文件是一个多个数组数据的压缩文件格式,它是由 numpy 提供的一种数据存储格式。在处理大量的科学计算数据时,npz 是一个非常好的方式。当我们需要处理多个数组数据时,可以使用 npz 文件将它们压缩成一个文件,这样可以方便的存储和传输这些数组数据。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,
首先,让我们来了解一下什么是Python依赖包。Python依赖包是包含预定义功能或代码的软件包,用于扩展Python的功能。如果您的Python脚本依赖于其他软件包的某些功能,则必须安装这些软件包以确保脚本可以正常工作。常用的Python依赖包包括NumPy、pandas、matplotlib和Scikit-Learn等。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修
np.dot() 和 np.matmul() 这两个函数一直困惑了我好久,他们之间的区别到底在哪?其实在有二维数组参与运算时,他们的运算结果是一样的,区别就在于一维与一维的内积。另外在有一维数组和二维数组混合运算时,时常会将概念混淆,要弄清这个问题,就要分清一维与二维。
通过本教程,开发者可掌握在国产操作系统上进行AI开发的全流程,同时支持国产软硬件生态。
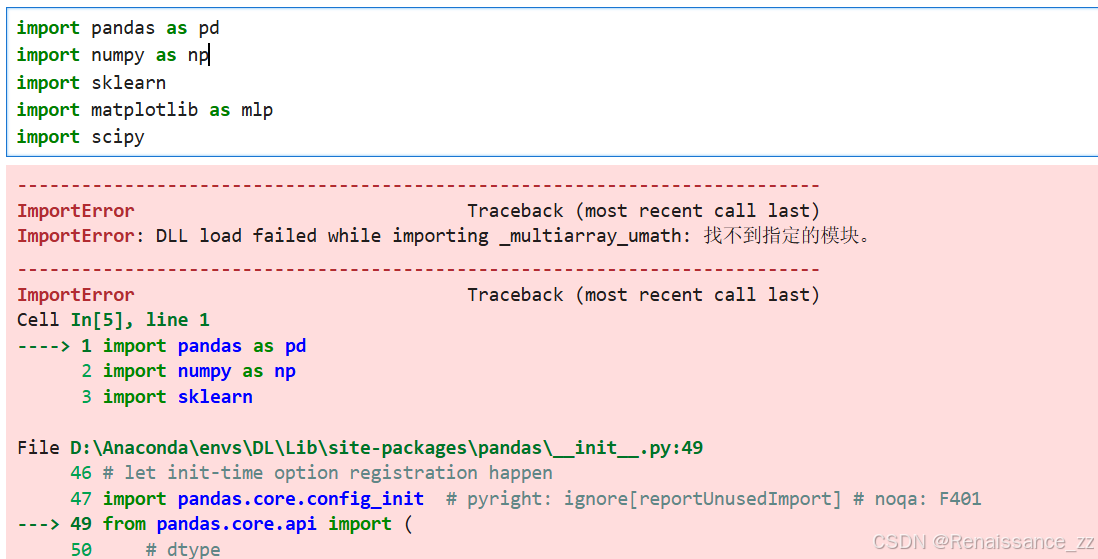
又试着更新了numpy的版本,结果问题就解决了hhh,没有报错了。我检查了环境变量已经设置正确,但是仍然无法解决这个问题。
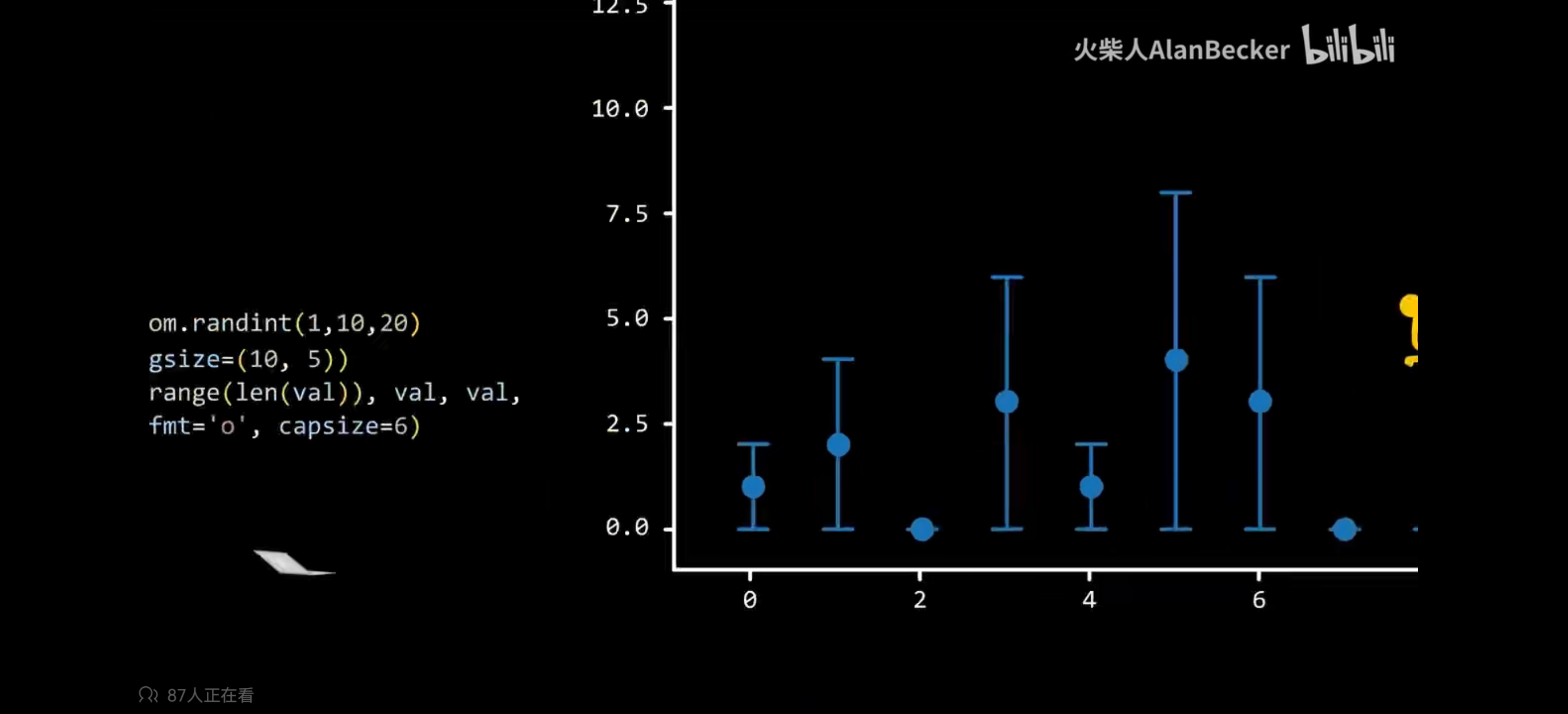
先用np.random.randint(0,10,20)生成一个包含0~10数字的,长度为20的数组。画出误差线图表。Plt.show()显示。
E:\anaconda\envs\envcat\lib\site-packages\torch\_subclasses\functional_tensor.py:275: UserWarning: Failed to initialize NumPy: DLL load failed while importing _multiarray_umath: 找不到指定的模块。卸载numpy用conda
【代码】Installing Rocky Linux 9: Complete Installation Guide。
tail指令从指定点开始将文件写到标准输出,使用tail命令的 -f 选项可以方便的查阅正在改变的日志文件,tail -f filename 会把 filename 里最尾部的内容显示屏幕上,并且不断刷新,使你看到最新的文件内容。就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块,head用来显示档案的开头至标准输出中,而tail想当然就是看档案的结尾。:查看小文件,小算法,小配
【代码】Linux lvm snapshot backup and restore tutorial RHEL/CentOS 7/8。
WebSocket 是全双工通信协议:客户端 ←→ 服务端(连接保持,双方随时收发)优势:✅ 服务端可以主动推送消息✅ 连接持久化(不需要反复建立连接)✅ 实时性高(延迟低)✅ 带宽占用少典型应用场景场景说明即时聊天微信、Slack 等实时数据股票行情、体育比分在线游戏多人实时同步协作编辑Google Docs、腾讯文档通知推送系统通知、消息提醒回到顶部示例 1:基础通信 - 客户端请求,服务端响
本文实现了JAKAZu12机械臂的正逆运动学算法,基于标准DH参数建立运动学模型。正运动学通过链式变换矩阵计算末端位姿,逆运动学采用解耦法分解为位置和姿态求解。算法支持肘部配置选择,并处理奇异位形情况。可视化模块可3D展示机械臂构型和工作空间。工程应用中需注意多解选择、奇异位形处理及与控制器接口转换。测试验证表明算法精度满足要求,为机械臂控制提供核心运动学支持。
服务端不能主动推送消息❌ 需要轮询(客户端不停问"有新消息吗?")❌ 每次请求都要重新建立连接(开销大)WebSocket 的优势WebSocket 是全双工通信协议:客户端 ←→ 服务端(连接保持,双方随时收发)优势:✅ 服务端可以主动推送消息✅ 连接持久化(不需要反复建立连接)✅ 实时性高(延迟低)✅ 带宽占用少典型应用场景场景说明即时聊天微信、Slack 等实时数据股票行情、体育比分在线游戏
人工智能又称机器智能,主要研究人工的方法和技术开发智能机器或智能系统,以模仿、延伸和扩展人的智能、生物智能、自然智能,实现机器的智能行为。人工智能的定义分四类:(1)像人一样思考地系统(2)像人一样行动的系统(3)理性地思考的系统(4)理性地行动的系统。
软链接 ln -s独立 inode,类似快捷方式,可链接目录、跨分区普通用户访问系统保护目录(/run/radvd)会报权限不足root 直接 touch 软链接会覆盖软链接,转为普通文件,硬链接同步失效硬链接 ln与源文件共用 inode,链接计数 + 1,修改任意文件同步生效不能链接目录、不能跨分区;对软链接创建硬链接仅绑定软链接本身目录操作命令区分mkdir -p:递归创建多层目录;注意不要
本文介绍了使用NumPy进行机器人运动学计算的方法,包括旋转矩阵、齐次变换和正运动学求解。通过对比C++的Eigen库,突出了NumPy在算法原型开发中的优势,如动态类型、交互式环境和向量化运算。文章详细展示了二维/三维旋转矩阵的实现、齐次变换矩阵构建、二自由度机械臂正运动学求解,以及批量计算优化技巧。最后强调了面试中可能被问及的数值稳定性、四元数运算等进阶问题,并预告下篇将介绍Matplotli
本文介绍了Python科学计算库NumPy的核心概念及其在机器人开发中的应用。NumPy的核心是ndarray多维数组,相比Python列表具有内存连续和向量化运算的优势,能显著提升计算效率。文章讲解了数组创建、reshape、切片、广播等基本操作,以及数学运算、数据类型选择和性能优化技巧,并指出新手常见错误如视图修改和整数溢出问题。最后强调了NumPy在机器人领域的典型应用场景(传感器数据处理、
本文介绍了NumPy数值计算基础的核心内容,主要包括: 数值类型与多维数组:NumPy的ndarray对象是高效的多维齐次数组,支持多种数值类型(dtype),具有连续内存和向量化运算优势。 数组创建与属性:演示了创建数组的多种方法(如np.array()、np.zeros()等)以及数组的关键属性(shape、ndim、dtype等)。 数组运算:NumPy支持逐元素运算(element-wis
本文介绍了NumPy库的核心概念和基本操作。NumPy作为Python科学计算的基础库,其核心是ndarray(N维数组)对象,相比原生Python列表具有显著优势:内存块风格(连续存储、类型一致)、并行化运算和底层C语言实现带来的高效计算。文章详细讲解了ndarray的属性(形状、维度、类型等)、不同维度的数组表示方法,以及数据类型体系。最后介绍了数组的基本操作,包括生成方法和索引切片机制。Nu
多维性:支持0维度,1维度(向量,一维数组),2维度(矩阵),以及更高维度的数组同质性:所有元素类型必须一致(即使你定义时不一致,最后也会类型上升统一到一致,这样是为了快速计算),可以通过dtype制定高效性:基于连续的内存块进行存储,支持向量化计算作用:根据传入的形状生成全0数组,快速初始化全0数组调用:np.zeros(传入形状) 例:np.zeros((2,3))zeros_arr = np
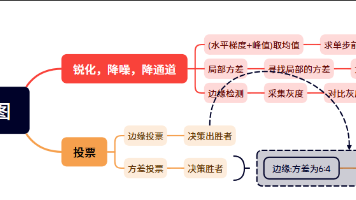
本文介绍了NS航司验证码破解的技术方案,主要针对六种随机下发的滑动验证码类型(Silder/CURVE2/CURVE/WORD/MOBIE/Silder2)。方案包含三个关键环节:1) 通过接口分析获取验证码背景图;2) 采用图像处理技术(灰度化、降噪、边缘检测等)定位缺口位置;3) 模拟人类滑动轨迹(变速移动+随机抖动)。该方案通过结合缺口检测(60%)和局部方差分析(40%)的投票机制,识别准
(强推)
numpy
——numpy
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区

 AI编程社区
AI编程社区











 全球具身智能开发者社区
全球具身智能开发者社区





 DAMO开发者矩阵
DAMO开发者矩阵


 AMD开发者中国社区
AMD开发者中国社区