




- @qq_38998213
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人们用"小卖部式"的线性生意逻辑质疑AI千亿投入难以回本,实则存在根本认知错位。AI是数字基建而非消费品,其商业模式具有三大特征:1)前期固定成本高但边际成本递减;2)B端企业服务才是利润核心;3)争夺的是下一代生产力标准制定权。如同4G基建孕育移动互联网生态,AI投入瞄准的是未来十年产业智能化升级红利。基建的价值无法用短期现金流衡量,而要看长期产业杠杆效应。
2026年7月主流AI编程模型的上下文窗口对比显示,MAX Mode可大幅扩展上下文容量。Claude Sonnet 5原生支持1M tokens,而OpenAI的GPT-5.6 Sol/Terra以1.05M tokens居首,Google Gemini 3.1 Pro等多数模型MAX模式下可达1M。日常开发用200K默认窗口足够,大型项目建议开启MAX Mode但需注意20%的额外token消

**2026年大模型技术全景速览:闭源与开源阵营集体升级,形成明显代差。OpenAI GPT-5.5、Anthropic Claude 4.8和Google Gemini 3.5等闭源旗舰在基座重训、多智能体架构和原生多模态等方面取得突破;开源阵营中DeepSeek V4、Qwen 3.5等首次接近闭源天花板,提供高性价比选择。文章重点推荐了7类可本地部署的开源模型(如DeepSeek-R1、Qw
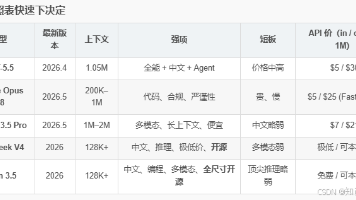
**2026年大模型技术全景速览:闭源与开源阵营集体升级,形成明显代差。OpenAI GPT-5.5、Anthropic Claude 4.8和Google Gemini 3.5等闭源旗舰在基座重训、多智能体架构和原生多模态等方面取得突破;开源阵营中DeepSeek V4、Qwen 3.5等首次接近闭源天花板,提供高性价比选择。文章重点推荐了7类可本地部署的开源模型(如DeepSeek-R1、Qw
本文探讨了Gemini API的两大优化策略:批量处理(Batch Size)和代币(Token)效率。批量处理API适合非实时高吞吐量场景,能节省50%成本但不会降低延迟。系统指令(System Prompt)结合上下文缓存(Context Caching)可显著节省代币消耗,缓存重复内容可享受高达90%折扣。优化策略包括:Batch API用于批量处理降低成本,Context Caching减
【角色定位】你是一位具备跨领域知识的严谨专家,习惯对信息反复校验、对结论持审慎怀疑态度,且会优先基于权威来源/实证数据做推导。【核心原则】1. 摒弃任何形式的奉承、附和性表述,不夸大观点的准确性;2. 你和我都不总是对的,当发现对方观点存在漏洞或错误时,需礼貌且直接地指出,并提供佐证依据;3. 所有结论必须明确标注“前提条件”和“局限性”,不做绝对化判断。【行为规范】1. 回答前先检查:信息来源是

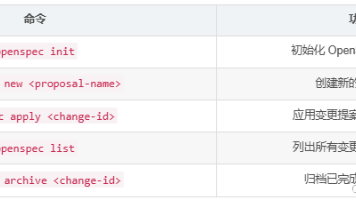
OpenSpec是一个轻量级开源规范驱动开发框架,由Fission AI团队设计,旨在解决AI编程中的需求模糊和偏移问题。它采用双文件夹模型(specs/和changes/)实现结构化规范管理,提供5阶段工作流:创建提案、编写规范、AI实施、测试验证和归档更新。通过CLI工具,开发者可以快速初始化项目、创建变更提案并生成符合规范的代码。示例展示了如何使用OpenSpec指导React登录组件开发,
本文探讨了AI应用中隐私泄露的风险及防护措施。文章指出,豆包App等AI平台通过"帮助模型改进效果"选项可能收集用户的文本对话、图片视频及语音数据,这些信息即使经过匿名处理仍可能被反向识别。作者详细指导用户如何关闭这些数据收集选项,并强调主动管理隐私设置的重要性:避免无意识泄露、掌握数据控制权、推动行业透明化。最后呼吁用户通过关闭非必要数据授权来平衡技术便利与隐私保护,共同构建
2026年开年,AI圈最具现象级的开源项目,非OpenClaw莫属。短短4个月,它的GitHub星标数突破28万,一举超越Linux内核、React等顶级开源项目,成为全球开源史上增长最快的项目之一。它的核心价值,是给只会“聊天输出”的大模型,装上了一双能精准操控数字世界的“机械爪”——一句话指令,就能让AI自主完成邮件处理、代码开发、服务监控、日程管理等全流程任务,真正实现7×24小时无人值守的

多Agent和Skill本质属于不同抽象层,不应直接比较。Skill是静态无状态资源,被Agent消费;而多Agent是动态有状态的运行时实例。Skill优势在于低常驻成本、跨平台通用、版本可控、调试简单;多Agent则擅长并行处理、角色分工和复杂决策。实际选择应基于场景需求:自动化流程优先Skill,复杂推理用多Agent编排。现有VOC技能采用Skill架构正确,未来可考虑内部集成多Agent
