登录社区云,与社区用户共同成长
邀请您加入社区
数字孪生透明建筑技术通过3D重建和视频融合,实现物理场景的全透明数字化复刻,其核心优势在于"一屏看全局"。该技术突破传统管控局限,在货舱、机场、煤运输、码头及大型体育设施等场景中,无需切换画面即可实时监控内部结构、设备运行及人员动态,快速定位安全隐患并联动处置,推动安全管理从被动应对转向主动防控。作为智慧安全管理系统核心,该技术以可视化革新提升管控效率,引领行业向数字化、智能化
我以前也觉得,做新媒体营销只要开个ChatGPT或者随便找个免费的云端AI写写文案就够了,直到公司连续换了3个运营、账号矩阵的数据还是起不来,让我开始怀疑这件事。然后我做了一件很笨的事:把市面上主流的AI营销解决方案全部列出来,一个一个去验证它们的实际产出效果。
国产时序数据库标杆 DolphinDB(智臾科技)与国产安全操作系统领军厂商凝思软件顺利完成官方产品兼容性双向互认
TimechoAI是面向工业时序数据的智能分析平台,以专属大模型与时序数据库协同,零代码提供预测、异常检测等能力,打通全链路,降低落地门槛。
TimechoAI提出国产时序全栈解决方案,针对工业时序数据的安全与智能化需求,构建存算一体化体系。该方案包含自研时序数据库(TimechoDB)与专属时序大模型(TimechoAI),全链路实现数据采集、存储、加密、分析的闭环内网处理,解决海外技术依赖、数据外泄和通用模型适配差等问题。核心技术包括长周期预测、无样本异常检测、缺失值补全及多测点关联分析,已在能源、轨交、钢铁等行业落地,存储压缩比提
近日,中国信息通信研究院(简称”中国信通院”)2026 上半年评估测试结果正式揭晓。经来自联通软研院、陕西移动、瑞众人寿、上海国际汽车城、中国航信、邮储银行等单位的行业专家评审,,成为本批次中同时斩获 AI 大模型时序数据管理平台、时序数据库性能、时序数据库稳定性三大领域认可的数据库产品。其中,TDengine是通过基于 AI 大模型的时序数据管理平台全项测评的产品,时序数据库性能与稳定性两项专项
摘要:随着AI气象大模型在预报精度上不断突破,高质量数据供给不足成为制约科研效率的瓶颈。传统分散的数据获取方式耗时费力,而聚合型气象数据平台通过整合多源数据、优化融合算法,显著提升了数据获取效率和质量。以羲和能源气象大数据平台为例,其提供的历史与未来气候情景数据(至2100年)、小时级分辨率及多模型集成功能,已支撑200余篇高水平论文研究。这类平台通过简化数据预处理环节,使科研人员能将更多精力投入
TimechoAI时序大模型是一款基于清华Timer模型的时序预测工具,旨在通过API调用简化传统时序建模流程。其核心能力包括高精度预测(比传统方法提升20%+)、毫秒级响应、多变量联合预测(支持协变量输入)以及企业级安全(支持私有化部署)。产品提供三种数据输入方式(绘制曲线、粘贴数据、上传文件)和六种预测模型可选(包括Timer系列和经典统计模型)。独特的数据评估功能可提前检测数据质量,避免无效
摘要: 时序大模型 TimechoAI 通过人工智能技术,为工业时序数据分析提供智能化解决方案。传统方法依赖人工规则和经验,难以应对海量时序数据(如设备温度、电流等)的分析需求。TimechoAI 基于时序基础模型 Timer,支持时序预测、异常检测、数据填补等功能,能够理解多变量时间序列的复杂变化规律,实现提前预警和趋势预测。该平台降低了企业使用时序AI的门槛,无需复杂算法开发即可快速验证模型效
移动云目前已构建出完善的云智算体系,能够为大模型部署、应用提供算力、模型、智能体、开发工具等全链路服务。以模型服务为例,针对不同规模、不同行业企业的大模型差异化使用需求,移动云可通过模型服务平台为企业提供涵盖文本、图像、语音、视频等全模态类型的300余款主流优质大模型,同时平台创新引入“智能路由调度”机制,能够根据问题复杂度、响应时效要求、数据敏感性等用户请求特征,自动匹配当前模式下最适合的模型。
目前移动云既能够基于GPU云主机、裸金属服务器、智算一体机提供智算算力,也能通过智算平台、模型服务平台提供从资源到工具全链路智算服务。以移动云模型服务平台为例,该平台能够为用户提供包括开源、闭源、自研九天大模型在内的300余款主流优质大模型,涵盖文本、图像、语音、视频等全模态类型,同时还能提供政务、文旅、金融、应急等多领域智能体,因此能够大幅降低用户模型、智能体开发难度,以大模型原生应用加速智能化
上周五深夜,北京著名的工体酒吧一条街上,一家名叫"迈阿密"的酒吧里,月之暗面的年轻人包下数十张卡座,大屏幕滚动着中英双语标语:“K3扩容升级,K4给我狠狠干到极致,冲上月球。会用AI的人与不会用AI的人,能拿到算力资源的公司与拿不到的公司,掌握数据的大平台与没有数据的普通人——差距不是在缩小,而是在以另一种方式拉大。既拓展了认知的边界,也在悄悄侵蚀独立思考的土壤。看到这条AI圈少见的“娱乐新闻”,
这里重点介绍一下Telegraf的相关知识:Telegraf是一个插件驱动的数据收集代理,它可以从各种来源(如操作系统、数据库、网络设备等)采集指标数据,并将其发送到InfluxDB进行存储和分析。Telegraf具有丰富的插件生态系统,可以轻松地扩展和定制数据采集过程。用户可以根据自己的需求选择和配置适当的插件,以收集特定的指标数据。Telegraf 是由 InfluxData 开发的一个开源的
更关键的是,特斯拉开始向第三方企业出售整套超充技术与运营服务,“白牌版”超级充电站,任何企业都可以购买特斯拉超充桩、贴上自己的品牌运营,特斯拉从中获得硬件、软件授权和后续服务三重收入。当一家公司同时控制着地面上的汽车、天上的卫星、工厂里的机器人和驱动这一切的芯片与算力时,它的竞争对手面对的不再是一家“车企”,而是一张无处不在的基础设施网络。现在,特斯拉开始向第三方售卖“白牌版”超充站:设备是你的,
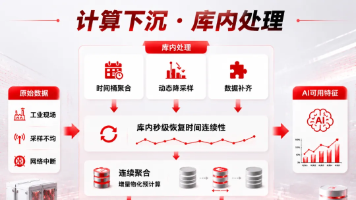
本文详解工业场景时序数据架构方法论——时序数据的核心价值是"看到变化",但需与关系、GIS、向量数据关联才能做出准确判断。拆解金仓 KES TimeSeries 在写入(Append 追加写、无锁化)、存储(Delta-of-Delta 压缩 10:1)、查询(连续聚合毫秒级响应)三个链路的专项优化,给出融合架构选型建议。
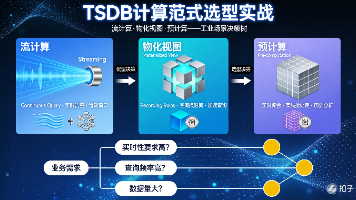
TSDB的计算范式选型,本质上是在“实时性”、“成本”和“复杂度”之间寻找平衡点。流计算是神经,负责感知与瞬时反应;物化视图是缓存,负责加速与响应;预计算是骨骼,负责归档与降本。AI-Native:内置时序预测(ARIMA、LSTM)和异常检测算法,计算引擎直接服务于AI Agent的决策闭环。Serverless:计算资源根据负载自动弹性伸缩,用户只需关注计算逻辑,无需关心底层调度。
—上述罚单中“未纳入并表管理”“未统一授信”的痛点,正是其发力点。当一家行业公认的“优等生”接连领罚,信号已足够清晰:监管的探照灯正从“前端展业”照向“全流程体系”,从“罚机构”延伸至“追个人”。深耕企业法务数字化多年,道本科技以合规管理系统、合同管理系统、合规数知法用法平台三大产品,为企业搭建从“被动应对”到“主动设防”的合规体系。——运用人工智能与大数据技术,将合规审查嵌入合同起草、审批、履约
工业物联网普遍陷入"数据采得起、却治不动"的困境:传感器越装越多、采集频率越提越高,原始数据却堆成山、查询越来越慢、磁盘越扩越大。根因往往不是数据库不够先进,而是治理没跟上。本文以 DolphinDB 一体化时序数据平台为对象,把物联网数据从"采得进来"到"用得起来"的整条链路拆成五个阶段——采集接入、存储治理、实时计算、分析挖掘、协同运维——逐阶段讲清架构选型与设计原则。
以某共享单车平台为例,其车辆数量超过 100 万辆,车辆开关锁、位置上报、电池电量等状态变化频繁,对消息队列和时序存储的并发处理能力要求很高。从物联网场景看,TDengine 支撑按时间维度配置冷热数据分级,热数据保留在 SSD,冷数据自动迁移到对象存放。随着时间的推移,冷信息比例越来越高,如果不执行分级保存,企业将不断为几乎不访问的数据支付高昂的存储费用。所有信息放在高性能磁盘上,保存成本居高不
对千行百业的用户而言,与其临到 AI 落地时再去拼凑数据链路,不如提前准备一套能稳定承载时序数据、完成库内计算、组织多模态上下文的数据架构——这才是面向未来更务实的选择。对行业 AI 来说,真正重要的从来不是"拥有更多数据",而是能否持续获得完整、及时、可用的业务上下文。金仓 KES 时序数据库要解决的,正是这件事。
KES TimeSeries数据库通过多模融合架构解决AI业务落地痛点,将时序、关系、GIS、向量数据统一集成,实现高效存储与联合分析。其核心优势包括时序数据高并发写入、专用压缩存储降低90%成本,以及内置时序算子支持毫秒级聚合。实操示例展示了环境初始化、多模数据表建模、时序数据写入等关键步骤,助力工业设备智能诊断场景实现数据闭环分析。(149字)
IoT 物联网平台:设备时序 + 元数据宽表 + 日志检索统一管理,适用于替代 InfluxDB+MySQL+ES 三库拼接方案工业物联网:传感器时序采集 + 设备画像 + 异常检索,适用于预测性维护与数字孪生车联网与智能交通:车载传感器时序 + 车辆档案 + 轨迹检索,适用于大规模车队数据底座互联网运维监控:Metrics 时序 + 配置宽表 + 日志检索,适用于替代 Prometheus+My
此外,华为还推出了自家的编程语言——方舟编译器(Ark Compiler),该编译器的核心目标是提高编程效率和应用性能,尤其是在移动设备与物联网设备中的表现尤为出色。例如,通过NLP技术,AI可以通过自然语言指令生成相应的代码,甚至能够理解和修复开发者写的代码。人工智能(AI)编程是现代科技的前沿领域,它不仅仅改变了编程的方式,也推动了各行业的深刻变革。总体来看,鸿蒙系统通过多语言支持和自研编译技
其次,这个编译环境支持多种常见的C语言库,可以快速实现各种功能,无需过多配置。为了有效学习C语言并进行实际的程序开发,选择一个适合的编译环境至关重要。2017年发布的二级C语言编译环境,已经支持了更多的现代编程需求,并提供了一些强大的功能。通过逐行调试,开发者可以更清晰地看到代码执行的过程,从而更容易定位和修复程序中的错误。在2017年,二级C语言编译环境逐渐成为编程学习和实际开发的重要工具。总的
网络上有大量免费的教程、视频和论坛,学习者可以根据自己的时间安排学习,而不需要面对传统教育机构的时间约束。对于自学者来说,最初可以选择一些入门的编程语言,如Python,它以简单易学的语法著称,适合初学者。其次,如何在保持高效性能的同时,保证跨平台的兼容性和开发便捷性,是鸿蒙系统进一步发展的关键。总之,自学编程是完全可行的,关键在于坚持和实践。总的来说,鸿蒙系统的编译语言和开发工具为开发者提供了一
鸿蒙系统的编译语言并非单一,而是由多种编程语言共同组成,特别是在C、C++和Java的基础上进行了优化,确保系统的高效运行。对于开发者而言,鸿蒙系统的编译语言不仅能够提供更高的性能,而且兼容性也得到了极大的增强,能够满足智能硬件设备的多样化需求。不过,反编译技术并非完美无缺。比如,通过对硬件资源的高效利用,鸿蒙系统能够在不同设备上实现更流畅的操作体验,这对设备的响应速度和续航时间有着显著的提升。随
{'prompt': 'A header for an article about HarmonyOS cross-platform development, focusing on the performance boundaries of ArkTS and Java mixed programming, with a subheading that explains the topic in
ArkTS作为鸿蒙系统推出的全新编程语言,旨在提供一种高效、灵活的方式来进行跨端开发,而Java作为一种成熟的语言,依旧在大多数开发场景中占有一席之地。随着鸿蒙操作系统的逐步普及,越来越多的开发者开始关注其跨端开发的能力,尤其是在ArkTS与Java混合编程的应用场景中。随着鸿蒙开发工具的不断完善和优化,开发者将能够更加高效地进行跨端开发,并通过ArkTS与Java的组合,发挥各自的优势,提供更加
鸿蒙操作系统(HarmonyOS)是华为开发的一款全新操作系统,旨在实现万物互联,支持多种设备平台的统一管理。通过分布式架构,鸿蒙能够使智能设备之间实现无缝连接,不同平台的应用可以无缝运行。与传统的安卓和iOS操作系统不同,鸿蒙不仅仅聚焦于手机,还包括智能穿戴设备、家电、车载设备等领域。鸿蒙操作系统的关键优势之一是其跨平台开发能力,支持多种语言和框架的混合编程,其中最为重要的两种编程语言为ArkT
ArkTS是鸿蒙操作系统中的一门专为其设计的编程语言,它具有更高的执行效率和更低的资源消耗,适用于在嵌入式设备和高性能应用中运行。而Java作为一种成熟的跨平台编程语言,长期以来广泛应用于服务器端和移动端开发。在鸿蒙开发中,通常需要将ArkTS与Java结合使用,以便在保证性能的同时,也能够利用现有的Java库和工具。混合编程的挑战在于如何平衡这两种语言的特点,充分发挥各自的优势,而不是在不同语言
鸿蒙(HarmonyOS)是华为公司推出的全新操作系统,旨在打破传统操作系统的边界,提供一种无缝连接的跨平台体验。它不仅支持智能手机、平板、智能家居设备、穿戴设备等多种设备,还实现了不同平台之间的互联互通。这种全新的设计理念使得鸿蒙在物联网(IoT)领域具有独特的竞争力。鸿蒙操作系统的核心特性之一就是支持多设备同时运行,并实现设备间的协同工作。为了实现这一目标,鸿蒙系统采用了分布式技术,使得开发者
随着鸿蒙操作系统和Rust语言的崛起,前后端融合的新时代已经到来。通过鸿蒙提供的统一平台和Rust提供的高性能,前后端开发将不再是两个割裂的领域,而是紧密合作、共同进步的整体。未来,随着这些技术的不断发展,前后端开发将迎来更加高效、智能的时代。??
鸿蒙操作系统(HarmonyOS)由华为开发,是一款面向全场景、多终端的分布式操作系统。其目标是实现不同设备间的无缝连接和协同工作,包括手机、平板、智能电视、智能穿戴设备等。与传统的Android或iOS不同,鸿蒙采用了一种分布式架构,允许开发者在多个终端之间共享和同步数据。??在鸿蒙跨端开发中,ArkTS与Java的混合编程模式为开发者提供了更高效、灵活的开发方案。通过合理的性能测试与优化,可以
华为完成鸿蒙系统内部战略重组,统一整合操作系统及相关知识产权与品牌域名资产。此举强化品牌独立性,优化生态协同效率,为全球市场拓展奠定基础。鸿蒙系统设备数量已突破X亿台,成为全球第三大移动操作系统。华为表示将持续加大研发投入,开放合作共建生态。分析认为这是鸿蒙迈向市场化独立运营的关键步骤,展现华为的战略韧性,未来将探索更广阔的商业化路径。
时序数据是2026年增长最快的数据类型之一。据行业预测,工业物联网产生的时序数据量将占企业总数据量的75%以上,年复合增长率超过40%。时序数据已从“技术补充”升级为“核心资产”。本文从时序数据的基本概念出发,讲解时序数据的特征、应用场景,以及为什么传统数据库处理不了时序数据,帮助读者建立对时序数据的完整认知。
摘要: 2026世界人工智能大会展示了液冷技术在AI算力集群中的应用趋势,强调需从系统架构层面评估液冷方案。液冷技术分为冷板、单相浸没和两相浸没三种路线,各有不同的介质特性、兼容性及工程验证重点。选型需结合系统设计、材料兼容性、测试条件等综合考量,而非单一物性参数。苏能等企业针对不同路线开发了特定产品,但实际应用需以项目验证结果为准。工程验证应包含架构图、材料清单、测试方案等完整资料包,确保技术落
influxdb3 浏览器登录需要单独的后台,在influxdb官网可以下载。
执行时间:$t_{\text{wasm}}$(Wasm模块时间) vs $t_{\text{js}}$(纯JavaScript时间)。公式化表示平均时间:$$\bar{t} = \frac{1}{N} \sum_{i=1}^{N} t_i$$,其中$N$为运行次数。Wasm版本通常更快:$t_{\text{wasm}} < t_{\text{js}}$,因为Wasm编译优化减少了解释开销。斐波那契
nfluxDB 是一种高性能的开源时序数据库,专门用于存储和查询时间序列数据。它由 InfluxData 开发,首次发布于 2013 年,用 Go 语言编写,注重性能、可扩展性和开发者的生产力。InfluxDB 适用于监控性能指标、物联网数据和实时数据分析等场景。
本文档面向熟悉 TDengine 的专业开发人员,提供 Java 连接器的进阶使用指南。内容涵盖性能优化、高可用架构、复杂场景处理等高级主题,帮助您充分发挥 TDengine 的性能潜力。阅读本文档前,请确保您已熟悉中的基本概念和 API 使用方法。
时序数据库
——时序数据库
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区

 openEuler 社区
openEuler 社区
















 DAMO开发者矩阵
DAMO开发者矩阵


 智能体开发者社区
智能体开发者社区



 2048 AI社区
2048 AI社区

 HarmonyOS开发者社区
HarmonyOS开发者社区









