- @2401_85375151
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
提示词是进入AI的入口,但不是AI大模型应用开发的全部。企业真实场景需要的是能够构建系统、连接数据、设计智能体、完成交付的人才。很多人对AI的第一印象,是“输入一句话,AI 就能给出答案”。于是,提示词成了很多人学习AI的起点。这没有错。提示词工程是大模型应用中很重要的一环,它决定了人与模型交互的质量,也影响内容生成、知识检索和任务执行的效果。但问题在于,提示词只是入口,不是终点。真正进入企业级应

2026年上半年全球物流行业AI Agent规模化落地现状分析:聚焦三类企业——新兴AI原生公司(如Cartage、Freehand等)通过非侵入式服务重构业务流程;大型物流企业(如C.H. Robinson)利用专有数据实现效率跃升(订单处理从4小时缩至90秒);传统软件巨头(SAP、Oracle等)将AI深度融入WMS/TMS系统。应用集中高频执行流程,但需警惕"Agent washing"伪

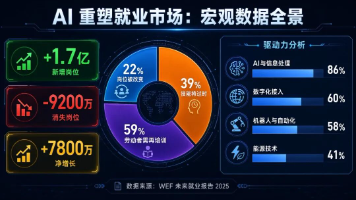
AI时代就业市场变革全景(2026年) 世界经济论坛预测,到2030年全球将净增7800万个岗位,同时22%的现有岗位将被彻底改变,39%的核心技能将在5年内过时。AI相关岗位(如AI工程师、Prompt工程师)薪资飙升,OpenAI工程师中位年薪达87.5万美元。增长最快的职业集中在AI、数据分析和绿色能源领域,而行政、基础客服等重复性工作加速消失。未来职场需要三大核心能力:AI技术素养(增长最
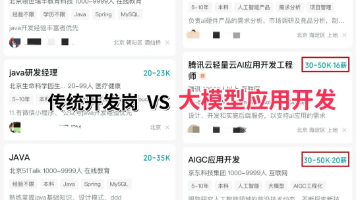
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?答案只有一个:人工智能(尤其是大模型方向)当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应
2026年科技招聘新趋势:AI与出海赛道薪资暴涨 36氪最新报告显示,AI Agent工程师(均薪82万)、具身智能算法岗(95万)和出海产品运营(45万)成为薪资涨幅最高的三大方向,6个月涨幅分别达40%、55%和30%,远超互联网行业8%的平均涨幅。其中: AI Agent:要求Python+LLM API经验,注重工程与产品思维结合,转型周期仅需6周; 具身智能:跨学科门槛高(AI+机械+控

摘要:大模型算法岗与Agent开发岗的区别与选择 核心区别:大模型算法岗侧重于模型研发(如Transformer架构优化、分布式训练等),属于高门槛科研型岗位,薪资高(100-200万/年)但竞争激烈;Agent开发岗聚焦AI工程化落地(如API调用、RAG知识库搭建等),利用大模型解决业务问题,薪资适中(40-70万/年),门槛低且需求广泛。 选择建议: 大模型算法岗:适合顶尖人才(需硕士学历、
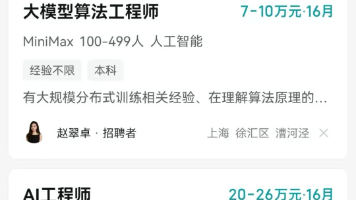
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?答案只有一个:人工智能(尤其是大模型方向)当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应

因为Agent开发本质上就是"用自然语言编程"——而这恰恰需要你已有的工程能力:你有代码功底 → 理解Function Calling、工具调用、API集成,比零基础快10倍你有系统设计经验 → 设计多Agent协作架构、状态管理、错误处理,逻辑一脉相承你懂工程化 → 部署、监控、性能优化,这些AI项目同样需要你理解数据 → RAG系统的数据清洗、向量检索、效果调优,你的DB经验直接复用说白了,你
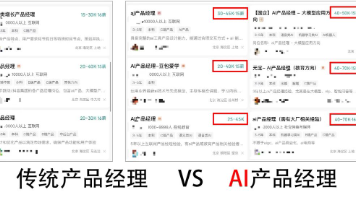
现在做产品经理难得不是做原型与需求调研了,而是让产品的设计方案从MVP再到产品上线能够获得用户,并且推向市场验证。在大厂,一个产品的ideal需要经过法务、财务、宣发布等部门来完成需求审核之后才可以做,而一个大厂领头产品的单元功能模块则需要通过层层的业务需求评审、其他关联平台的需求评审,从而得到功能模块的上线。功能模块现在不再是要求产品经理设计路径、撰写需求文档了,而是产品与AI模型的结合,以及模
程序员35岁之后都去哪了?这是我被问过最多的问题。最近我研究了50个35岁以上的程序员转行案例,有成功的,有失败的,还有在折腾中的。今天说说我看到的真实情况,不灌鸡汤,只讲数据。第一种转型方向:技术管理。这是最常见也是最顺的一条路。从程序员到技术经理,再到技术总监,最后到CTO。这条路的特点是转型最平滑,不用重新学太多东西,工资也是所有方向里最高的。但问题是管理岗就那么多,不是每个人都能上去,而且