- @2401_85373691
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入浅出地介绍了AI大模型背后的核心概念,包括神经网络、分词、嵌入向量、注意力、Transformer等基础架构,以及LLM、上下文窗口、温度、幻觉、提示词工程等关键要素。此外,还探讨了模型改进方法如迁移学习、微调、RLHF、LoRA和量化,以及真实AI系统构建中的RAG、向量数据库、AI智能体、思维链和扩散模型等。通过理解这20个概念,即使是小白或程序员也能轻松掌握大模型的工作原理,从而更好
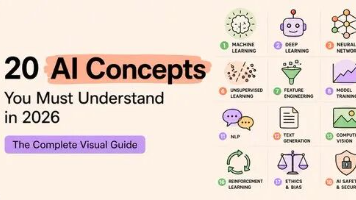
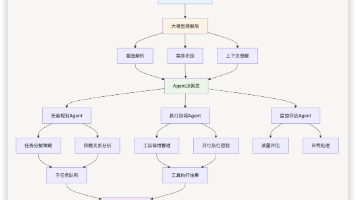
本文从AI智能体的底层基础(如LLM大语言模型、Token令牌、Context上下文、Context Window上下文窗口)开始,阐述了人机交互的沟通规则(Prompt提示词),扩展AI能力的工具(Tool、MCP模型上下文协议),最终到能解决问题的AI智能体(Agent智能体、Agent Skill智能体技能)。通过一个企业库存智能体的真实业务场景,将所有概念串联起来,帮助读者理解整个AI智能
本文从AI智能体的底层基础(如LLM大语言模型、Token令牌、Context上下文、Context Window上下文窗口)开始,阐述了人机交互的沟通规则(Prompt提示词),扩展AI能力的工具(Tool、MCP模型上下文协议),最终到能解决问题的AI智能体(Agent智能体、Agent Skill智能体技能)。通过一个企业库存智能体的真实业务场景,将所有概念串联起来,帮助读者理解整个AI智能
关于ChatGPT(或者更广义的generative AI)的讨论,如今已经演变成了agentic AI。ChatGPT主要是个能生成文本回复的chatbot,而AI代理则能自主执行复杂任务,比如完成一笔销售、规划一次旅行、预订机票、雇佣承包商干家务活,甚至点个披萨。下面的图表展示了agentic AI系统的演变。
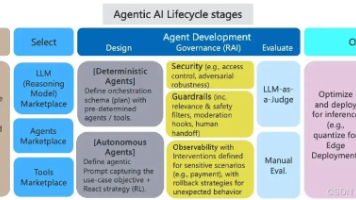
AI Agent(智能体)正在成为AI应用的下一个风口,但很多人对它的理解还停留在"更强的ChatGPT"层面。实际上,AI Agent与传统LLM有着本质区别:
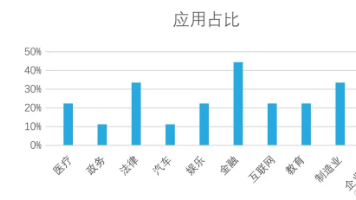
本文将详细介绍如何在金融、证券领域构建智能Agent系统,实现复杂问题的自动化任务分解、依赖管理和并行执行。通过大模型、意图识别、工具使用的协同配合,为用户提供高效、准确的金融数据分析和决策支持。
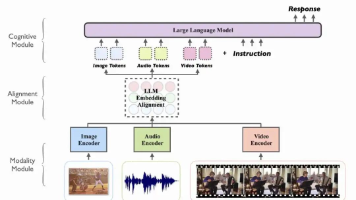
传统的大语言模型(LLM)如GPT、LLaMA等主要处理文本序列,基于Transformer架构在自然语言处理任务上取得了巨大成功。然而,现实世界的信息是多模态的——文字、图像、音频、视频等多种形式共同构成了人类的认知输入。如何在现有大模型的基础上扩展多模态能力,成为了AI发展的关键技术挑战。
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
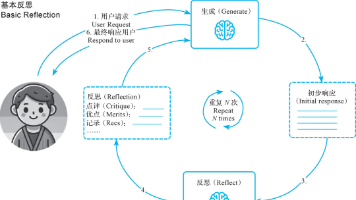
什么是 Agentic AI? Agentic AI 是一种构建 AI 应用的范式,它强调智能体(Agents)拥有目标、记忆、自主性和工具使用能力。
最近coze 将他们的扣子开发平台的核心引擎开源了。开源产品叫 coze studio,是一个一站式 AI Agent 开发工具。提供各类最新大模型和工具、多种开发模式和框架,从开发到部署,为你提供最便捷的 AI Agent 开发环境。熟悉coze的可以无缝衔接。