




- @Android_XG
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了Java开发工程师转型为AI工程师所需的核心技能,包括数学基础、Python编程、机器学习、深度学习和大型语言模型等,并提供了丰富的学习资源推荐,如Coursera课程、Dive into Deep Learning书籍以及国内平台如PaddlePaddle的资源。文章分析了转型优势与挑战,强调了AI领域的高薪需求和广阔前景,为Java开发者提供了系统性的转型路径。
本文针对企业内部/行业场景的智能客服与专业知识问答需求,探讨了FastGPT、Dify和RAGFlow三个开源项目的选型。文章从文档导入清洗、检索质量、引用溯源、权限管理、部署运维等维度对比了三者特点,并给出先试FastGPT验证闭环,再评估Dify做平台,以及RAGFlow作为增强/底座的落地路线建议,帮助读者快速构建满足合规要求、支持长期迭代的知识库系统。
本文深入浅出地解释了 Embedding 的概念及其在大模型中的作用。首先,定义了 Embedding 为将 token id 映射成向量的过程,并说明这一映射是通过模型在大量语言训练中学习得到的。其次,阐述了 Embedding 如何使“猫”和“狗”的向量更接近,强调了词义由其上下文决定的核心思想。最后,探讨了 Embedding 在 RAG 和 AI Agent 中的应用,指出其在检索和表示相
本文深入浅出地解释了 Embedding 的概念及其在大模型中的作用。首先,定义了 Embedding 为将 token id 映射成向量的过程,并说明这一映射是通过模型在大量语言训练中学习得到的。其次,阐述了 Embedding 如何使“猫”和“狗”的向量更接近,强调了词义由其上下文决定的核心思想。最后,探讨了 Embedding 在 RAG 和 AI Agent 中的应用,指出其在检索和表示相
本文旨在为AI初学者构建一张清晰的学习地图,帮助读者理解AI领域的核心概念与不同方向。文章首先指出初学AI容易迷路的原因,接着强调AI并非仅包含大模型,而是涵盖感知、理解、生成、决策和行动的技术体系。文章提出将AI学习分为基础概念层、经典AI方向层、大模型与多模态层、智能体与任务闭环层以及世界模型与具身智能层,并阐述了各层之间的关系。最后,文章建议初学者在了解AI全局地图的基础上,逐步深入学习,避
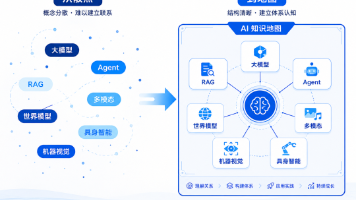
本文旨在为AI初学者构建一张清晰的学习地图,帮助读者理解AI领域的核心概念与不同方向。文章首先指出初学AI容易迷路的原因,接着强调AI并非仅包含大模型,而是涵盖感知、理解、生成、决策和行动的技术体系。文章提出将AI学习分为基础概念层、经典AI方向层、大模型与多模态层、智能体与任务闭环层以及世界模型与具身智能层,并阐述了各层之间的关系。最后,文章建议初学者在了解AI全局地图的基础上,逐步深入学习,避
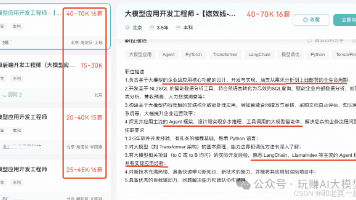
本文梳理了8类标准化的AI Agent架构,从简单的单轮推理到全自动自主闭环,层层递进。核心落地原则是简单流程不用复杂架构,稳定性优先。文章详细拆解了每种架构的核心原理、实施步骤、商用案例及优缺点,包括ReAct推理与行动闭环、Plan-and-Execute规划执行分离、Multi-Agent多智能体协作、Reflective Agent自我反思迭代、Tool-Augmented工具增强、Mem
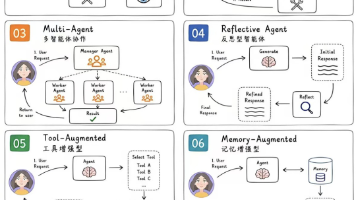
本文梳理了8类标准化的AI Agent架构,从简单的单轮推理到全自动自主闭环,层层递进。核心落地原则是简单流程不用复杂架构,稳定性优先。文章详细拆解了每种架构的核心原理、实施步骤、商用案例及优缺点,包括ReAct推理与行动闭环、Plan-and-Execute规划执行分离、Multi-Agent多智能体协作、Reflective Agent自我反思迭代、Tool-Augmented工具增强、Mem
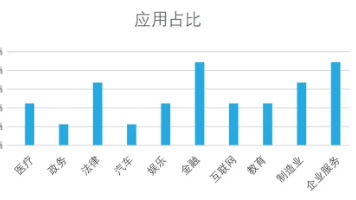
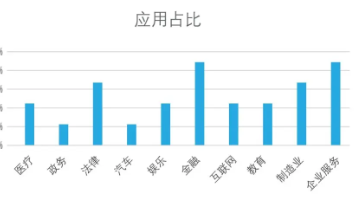
本文介绍了AI的广泛应用,从传统AI到生成式AI(如ChatGPT)的演进,解释了大语言模型(LLM)的核心工作原理,以及AI在内容创作、日常办公、编程开发、图片与视频创作、学习与教育等领域的应用。文章强调AI已成为一种新的基础能力,每个人都值得学习如何与AI协作,以提高工作效率和激发创意。最后,文章鼓励读者尝试使用AI助手完成实际任务,并思考如何验证AI生成内容的有效性。
本文介绍了AI的广泛应用,从传统AI到生成式AI(如ChatGPT)的演进,解释了大语言模型(LLM)的核心工作原理,以及AI在内容创作、日常办公、编程开发、图片与视频创作、学习与教育等领域的应用。文章强调AI已成为一种新的基础能力,每个人都值得学习如何与AI协作,以提高工作效率和激发创意。最后,文章鼓励读者尝试使用AI助手完成实际任务,并思考如何验证AI生成内容的有效性。