- @CSDN_224022
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文分享了作者从计算机小白成功转行AI大模型工程师的亲身经历,揭示了转行AI大模型常见的误区,并提供了一套清晰的学习路线。作者强调企业更看重能用Python搭建AI智能体、能用Java迭代项目的实干型人才,而非数学家。文章详细介绍了3个月的学习计划,包括打牢Python基础、建立大模型认知、磨练Prompt技巧,以及攻克RAG、学习Agent搭建等核心技能。作者鼓励读者找对路径、聚焦实操,并通过提

Java开发者的AI Agent学习路径权限控制:Spring Security,原来怎么写,现在还怎么写数据库访问:Spring Data JPA / MyBatis,原来怎么查,现在还怎么查会话管理:Redis,该存的还是存部署运维:Docker + K8s,没变化监控告警:Micrometer + Prometheus,没变化AI能力是新增的,不是替换的。Spring AI的定位就是把大模型
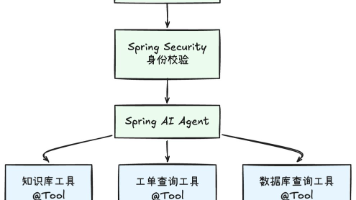
Java开发者的AI Agent学习路径权限控制:Spring Security,原来怎么写,现在还怎么写数据库访问:Spring Data JPA / MyBatis,原来怎么查,现在还怎么查会话管理:Redis,该存的还是存部署运维:Docker + K8s,没变化监控告警:Micrometer + Prometheus,没变化AI能力是新增的,不是替换的。Spring AI的定位就是把大模型
深耕技术行业、或是零基础刚入行的小伙伴应该都深有感触:当下传统互联网、前后端开发岗位内卷愈发严重,求职竞争白热化,简历投递大多石沉大海。不仅新人难入行,老程序员的职业晋升、薪资涨幅也逐渐触顶,职业发展陷入瓶颈。但科技行业早已迎来结构性变革,全新的逆袭风口已然到来!,而在所有AI细分赛道中,凭借落地快、需求大、薪资高的优势,成为2026年增长最迅猛、人才最紧缺的黄金赛道。对于想要跳出内卷、实现薪资职
随着开发工作流日益复杂,掌握现代Agentic AI工具变得至关重要。本文介绍了10款前沿工具,如Goose、Claude Code、Repomix等,它们能理解任务、与代码库交互,自动化多步骤任务,提升开发效率。这些工具不仅适用于代码重构、测试执行,还能处理API交互和文件编辑,是程序员和大模型学习者的得力助手。随着开发工作流变得越来越复杂,你可能会发现,拥有更多工具并不总是奏效。为了完成一个任

AI产品经理转型:从人力资源场景看To B落地的关键逻辑,建议收藏!
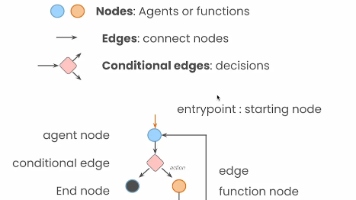
本节课将开启 Agent 开发进阶 —— 聚焦 AI Agent 生态核心框架 LangGraph。LangGraph 以 “有向图” 为底层模型,将 Agent 运行流程抽象为 “功能节点(对应工具调用、逻辑判断等模块)+ 状态流转(定义节点触发条件与数据路径)”,核心优势有三:①结构可视化,便于调试迭代;②高扩展性,新增功能无需重构架构;③原生支持复杂交互,解决多工具调用、多轮对话痛点。课程
你是否也遇到过这样的困境:RAG系统搭载的LLM明明性能强劲,Prompt也经过反复调校,但最终的问答效果却始终不尽如人意——答案要么上下文缺失、逻辑断裂,要么夹杂事实性错误,难以满足需求? 我们或许会优先排查检索算法的效率,或是优化Embedding模型的语义匹配精度,却常常忽略了一个关键环节:数据进入向量库前的文档分块。不合适的分块方式,相当于给后续流程提供了“劣质原料”——要么是顺序错乱的片
本文介绍了如何使用FastAPI框架集成DeepSeek和Qwen大语言模型服务。FastAPI作为高性能Python Web框架,具有快速开发、高效编码等优势。文章详细展示了如何配置API密钥、安装依赖库,并提供了完整的代码实现,通过统一接口调用不同模型服务。最后给出了启动应用和测试接口的方法,帮助开发者快速构建大模型聚合服务。学习大模型技术可把握AI领域发展机遇,解决当前人才短缺问题。
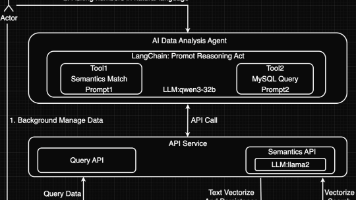
本文介绍了基于LangChain框架的高考信息查询功能重构实践。原方案通过手工流程实现语义匹配、SQL生成、数据查询和结果分析,但存在扩展性不足的问题。采用LangChain框架后,利用其顺序链(SequentialChain)特性,将流程拆分为三个明确步骤:语义匹配表结构、生成执行SQL、分析结果。文章详细展示了代码实现,包括服务初始化、提示模板设计、链式调用构建等关键环节,并演示了"