- @Trb701012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI工程范式快速迭代:从Prompt到Graph的演进 摘要: AI工程领域正经历快速的技术迭代,从Prompt Engineering到最新的Graph Engineering,展现了Agent系统控制边界不断扩展的趋势。文章分析了Prompt、Context、Harness、Loop和Graph五种工程范式的差异与联系:Prompt优化单次模型调用的表达,Context管理输入信息,Harne
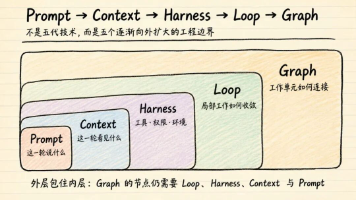
AI工程范式快速迭代:从Prompt到Graph的演进 摘要: AI工程领域正经历快速的技术迭代,从Prompt Engineering到最新的Graph Engineering,展现了Agent系统控制边界不断扩展的趋势。文章分析了Prompt、Context、Harness、Loop和Graph五种工程范式的差异与联系:Prompt优化单次模型调用的表达,Context管理输入信息,Harne
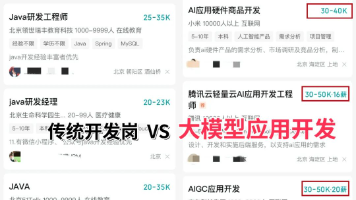
支付宝前端团队转型Agent开发:技术浪潮下的职业新方向 支付宝前端团队集体转向Agent开发的消息引发行业热议,这并非个例,而是技术演进的显著信号。招聘数据显示,AI Agent岗位需求激增,薪资水平跃居行业前列,大厂纷纷布局Agent技术架构。 核心观点: 前端未死,但需升级:纯页面开发岗位式微,具备编程逻辑和架构能力的前端开发者转Agent更具优势。 Agent开发成新风口:其核心是结合大模

支付宝前端团队转型Agent开发:技术浪潮下的职业新方向 支付宝前端团队集体转向Agent开发的消息引发行业热议,这并非个例,而是技术演进的显著信号。招聘数据显示,AI Agent岗位需求激增,薪资水平跃居行业前列,大厂纷纷布局Agent技术架构。 核心观点: 前端未死,但需升级:纯页面开发岗位式微,具备编程逻辑和架构能力的前端开发者转Agent更具优势。 Agent开发成新风口:其核心是结合大模
自学AI大模型是一个长期坚持、循序渐进的过程,没有捷径可走。从数学编程基础到机器学习、深度学习,再到大模型的探索与应用,每一步都需要扎实的积累和反复的实践。小白和程序员们无需畏惧难度,按照这份路线逐步推进,结合自身情况调整节奏,多动手、多思考、多交流,就能稳步踏入AI大模型领域。愿大家在学习路上稳步前行,不断突破自我,早日成为AI大模型领域的实战型人才!对于正在迷茫择业、想转行提升,或是刚入门的程
QCon北京站聚焦AI Agent企业落地,提出Harness Engineering新范式。该理念将传统软件工程与AI特性结合,通过六层架构(上下文管理、工具调用等)构建可信赖的AI系统。核心公式Agent=Model+Harness强调通过外部约束机制优化模型运行环境,解决AI生产痛点。专家指出,Harness Engineering是AI时代的软件工程新范式,标志着从提示词工程到工程化落地的
本文系统梳理了大模型技术的演进路径,将其划分为四个发展阶段:1)基础对话阶段(Prompt、System Prompt);2)模型边界认知阶段(Token、上下文窗口、幻觉);3)实用化阶段(Structured Output、Function Calling、RAG等技术);4)自主化阶段(Agent、MCP、Skill)。文章揭示了各技术间的内在逻辑关系:每个新概念都是为解决前序技术的局限性而
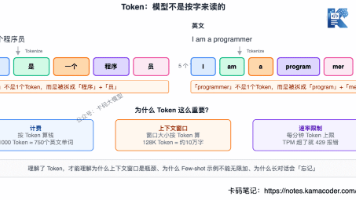
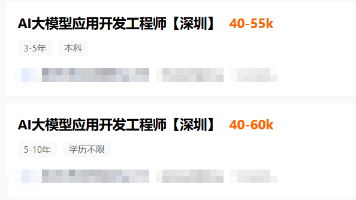
2026年AI大模型人才市场呈现"冰火两重天":互联网大厂一边裁员降本,一边为AI人才开出天价薪资。数据显示,AI岗位平均月薪达6万元,顶尖科学家年薪轻松破百万,但人才缺口仍以每月15%速度扩大。这种高薪现象源于企业战略押注、人才供给不足和资本驱动三重因素。值得注意的是,AI技术发展正在加剧行业分化——掌握技术的人获得高薪,而被AI替代的岗位则面临淘汰。专家预测这种高薪状态可能持续2-3年,建议从
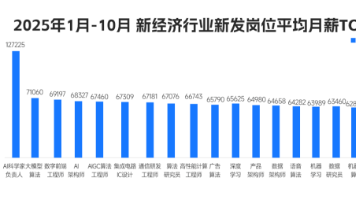
涵盖了数学、编程、机器学习算法、深度学习框架、自然语言处理、Transformer架构、预训练模型等核心知识点,并推荐了丰富的学习资料,包括书籍、在线课程和论文。通过以上七个阶段的学习,您将能够建立起对大规模预训练模型的深刻理解,并掌握其在实际应用中的技巧。人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉高聘发布的《2025年
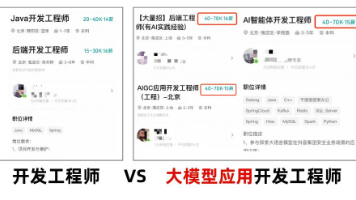
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。