




- @LLand520
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本书为产品经理提供AI产品开发的实用指南,涵盖从机器学习基础到产品落地的全流程。重点包括:1)利用最小资源构建AI产品;2)识别业务场景中的AI机会;3)跨团队协作部署方案;4)平衡ML/DL的成本效益;5)处理数据伦理问题。全书分为三部分:AI管道构建、基础产品开发及现有产品AI集成。适合具备AI基础、希望推动行业数字化转型的从业者,包含大量实战案例和技术框架,助读者在90天内掌握大模型应用、R

本文总结了AI产品经理面试中的18个核心问题,涵盖技术能力、产品策略、用户体验、伦理合规、团队协作等维度,并提供了标准答案和解析思路。技术类问题强调NLP、分布式计算等专业能力;产品类问题关注需求定义和优先级管理;伦理问题突出数据多样性和合规审计;团队协作问题体现敏捷管理和跨部门沟通能力。文章还提供了Google、Amazon等企业的实际面试案例,并附赠AI大模型学习资源包(含学习路线、商业方案、
AI产品经理成长路线:从技术基础到实战能力 摘要:成为优秀AI产品经理需分阶段学习:1)技术基础:掌握AI概念、编程、数据分析和统计学;2)专业技能:深入机器学习算法、产品开发流程、市场分析及商业模式;3)软技能:提升沟通、创新思维和领导力。同时要通过开源项目、实习、比赛和创业积累实战经验。此外,还提供大模型学习路线,涵盖系统设计到行业落地的全栈能力培养,包含104G学习资源包、200本书籍及10
近期有很多社招的小伙伴都在看转行的机会,同时马上要到了秋招的季节,校招生们都在积极选择第一份工作。所有人想要进入一个有前景、高薪高潜力的黄金赛道。2025年如果大家看新机会,重点给大家推荐AI领域的岗位。先看一组数据:

OpenAI 更新了,但不是 GPT-5。这次更新的是一个名为 ChatGPT Agent 的新功能。顾名思义,OpenAI 的野心是让 ChatGPT 不再只是一个“陪聊型 AI”,而是真正进化为一个“会动手”的 AI Agent(智能体)。
《AI大模型学习指南:从入门到就业》报告显示,2025年大模型人才缺口达47万,初级工程师平均月薪28K。报告提供90天速成学习路径:10天掌握基础应用,30天进阶RAG系统开发,30天学习模型训练,20天完成商业闭环。配套资料包含大厂案例库、提示词模板及学习路线图,帮助零基础者快速进入AI领域。报告强调掌握AI工具可提升47%效率并获得34%薪资溢价,现已上传CSDN供免费领取。

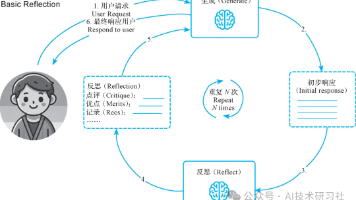
吴恩达在红杉AI峰会上提出四种AIAgent设计模式:反思式Agent通过自我反馈优化任务执行;工具调用型Agent利用外部资源增强能力;规划型Agent分解复杂任务逐步完成;多智能体协作实现团队化作业。这些模式为下一代智能系统提供框架,从单一功能向协同决策演进,标志AI从"工具"向"合作者"转型。文章还包含大模型学习路径和行业趋势分析,指出掌握AI技术将成
《这就是AI智能体》是一本全面介绍AI智能体技术的入门指南,由计算机科学专家张梓铭编写。全书系统讲解了AI智能体的核心原理、技术架构和发展趋势,通过4大模块解析和2个实战项目演示,帮助读者从零基础快速掌握智能体开发技能。书中涵盖17个行业应用场景,配有思维导图和示例代码,适合不同层次的读者学习。多位AI领域专家推荐本书为"理论与实战并重的实用指南",认为它将帮助读者把握2025

OpenAI时隔五年首度开放模型权重,发布1170亿参数的gpt-oss-small-120b和210亿参数的gpt-oss-base-20b两款模型。采用"开放权重"而非完全开源,既保留核心技术又回应社区需求。此举被视为应对Meta等开源竞争的战略调整,开发者可免费部署本地AI应用。新模型支持链式推理,在性能上接近闭源产品,但存在"幻觉"风险。行业分析认为

本文分享了大模型岗位面试经验,包含一面、二面的详细问题及学习资源。一面涉及大模型结构差异、位置编码、RLHF原理等理论问题,以及股票买卖算法题;二面深度考察项目经验、模型对比及评估方法。文章还提供了完整的AI大模型学习路线,覆盖从系统设计到行业应用的7个阶段,并附赠104G学习资源包,包含视频教程、PDF书籍和商业化方案。资源可通过扫描二维码免费获取,适合想入门大模型领域的学习者。
