




- @2401_84815887
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
企业部署AI Agent易陷入误区,本文提出应先寻找适合AI接管的工作场景。以编程场景为例,分析其成为AI Agent最佳落地的原因:输入质量高、输出价值大、反馈及时、上下文可沉淀、工具链成熟。并给出从编程场景倒推其他高价值企业场景的方法,包括数据分析、报价投标、客服、采购、财务、质量异常等。同时强调需规避价值低、反馈慢、输入散、责任边界高的场景,并提供实用的场景筛选评分表及落地步骤,强调AI A
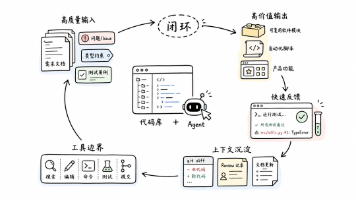
企业部署AI Agent易陷入误区,本文提出应先寻找适合AI接管的工作场景。以编程场景为例,分析其成为AI Agent最佳落地的原因:输入质量高、输出价值大、反馈及时、上下文可沉淀、工具链成熟。并给出从编程场景倒推其他高价值企业场景的方法,包括数据分析、报价投标、客服、采购、财务、质量异常等。同时强调需规避价值低、反馈慢、输入散、责任边界高的场景,并提供实用的场景筛选评分表及落地步骤,强调AI A
本文深入探讨了AI Agent的记忆架构问题,对比人类记忆模型,详细解析了Agent记忆的四个维度:会话记忆、情景记忆、语义记忆和程序性记忆。文章介绍了三层存储架构(热存储、温存储、冷存储)及其技术实现,并分析了主流框架如LangChain、AgentScope、Mem0、Zep和Letta在记忆设计上的特点与优缺点。最后,文章强调了记忆系统对Agent的重要性,以及如何通过设计压缩、遗忘机制和元

本文深入探讨了AI Agent的记忆架构问题,对比人类记忆模型,详细解析了Agent记忆的四个维度:会话记忆、情景记忆、语义记忆和程序性记忆。文章介绍了三层存储架构(热存储、温存储、冷存储)及其技术实现,并分析了主流框架如LangChain、AgentScope、Mem0、Zep和Letta在记忆设计上的特点与优缺点。最后,文章强调了记忆系统对Agent的重要性,以及如何通过设计压缩、遗忘机制和元
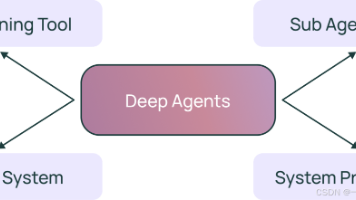
DeepAgents 0.2版本引入"可插拔后端"功能,支持多种文件系统接入,并新增工具结果驱逐、对话历史摘要等优化。作为LangChain的第三个开源库,DeepAgents定位为"智能体工具",与LangChain(框架)和LangGraph(运行时)形成互补,特别适合构建自主性强、运行时间长的智能体,处理复杂非确定性任务。三者技术架构呈层层依赖关系,为不同场景提供灵活选择。
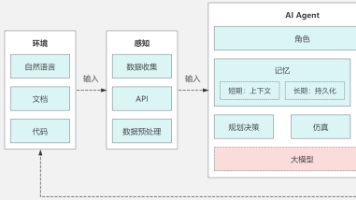
本文详细介绍了智能体开发的完整流程,包括初始化工具、配置大模型、创建智能体和调用执行四步骤。文章讲解了不同Agent类型的选择、Output Parsers的使用技巧,并通过企业官网生成器实战案例演示开发过程。作者提供了从基础概念到代码实现的全面指导,帮助开发者掌握"思考-行动-反馈"循环能力的智能体构建方法,并给出了实用的开发建议。
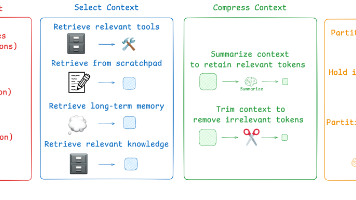
上下文工程是向智能体轨迹每一步填充恰到好处的信息的艺术与科学。文章提出四种主要策略:写入上下文(将信息保存在上下文窗口外)、选择上下文(拉入相关信息)、压缩上下文(只保留必要token)和隔离上下文(分解上下文)。这些方法包括便签本、记忆管理、摘要、修剪、多智能体系统等,是构建高效AI智能体的核心技术。
Qwen3-VL是Qwen系列最强大的视觉语言模型,具有长上下文视频理解(256K-1M)和高级空间感知能力。其采用"视觉编码器+语言模型解码器"架构,通过深度堆栈实现视觉与语言信息的深度融合。模型工作流程包括输入处理、Token融合和深度推理三个阶段,能处理任意分辨率图像和视频,实现了从"模态拼接"到"统一建模"的技术演进。

本文详细介绍了RAG检索增强生成技术,通过Spring AI框架展示如何实现基于本地知识库的AI问答系统。内容包括环境配置、文档读取处理、向量数据库存储、查询增强机制等关键步骤,并提供了完整代码实现与测试案例。文章旨在帮助程序员掌握大模型RAG技术的实际应用,解决传统LLM可能产生"幻觉"或信息过时的问题,提升AI回答的准确性和时效性。
企业用大模型做智能问答时,最怕两件事——要么回答“信口开河”(幻觉),要么说“我不知道”(知识滞后)。这两个问题像卡在AI应用喉咙里的鱼刺:企业不敢把核心知识交给大模型,怕输出错误误导员工;也不敢依赖大模型的“记忆”,怕它跟不上产品迭代的速度。而 RAG(检索增强生成)技术,正是解决这个问题的“镊子”——它让大模型从“闭卷考试”变成“开 卷考试”,用企业自己的知识库当“课本”,回答自然更准、更新。
