
不用Python,从Excel开始:Transformer架构详解与实战(小白必藏)
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。真诚无偿分享!!!vx扫描下方二维码即可加上后会一个个给大家发只要你真心想学习AI大模
01. 没有Python,从Excel开始…
作为一个零基础想要跨领域了解AI的人,学习Transformer就跟拿起单词本开始背“abandon”一样,是一个必要的开机操作。
但是《Attention is all you need》作为一篇极其简练精巧的学术文章,一句话过去就包含了太多的学术界共识,圈外人看起来懵逼实在是太正常了。
但我是这样想的——理论上讲,哪个专业的人不是从头学起的呢?
以稍微看懂Transformer为目标,我绕了很多很多路径去努力接近“AI”这条最热门的登神长阶。
为了厘清一些Transformer存在的背景,我写了Attention前传,从tokenization开始大白话讲一讲Transformer之前发生了什么,把那些隐藏在文章背后的言外之意补充一些:
终于到了这个时刻了,我又再次拿起了《Attention is all you need》!
这是一篇面向非专业朋友的Transformer讲解,会包含以下几个方面:
- Transformer在解决什么问题
- 位置编码
- (多头)注意力机制
- 残差连接和层归一化
- 逐位置前馈神经网络
本文9k字,只包含到Transformer的encoder相关部分。
主要是我尝试在用excel手搓一个Transformer来展示一些计算步骤,这个过程做着做着就额外发现一些细节需要补充,就越来越长。
一次性看起来太累了,decoder相关部分我单独拆开了放到下一篇文章了。主要包含decoder注意力机制的一些轻微变形;在模型“训练阶段”与“推理阶段”一些细微的处理序列数据的差异;一些论文中训练深度网络的其他技术。
如果只想要看Transformer的精华Attention机制的话,可以就看这篇~
虽然拆开了,这篇文章依然很长,感兴趣的朋友建议收藏或者转发~如果比较喜欢这种形式,对于decoder部分也感兴趣的话,不妨点个关注呀。
按照Karpathy大神的话来讲,Transformer架构有着:
- 极强的表达力和灵活性;
- 可以非常容易的利用gradient desent进行优化;
- 极致符合硬件特性可以并行计算。
这三大特点使得它基本上一统江湖,成为称霸多个AI子领域的主流架构。
并且在《Attention is all you need》发表4年之后,大家从原始版本Transformer架构上榨出来的可改进部分依然很少。这个设计有多么优雅就可见一斑了。
今天就想跟大家一起来领略一下Transfomer架构的魅力~
02. Transfomer在解决什么问题?
上篇文章说到“Attention机制”在2015年就被提出,主要是用一个“前馈神经网络”来在训练中自动化地学习“输入序列”与“输出token”之间的“相关性”。这样模型在输出的时候,会更加关注那些跟“当前这一步预测”相关性大的“输入信息”。
但是问题就在于这个Attention机制仍然跟RNN结构结合在一起。RNN“一个token一个token”进行编码的特性天然导致了它计算速度慢,还存在长序列中梯度爆炸和梯度消失的问题。
Attention机制是个好东西,但是怎么把并行度提上来呢?
一个自然的想法就是:我们不把序列一个一个一个输入模型,而是把序列直接摊平,同时处理。额,像说了一句废话,这就是“并行”的定义。
把序列直接“摊平”同时处理会面临两个问题(这两个问题就是曾经用RNNs来解决的):
第一,序列数据的出场顺序是重要的,如果把token摊平处理,顺序这个属性直接就不存在了。像是“Cats ate mice(猫吃老鼠)”和“Mice ate cats(老鼠吃猫)”这种句子,机器就区别不出来了。
第二,我们说过序列数据彼此之间是相互影响的,如果不加任何别的处理,把token分离地输入模型中,模型只会把它们都当成是独立的个体,也就是**模型会直接丢掉上下文信息。**那么“Apple”到底是水果还是手机品牌就分不出来了。
所以要想一个新的解法来应对上面两个困难。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
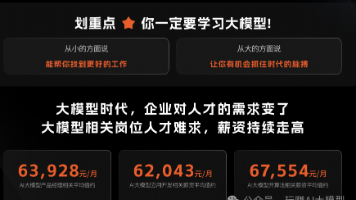
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
03. 顺序问题的解法:位置编码
对于第一个顺序信息丢失的问题,一个最直接的想法当然是把“顺序”重新硬加到原来的编码中去。 问题是怎么编码“顺序”会更加好一点?
如果直接就用“位置编号”作为“顺序”的信息?效果应该不会太好,因为对于自然语言来说,它的语义跟“绝对位置”没有强的关联,跟“相对位置”关联比较大。
拿“This apple is sweet”来举例子,你在这句话前面加上“Ha,”变成“Ha,this apple is sweet”——虽然每个token的绝对位置改变了,但是它们的语义没有产生实质的变化。
我们需要的位置编码要能够表征一定的相对位置关系。Transformer的作者使用了周期性的三角函数来编码位置信息,公式如下:
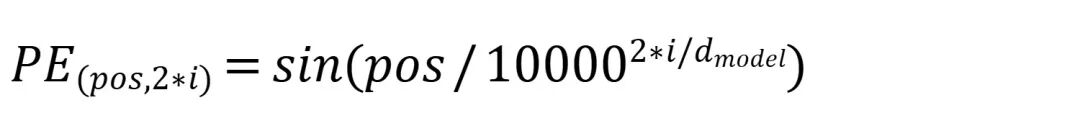
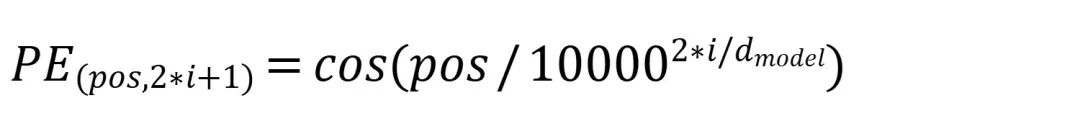
其中PE表示位置编码矩阵(Position Encoding)矩阵;pos表示在序列中token的位置,也是位置编码矩阵的行编号;i表示token embedding向量的第i个维度,2*i和2*i+1也是位置编码矩阵的列编号;d_model表示token embedding向量的维度。
相当于我们为每个token创建一个 d_model 维的位置向量。这个向量的奇数位和偶数位,分别由一对不同频率的正弦(sin)和余弦(cos)函数来填充。从向量的低维到高维,sin/cos 波的波长会越来越长(频率越来越低),从 2π 一直指数增长到 2π*10000。
这么进行位置编码有什么好处呢?
为每个位置提供唯一的编码: 显然,这两个计算公式长得比较刁钻,不同位置的pos值不同,计算出的正弦/余弦组合向量也基本是唯一的。
编码值是有界的: 无论句子有多长,pos 的值有多大,正弦和余弦函数的值域永远在 [-1, 1] 之间。这保证了位置编码的数值稳定性,不会因为句子太长而导致编码值爆炸。
能够泛化到未见过的长度: 模型在训练时可能只见过长度不超过500的句子,但在推理时可能需要处理长度为1000的句子。这个固定的公式可以直接计算出任何长度的位置编码,具有很好的外推性。
最最重要的一点: 让模型能够轻松学习到“相对位置”信息这是这个设计的核心精髓。模型不仅可以知道一个词的绝对位置(比如,在第5位),还可以知道词与词之间的相对位置关系(比如,A词在B词前面3个位置)。
这种对“相对位置”关系的理解源自于这个 sin/cos 组合的神奇数学特性:对于任意固定的偏移量 k,位置 pos+k 的位置编码PE(pos+k) 可以表示为位置 pos 的位置编码 PE(pos) 的一个线性变换(依据是三角函数的积化和差公式)。
还有一点是,这种位置编码让信息在不同频率上解耦了——低频(波长长)的部分可以编码大概的、粗粒度的位置信息,而高频(波长短)的部分可以编码精细的、细粒度的位置信息。模型可以根据需要,从不同维度的信息中学习不同尺度的位置关系。
回到“This apple is sweet”这个例子,位置编码是怎么样的呢?
假设这句话就是被按照词语拆成4个token(实际是按照subword来拆token),且每个token都被embedding成了下面的5维向量:
(注意文中的表格都会在首行会展示矩阵的形状,这里用m表示需要翻译序列的token数量,d_model表示输入的词嵌入维度)
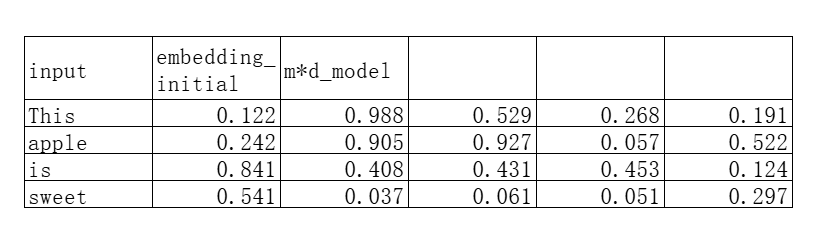
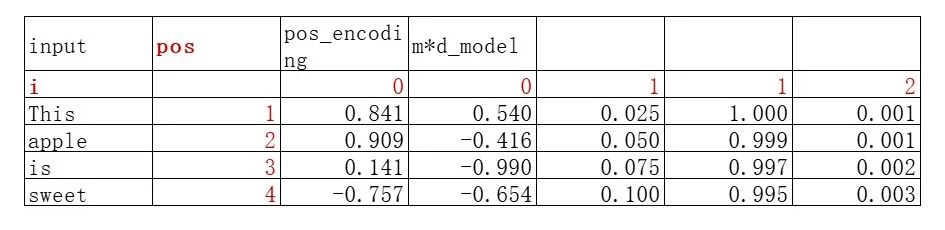
我们现在来计算位置编码矩阵,位置编码矩阵是一个跟初始词嵌入矩阵形状相同的矩阵,为m*d_model维。
对于第一个token“This”来说,它的pos=1,d_model=5;这5个维度分别对应的i是0、0、1、1、2。把这几个数字带入公式就能得到“This”第一个维度的位置编码为:
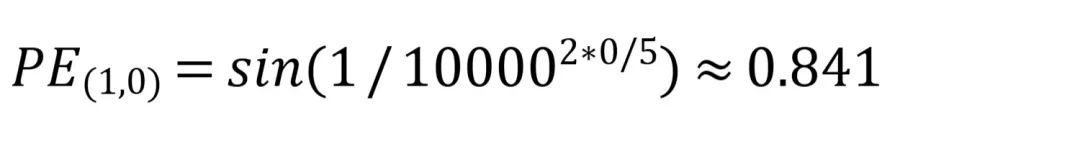
可以计算出整个位置编码矩阵如下所示:
(注意标红的部分不是矩阵元素,只是用于展示计算带入的pos和i值)
把位置编码矩阵跟初始的token embedding矩阵相加就得到了“有位置信息的”token embedding矩阵:
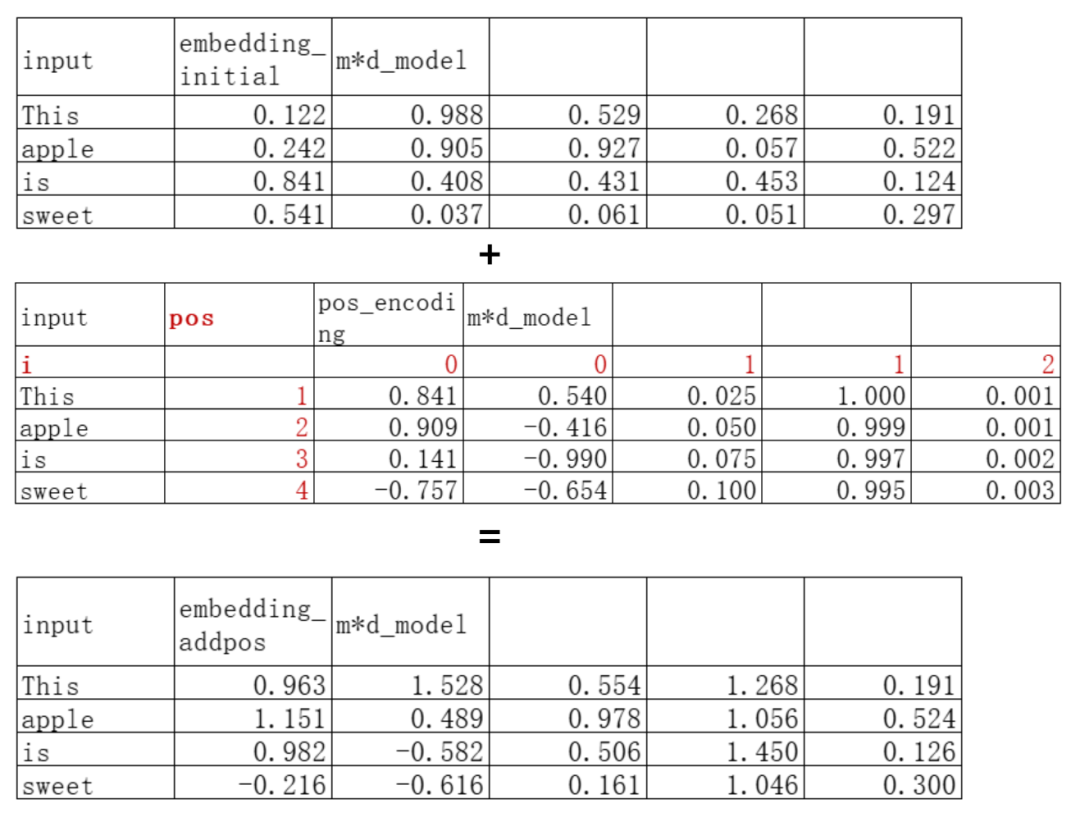
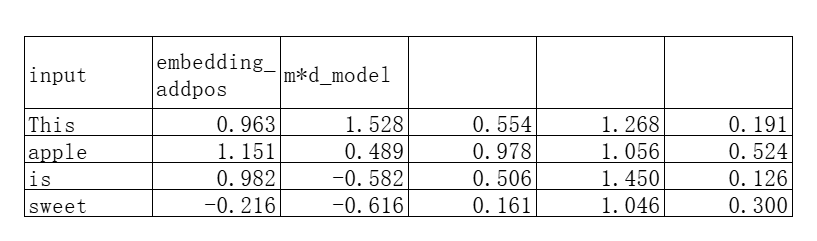
Transformer后续的计算都是在这个“有位置信息的”token embedding矩阵上进行的。
04. 上下文的新解法:并行的Attention
对于第二个问题,当然是通过Attention机制来解决。
独立输入token会丢掉上下文信息,那么“一批”输入,先把彼此的语义通过一层变换融合到自身中去,不就解决孤立这个问题了吗?
你要问怎么融合,当然是按照“相关性”来加权平均了!
论文中的Transformer架构是在完成翻译任务。沿用了机器翻译常用的设计,一个encoder和一个decoder。
为什么要用encoder和decoder?想象一下你自己做翻译的过程就能够理解了。你认真读一句英文的时候,就是把呈现在视觉上的英文字符转化为“脑子里面能够处理的信息”,这就是一种信息的**“编码”转换。**
你理解了这句话的意思,并且把这句话和脑子里面的中文概念对应起来,这个过程也就是把已知信息**“解码”出来并且映射到中文上面去。**从这个角度来说,encoding和decoding的过程无时无刻不在发生,这是一种很常见的模式。
论文在encoder和decoder里面分别用了Self Attention机制,把encoder的信息传递到decoder去的时候还用了一个Cross Attention,所以是Attention is all you need嘛~
接下来看看最为经典的Self Attention,self的意思就是这个Attention过程发生在encoder和decoder模块的内部,两边没有交换信息。
对于encoder来说,它接收到的是一串(模型窗口长度)“需要被翻译的token序列”,这些token是用别人已经embedding好的向量来表达的。
上篇文章说过Attention的思路是:模型需要对每一个token进行处理,“按照‘相关性’把其他token的信息加权平均到这个token身上”,使得它携带上下文信息。
这种token与token之间的相关性,虽然通过embedding能够展示出一部分,但那是脱离具体语境的,是比较宏观的。
要想细化到**“本次输入序列”表达的情境里面,就需要让模型可以通过海量数据学习来捕捉这种相关性——这意味着我们在“找相关性的时候”需要加上可被模型调节的参数矩阵W!**
落实到Attention中,就是作者设计了W_q、W_k、W_v三个参数矩阵来变换输入的向量,分别形成了Q、K、V矩阵。这里Q、K、V矩阵就是把原本token信息进行处理后的一种中间信息。
为什么一连设计了三个变换?我比较喜欢Karpathy大神对这个设计的解读,对于每个token来说:
- K代表的是“我有什么样的信息?”
- Q代表的是“我需要什么信息?”
- V代表着“我在跟别人交流的时候,要提供给别人什么信息?”
这些信息编码的具体方式(也就是W参数矩阵)都是模型要通过训练去学习的。
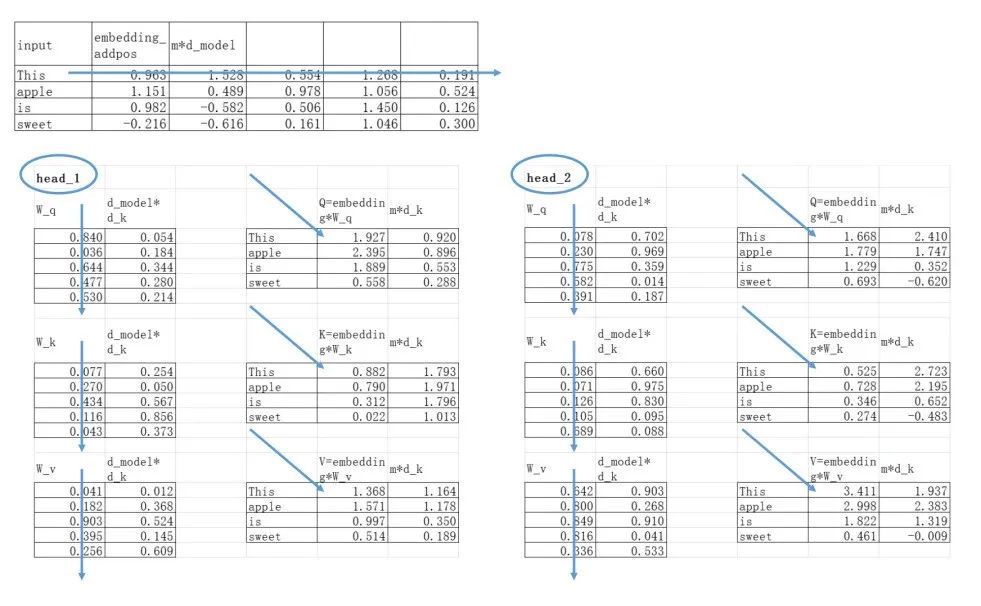
还是接着刚才“This apple is sweet”的例子,我们已经使用位置编码调整了token的embedding向量,得到了:
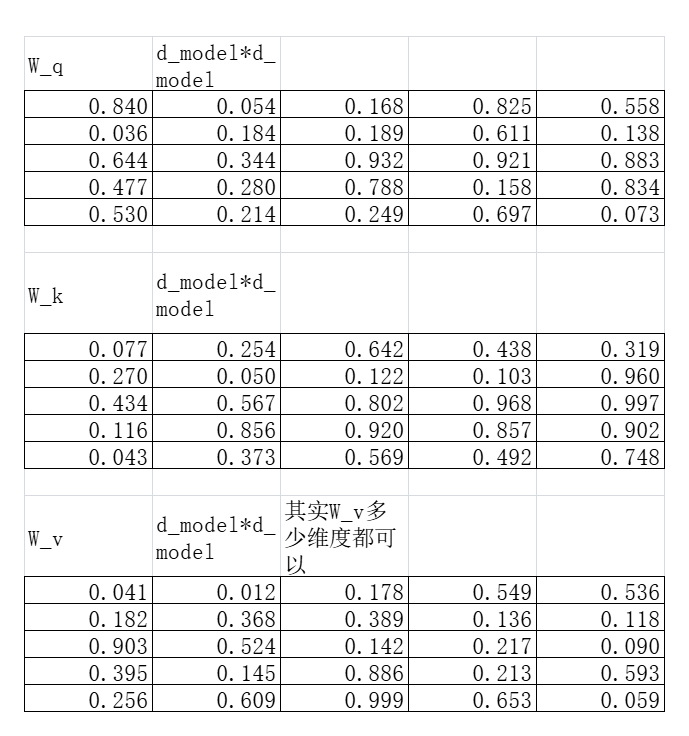
把W_q、W_k、W_v分别随机初始化,我这里用的0-1之间的随机数。
注意看一下这几个矩阵的维度,embedding矩阵为m*d_model,因为我并没有想要把原始的embedding升维或者降维,所以我的W_q、W_k、W_v都为d_model*d_model。
但是其实只要保持W_q和W_k这两个矩阵对齐就可以了,因为后面会用它们两个做运算。W_v的维度是可以修改的。
初始化后的参数矩阵如下:
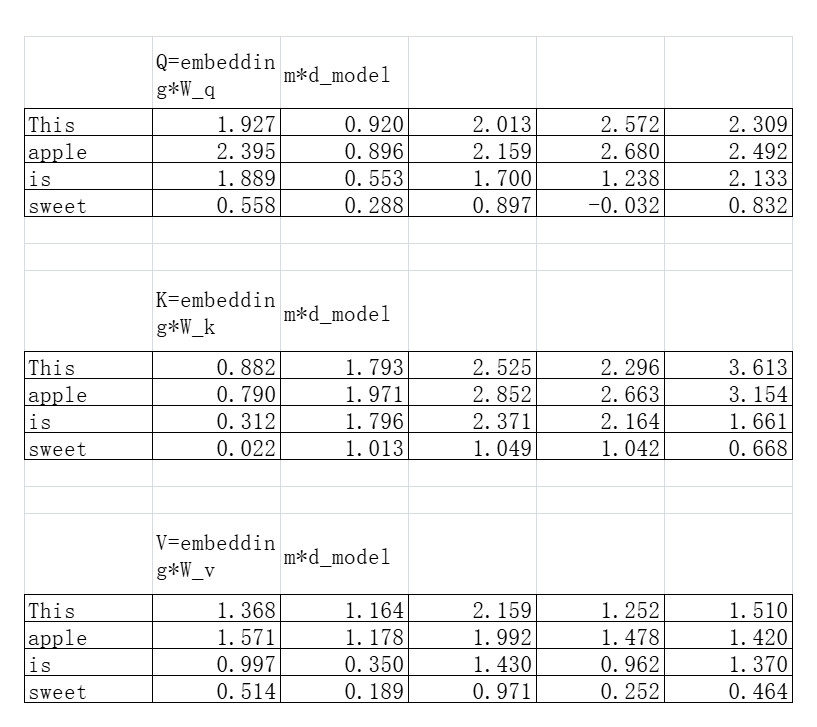
用W_q、W_k、W_v矩阵分别与embedding矩阵相乘,得到Q、K、V矩阵,每行表示token信息的一种处理变换:
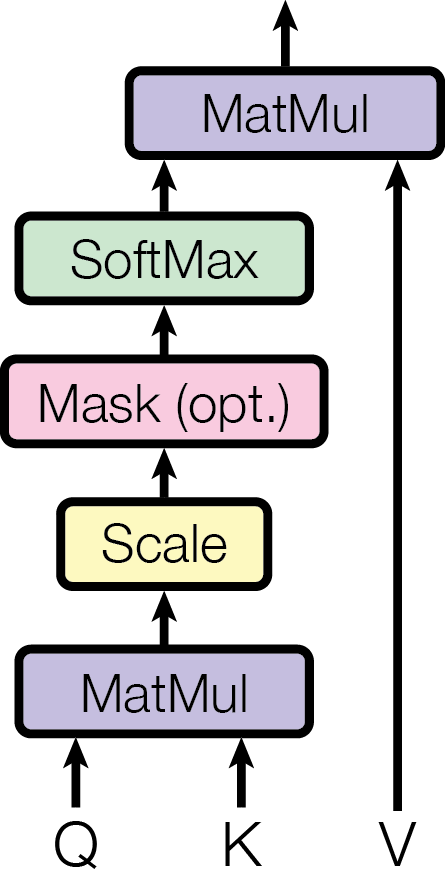
把embedding的向量通过矩阵变换之后,相关性用什么找呢?就是用Q矩阵和K矩阵来找:把每个token**需要的信息“Quries”和每个token拥有的信息“Keys”**相对比,两个向量“越相似”代表“相关度越高”。
向量相似性可以用**“向量的点积”**来衡量。我在Attention前传里面已经介绍过向量可以抽象成高维空间的有向线段。
假设有两个向量a和b,它们的夹角为θ。在向量的长度不变的情况下,向量的方向越接近则两个向量越相似。这种方向的接近性用向量夹角的cos值来衡量,在两个向量方向一致的时候,cos的值达到最大为1。
两个向量的点积,就是两个向量每个维度的数值对应相乘再相加。在数值运算上,向量a和b的点积刚好等于向量a的模长乘以向量b的模长再乘以cosθ。这就是向量的点积可以表征向量相似性的原因。
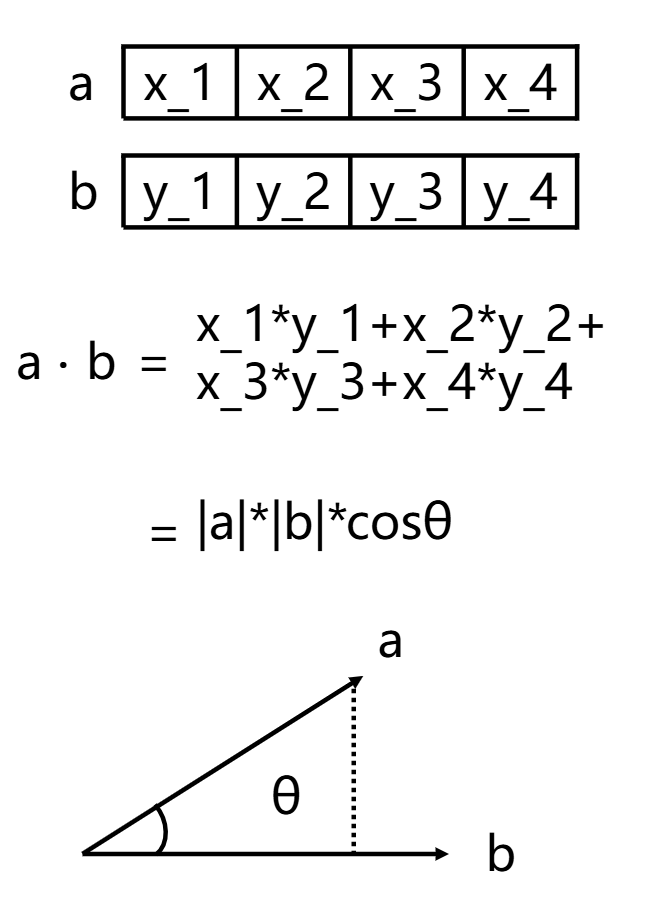
在我们这个Transformer的例子里面,每个行向量代表一个信息,把Q矩阵与K矩阵的转置相乘,就是把任意token两两之间的Quries和Keys做相似度比较,看下每个token需要的信息在谁那里。
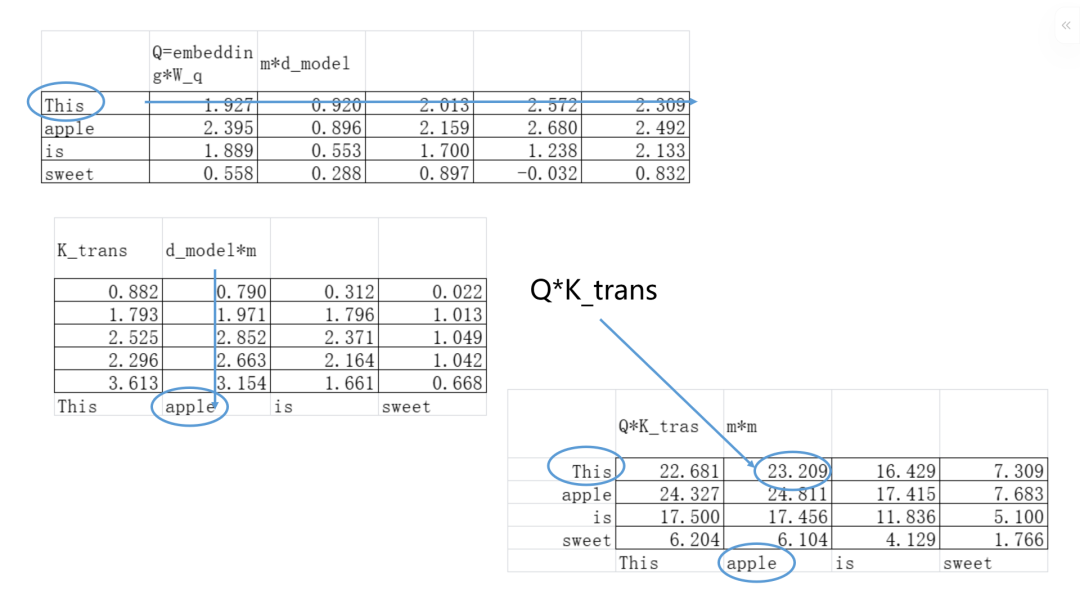
我们现在得到了Q*K_trans矩阵,由于要把信息按照“相关性得分”加权平均,需要使用一个Softmax函数来把这一堆“点积数值”给转化为“0-1之间”并且“和”为1的权重值。
我们前面说向量的点积是跟模长有关系的,向量的维度越高,向量的点积大概率会越大——毕竟只要维度值非零,模长就只会增加。
而Softmax函数又是一个“横坐标绝对值”越大就越平缓的函数。
为了把“相关性权重”给**拉出区分度,**作者用Q*K_trans矩阵除以sqrt(d_model),防止点积值全部堆积在Softmax函数特别平缓的区域。
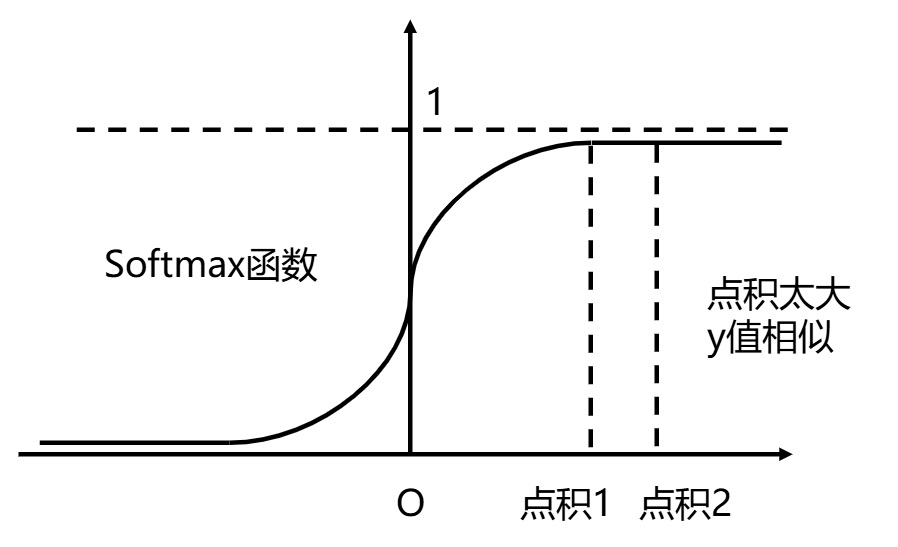
Softmax函数的表达式如下。e_ij表示矩阵里面第i行j列的元素:
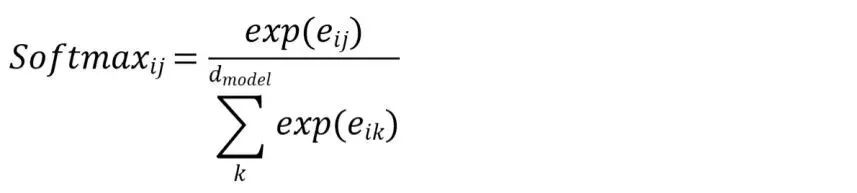

经过了Softmax函数的矩阵如下:
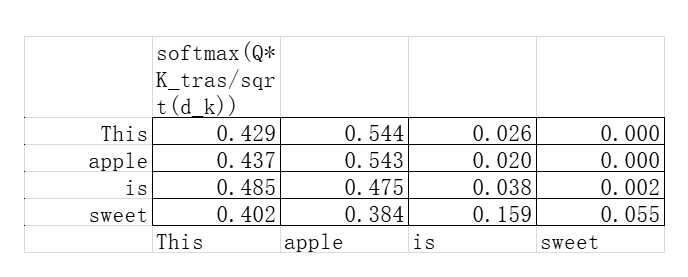
终于我们得到了相关性矩阵!
现在我们把这个相关性矩阵和刚刚变换得到的V矩阵相乘,就得到了加成了上下文信息的embedding。为什么要和V矩阵相乘?V矩阵最开始的设定就是“token对外传递的信息”。
对于单个的token来说,它就是用自己需要的信息Quries,去信息库里面查找,找到跟自己匹配的条目keys,然后就把条目下对应的内容V拿出来使用。
(“This_v”表示“This”token对应的行向量)
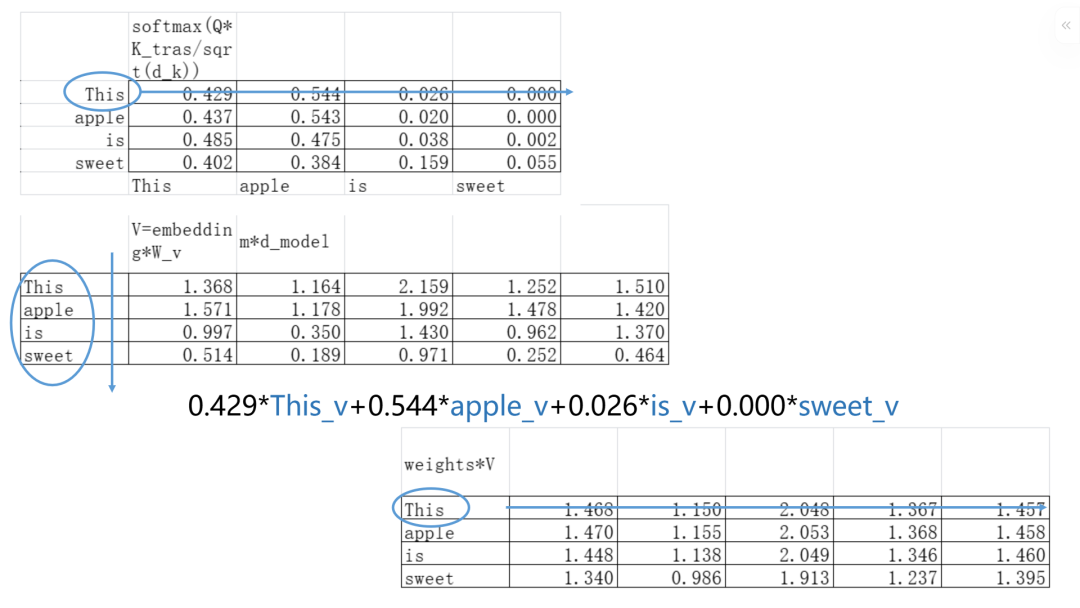
现在,我们把最初4个token的embedding矩阵转换为了含有上下文的新的embedding矩阵。这就是“单个”Attention模块做的事情。
因为整体除以了sqrt(d_model)来做了缩放,所以被称为“缩放点积注意力机制(Scaled Dot-Product Attention)”。
注意我这里介绍的是encoder的Attention,到了decoder的Attention还会有一个mask(掩码)变形,放到后面再说。
05. 多头注意力机制
实现了一次Attention处理其实还不够,作者在论文里面写道,发现“如果使用多个并行的Attention模块来处理信息,会得到更好的模型表现”——就形成了著名的“多头注意力机制(Multi-Head Attention )”。
要怎么理解这件事呢?我觉得已有博主解释得就挺好的:可以把一个Attention Head看成一种理解信息的角度。
就像是我们带着镜片在观察一个物品,一个Attention Head好比只能透出一种颜色的镜片,只透过一个Attention Head去观察就会产生信息漏损。我们就多加几个能够各自透露出不同颜色的镜片,我们观察到的东西就会更加完整丰富。
想象一下,你让一个人(“单头”地)去阅读一句话:“The animal didn’t cross the street because it was too tired.”
这句话中的 “it” 指的是什么?是 “animal” 还是 “street”?
一个“单头”自注意力机制在学习时,可能会努力去学习一种特定类型的关系。比如,它经过训练非常擅长识别指代关系(“it” 指向 “animal”)。但是,这句话里还包含其他类型的关系:
语法关系:animal 是主语,cross 是谓语;语义关系:tired 和 animal 在语义上是相关的,但和 street 无关;位置关系:didn’t 和 cross 是紧挨着的…
对于一个“单头”注意力来说,它只有一次机会去关注这些关系。它最终学到的注意力权重矩阵,必须是所有这些不同类型关系的一个“平均”或“折衷”。这就像让一个专家同时扮演语法学家、逻辑学家和语义学家的角色,他可能哪个角色都扮演不好。
于是作者设置了多个独立的注意力头(比如8个头),让每个头去学习一个特定角度的、更简单的关系。最后再把所有头的“见解”综合起来。就像是创建了多个专家,最后进行专家会诊。
假设我们加了h个Attention Head,那么Attention的结构就会变成下面这样:
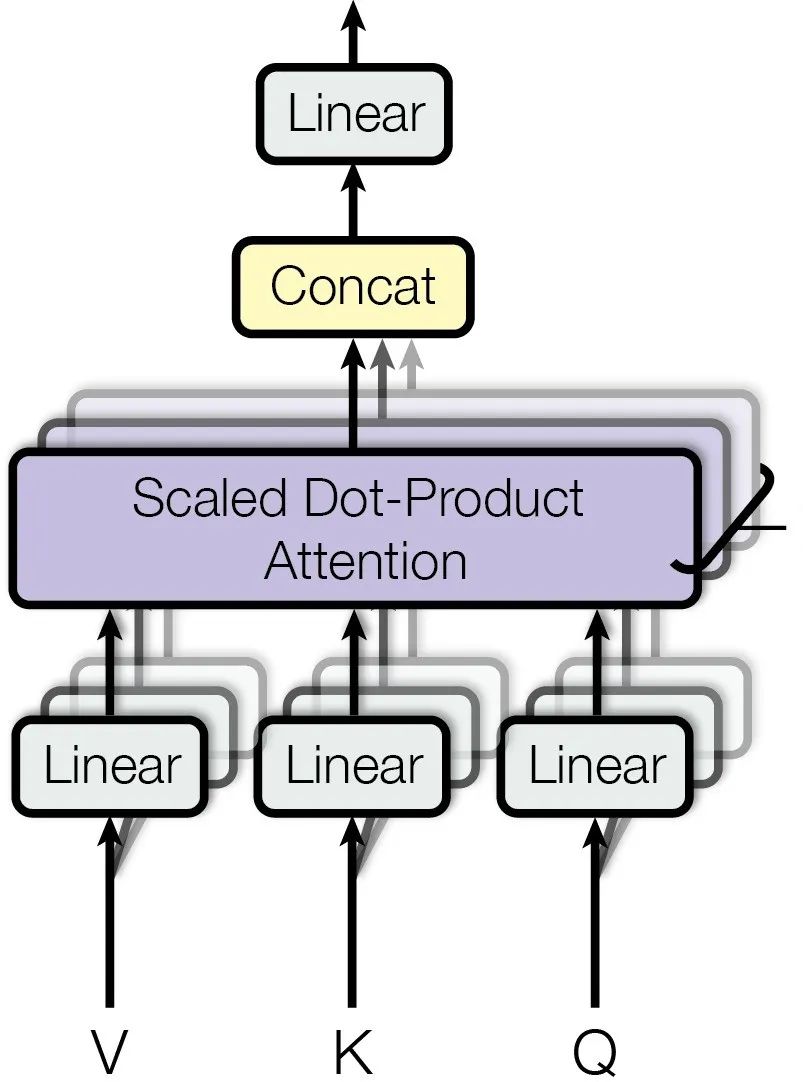
首先要生成多个不同的Head。怎么生成?使用线性变换来做。
给原始embedding矩阵乘以“不同组的”参数矩阵W_iQ、W_iK、W_i^V,就能够形成多个“Q_i、K_i、V_i组”。其中i表示第几个Head,每个Head的线性变换矩阵与其他Head的相独立。
公式如下所示:
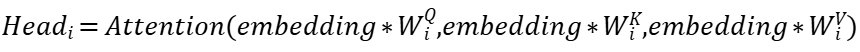

继续拿“This apple is sweet”这个例子来说明,我们假设有3个head(h=3),然后每个token在经过生成head的线性变换之后,从5维变成了2维(d_k=2)。
生成拆分head的线性变换,注意维度:为了降维,线性变换矩阵为d_model*d_k维度。
对于每个head做Attention运算,运算完了之后把3个head得到的最新embedding数据拼接起来成为一个大的矩阵concat:
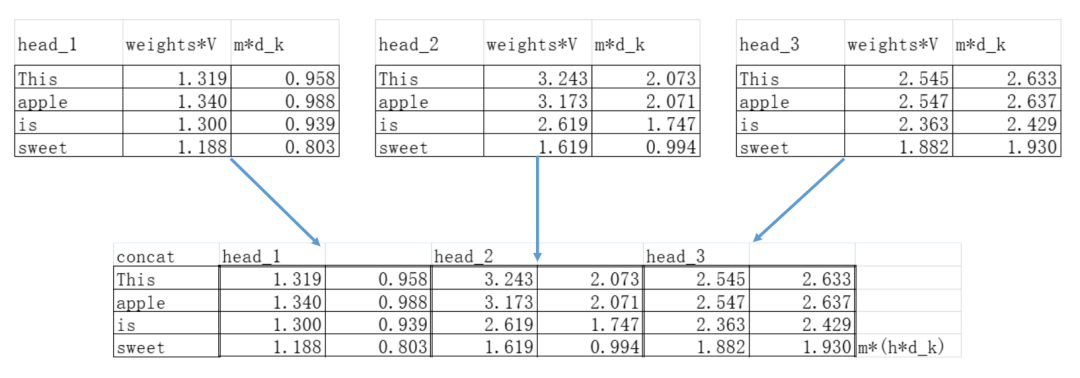
现在相当于把通过多个“镜片”看到的信息“拼接”到一起了,要使得它们“融合”,就再加一层线性变换W_o(记住乘以参数矩阵就等于“让模型自己学习怎么融合”)。
刚好我这里也通过这层线性变换把token的embedding维度还原到原来的维度:
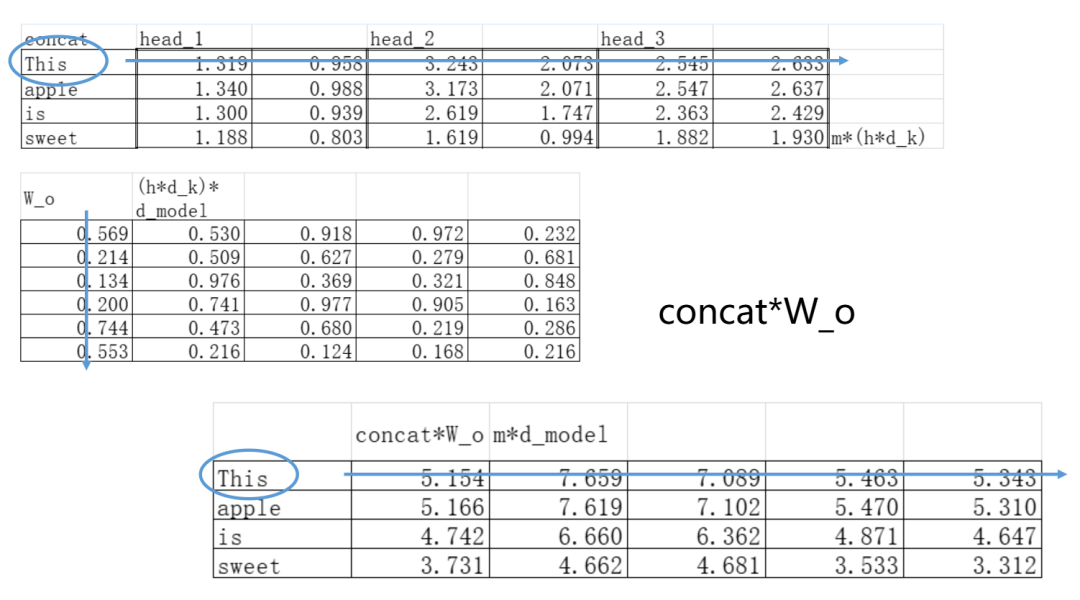
到这里,走完了多头注意力机制的全部流程!实际运行中,多头计算、矩阵计算,全都是并行的,这也是Transformer计算起飞的原因。
06. 牛逼且有效的基操:残差连接和层归一化
作者在Attention模块输出信息之后,还做了两个处理:把Attention模块的输出做残差连接(residual connection)和层归一化(layer normalization)。
这两个操作巧妙又简单,是在训练**“深度”**神经网络中,被实战无数次验证过非常有效的技术。我查了一下,它们各自被提出和发展的路径都很有趣,但是鉴于这篇主要想讲Transformer,我就只简单描述一下,等我有时间再认真研究~
残差连接是指:把A层的“输出”加上A层的“输入”(再给到下一层)。

这样A层学习的实质是——“目标”减掉“输入”之后的残差。这种学习“残差”的形式,比直接学习“目标”要容易训练,能够减少在神经网络的层数叠加太多了之后出现的一种模型学习误差反而增加的神秘**“退化”**现象。
查了一下这也是一篇非常经典且牛逼的论文Deep residual learning for image recognition,感兴趣的朋友可以去看。
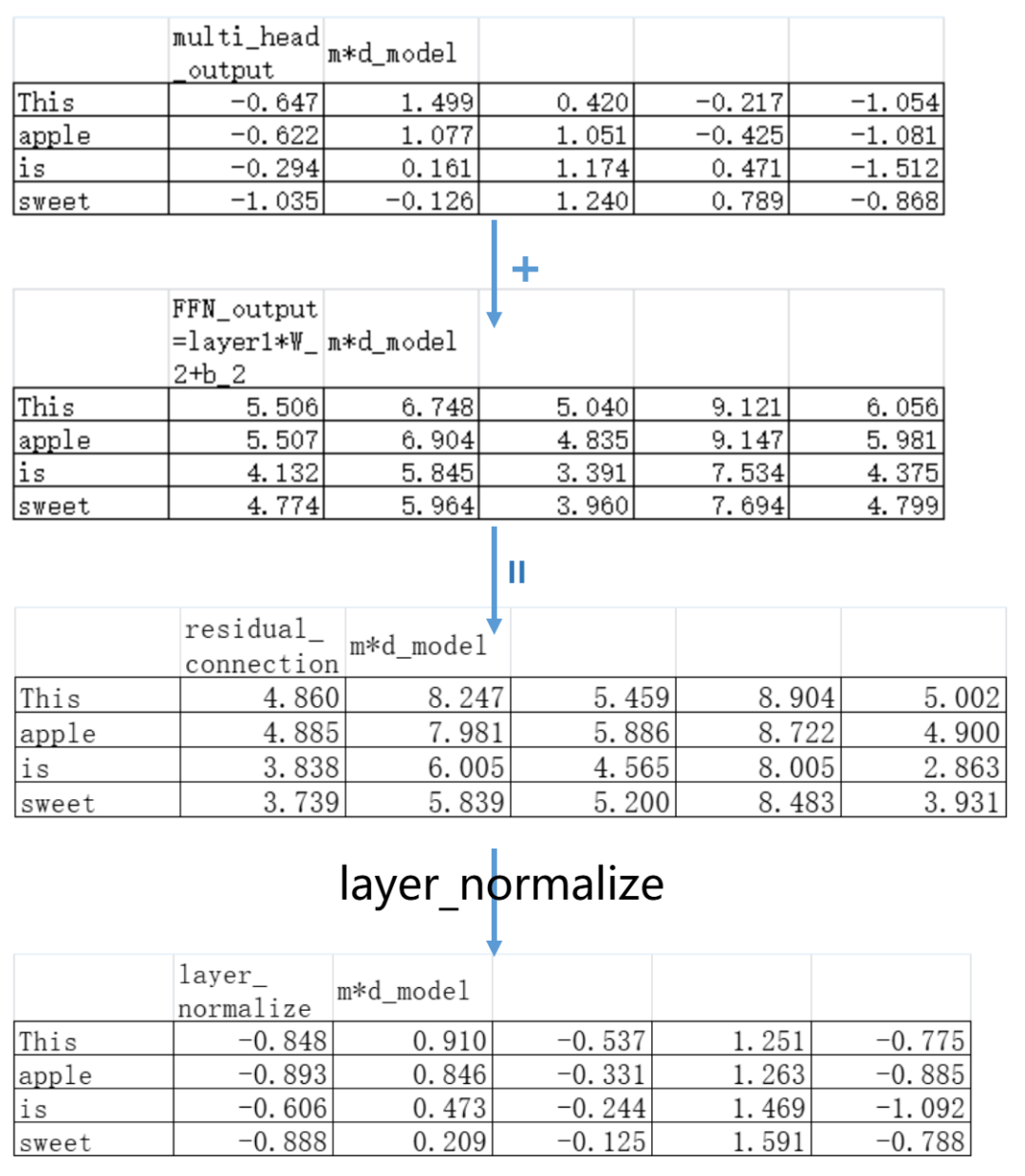
在这里经过Attention层处理之后的矩阵需要加上原始的embedding矩阵:
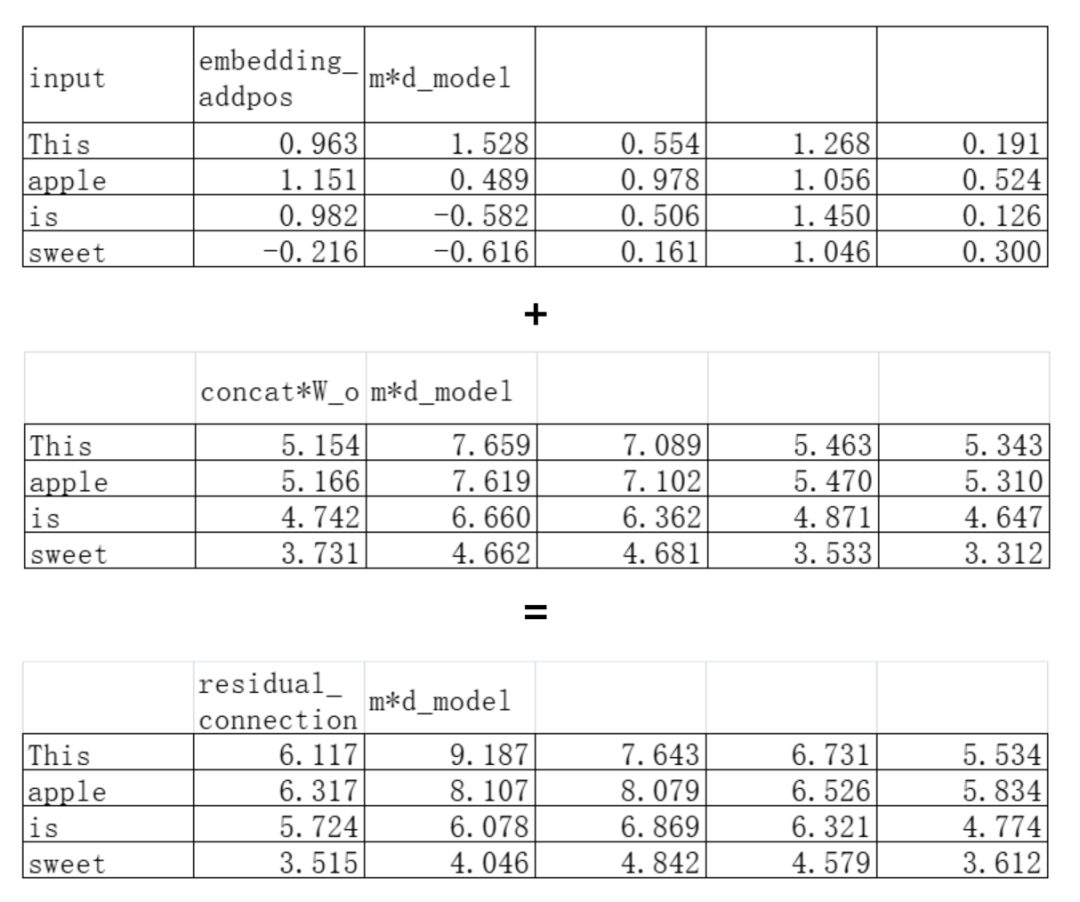
接下来是**层归一化。**假如一个样本X为[x_1, x_2, x_3, x_4, x_5],那么层归一化就做了下面的几个操作:
第一,计算这个向量所有维度的均值(这里就是d_model);

第二,计算所有维度的标准差;
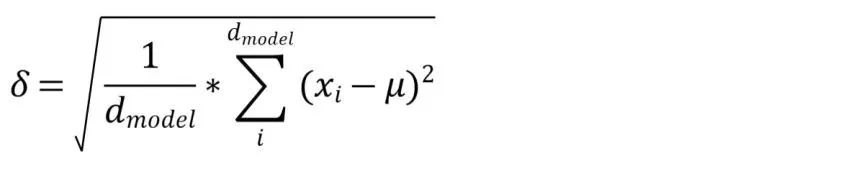
第三,把token embedding向量每个维度都标准化,得到处理后的向量x_hat;这里epsilon是一个非常小的非零常数,加在这里是为了防止分母为零;

第四,增加一个线性变换。记住这个线性变换的参数是学习得到的,最后输出的不是x_hat而是这个线性变换之后的y;

我知道看到这里你的感受一定是,这是在干啥?为什么要这么做?我只了解了皮毛,只能简单介绍一下。
我前面提到了“层归一化”是为了成功训练**“深度”网络**而进行的操作。这是因为在学者们把神经网络的层数越叠越多之后,就发现训练这样一个神经网络非常困难。可能在训练很长一段时间都没有办法收敛。
2015年Ioffe和Szegedy两位大神发表了一篇论文分析了一种可能的原因——内部协变量偏移(ICS,Internal Covariate Shift)。
对于一个深度神经网络来说,后面一层的网络的“输入”是前一层网络的“输出”。但是每训练一次,前一层网络的“参数会更新”,从而前一层网络的**“输出”**也会跟着改变,也就是前一层网络输出的“数据分布”改变了。
后一层网络就需要依据这**“已经改变分布的数据”再次进行学习。然而再下一次,前一层网络的参数又被更新了,后一层网络又再次面对了一个新的数据分布。这样周而复始,整个深度神经网络学习效率很低。**
更麻烦的是,初始神经网络参数更新带来的变动,会随着网络向后层层传播,可能被激活函数逐渐扩大——前面一小点偏移传播到后面就变成了剧烈的波动,**神经网络层级越深越动荡。**收敛不了一点。
怎么办呢?不是数据分布容易变形吗?那就强行把每一层的输出在通过激活函数之前拉回一个标准的分布,再传递给下一层。
但是强行把每一层的输入都变成标准分布,会不会限制了网络本身的学习能力?比如,对于一个Sigmoid激活函数,如果输入总是在0附近(线性区),那它就失去了非线性的能力。
于是学者们又加上了第四步——缩放和平移。γ和β是模型自己学习的参数,它们允许网络自主地决定最佳的分布是什么样的。
这样一来就尽量减少了内部协变量偏移导致的训练困难,又保持了一定的灵活性。在实证数据上也表明normalization是一种有效的加速训练的方式。
(但是也有研究说normalization并不是解决了ICS带来的训练加速,而是通过平滑损失函数的优化曲面带来了好处,这个不是重点就后面再研究了)
现在说回我们“This apple is sweet”的例子,我们就假设缩放和平移参数分别是1和0(也就是保持normalization后的数据分布不动),我们得到下面的矩阵:
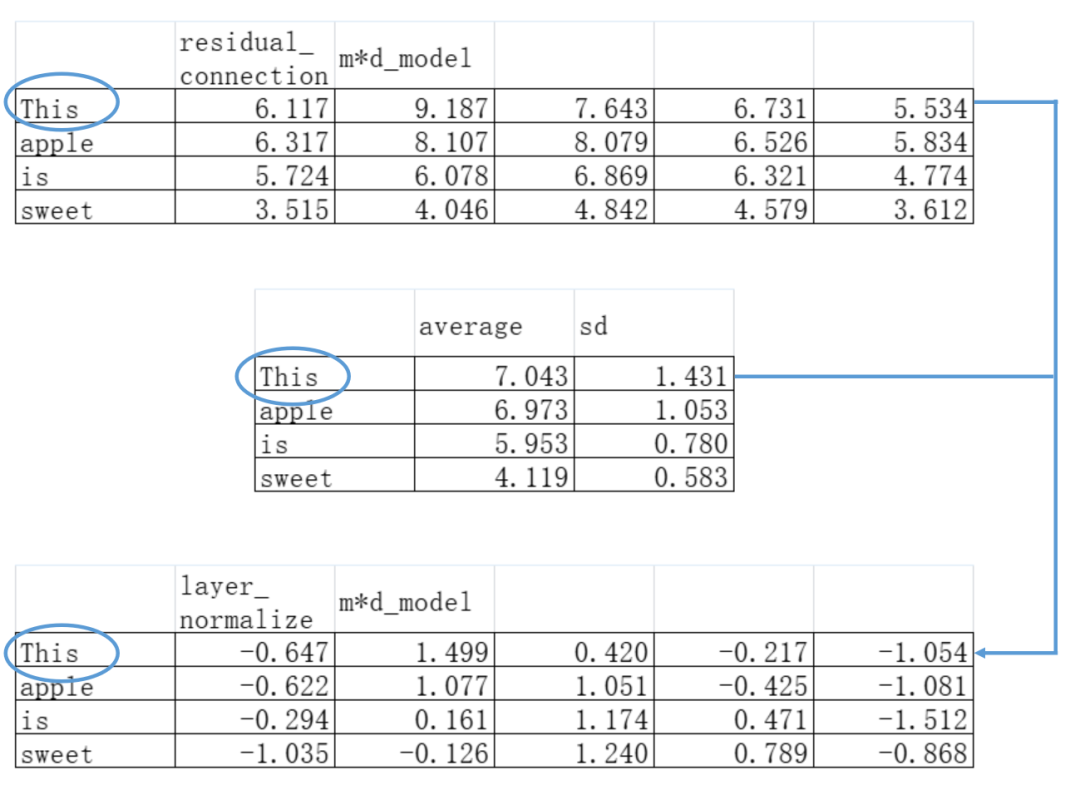
可以看见原本经过Multi-Head Attention变换,再加上残差连接的embedding矩阵已经远远偏离了“均值为0,标准差为1”的标准分布——经过层归一化之后,最最最新版本的矩阵数据已经恢复到0-1附近了。
07. 信息精加工:逐位置前馈神经网络
在经过上述一系列操作之后,作者还在后面加了一层神经网络——**逐位置前馈神经网络(Position-wise Feed-Forward Network, FFN)。**叠上残差连接和层归一化(后续都用add&Norm来简写)。那又是为什么呢?
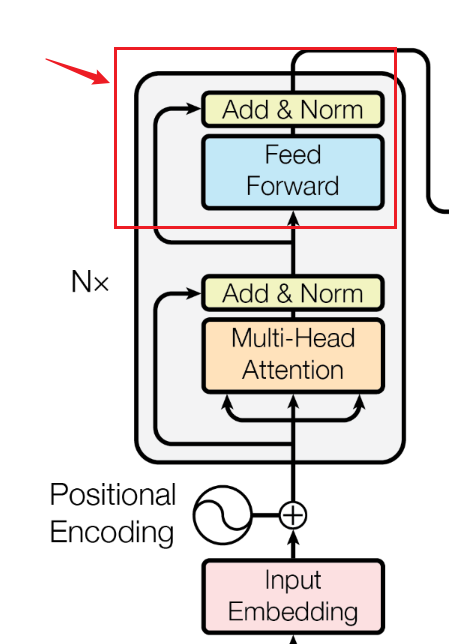
可以看见前面的Attention机制虽然各种变换来变换去,**但基本全是线性变换。**线性变换叠加一万层还是线性变换,解决不了“非线性”的问题。这个新加的神经网络就是来增加模型的非线性的表达能力的。
并且Transformer的前馈神经网络参数是最多的,这本身也扩充了模型的记忆和学习能力。
我先介绍一下它是怎么做的。Transformer里面的前馈神经网络有两层:
第一个线性层 (Expansion):将输入向量的维度从 d_model(例如 512)扩展到一个更大的维度 d_ff(例如 2048)。
ReLU 激活函数:对扩展后的向量进行非线性变换。
第二个线性层 (Contraction):将向量的维度从 d_ff(2048)收缩回原始维度 d_model(512)。
用表达式来描述如下,x表示Attention层输出的某个token最新行向量,W_1、b_1、W_2、b_2是参数矩阵:
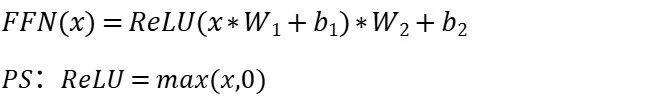
注意这里针对于每个token行向量,W_1、b_1、W_2、b_2都是相同的!
相当于这两层前馈神经网络只处理单个token行向量上的信息,**不会受到其他token的影响,**这跟加权平均其他token的Attention机制刚好是相反的。
让Gemini解释得到的比喻我觉得很有道理:
想象一条工厂流水线。
Multi-Head Attention层就像一个“信息组装工位”。它把传送带上各个零件(单词)的信息拿过来,相互比对、组合,然后给每个零件打上一个包含了其他零件信息的“综合标签”。
FFN 就像流水线上的一个“质检与加工站”。**它不关心别的零件,**只拿起当前这一个带“综合标签”的零件,用一套标准流程(固定的 W 和 b)**对它进行打磨、检测、深加工,**让它变得更符合最终产品的要求。然后把它放回传送带,接着用同样的标准流程处理下一个零件。
Multi-Head Attention层负责横向的、跨位置的信息交互和聚合。它的任务是搞清楚句子中“谁和谁”有关系,关系多大,然后把这些关系信息汇总到每个单词的表示中。
FFN 层负责纵向的、逐位置的信息深化和加工。它不关心其他位置,只专注于处理当前这一个位置接收到的、已经融合了上下文的复杂信息,通过非线性变换提取更高级的特征。
回到我们“This apple is sweet”的例子。我们原始的token embedding维度为5,假设用前馈神经网络先扩展到10维(d_ff=10),然后再回到5维。
这个时候我们第一层参数矩阵形状应该为d_model*d_ff,得到升维后的embedding矩阵形状为m*d_ff:
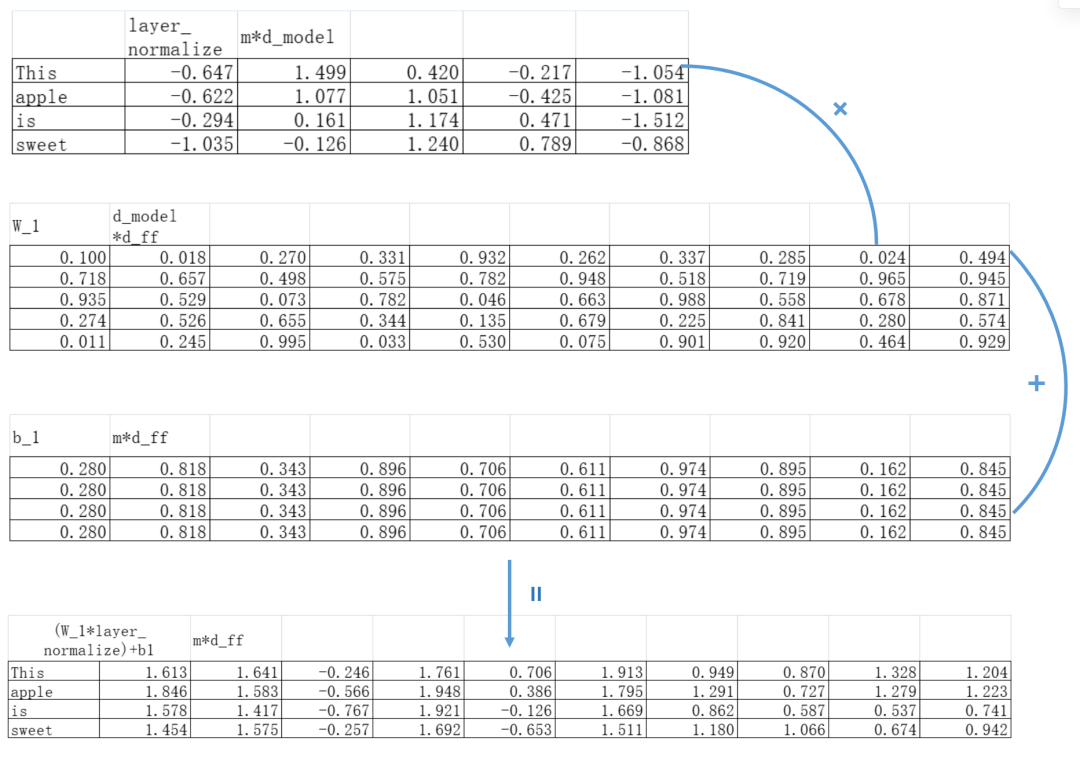
我们把第一层线性变换后得到的矩阵套上一个ReLU函数得到:

然后把这个经过了ReLU函数的矩阵放入第二个线性变换。第二个线性变换要把embedding矩阵的维度恢复,第二个线性变换W_2的形状为d_ff*d_model。经过第二层变换的矩阵形状为m*d_model。
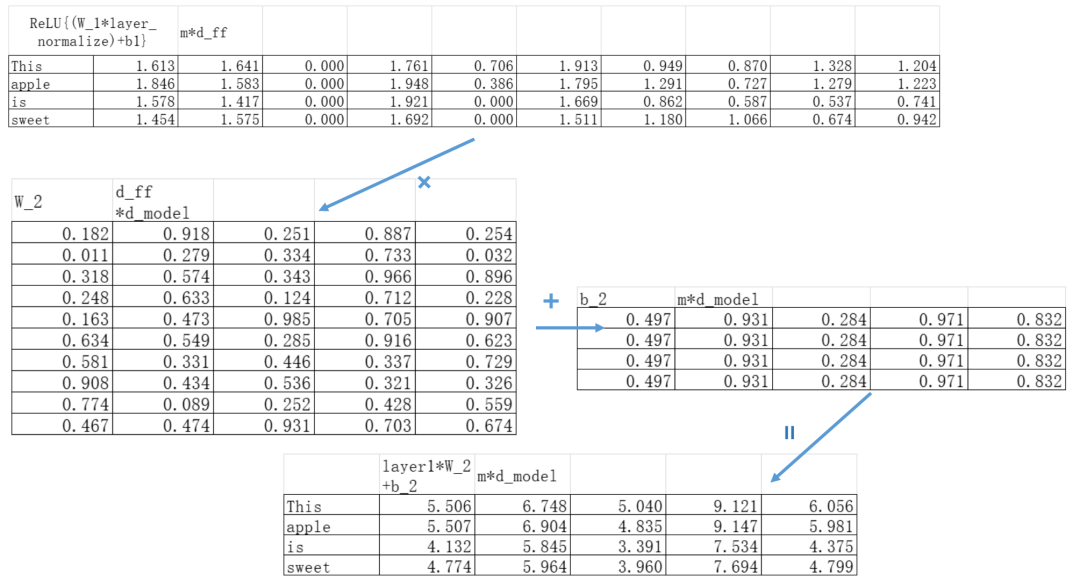
到这里前馈神经网络的操作就完成了!
不过我们可以看见最后得到的这个矩阵,因为经过了多层的变换,它的数值早就偏离了标准分布。为了更好地深度训练,在前馈神经网络后面依然接了一个残差连接和层归一化(add&Norm)。
这样Transformer encoder的“一个基本模块”就完成了,再看一眼encoder的架构图:
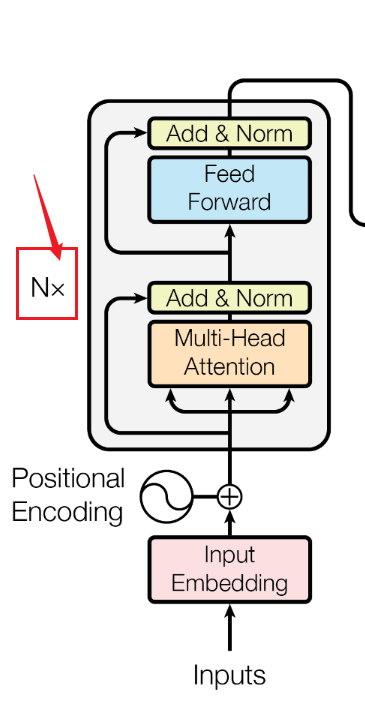
看到旁边那个被框起来的N了吗?N代表着这样的基本模块在Transformer encoder中有N个,前一个的输出是后一个的输入。
整个Transformer encoder是在Multi-Head Attention(add&Norm)->FFN(add&Norm)->Multi-Head Attention(add&Norm)->FFN(add&Norm)…不断循环处理信息的。
最后一个基本模块的输出才是encoder的输出。在Transformer论文中encoder有6层喏~(变形金刚名不虚传,bushi)
不断堆叠这种encoder基础模块有什么用呢?就跟CNN相似,CNN的第一层卷积可能学习到的是识别直线,中间的层次可能学会识别轮廓,高级层次学会识别人脸…
Transformer encoder的低级层次可能学习指代关系、句法关系;中级层次学会句子组合;高级层次学会全文主题抽象…虽然实际上每个层次在学习什么很难显式形容,但是越高级的层次学会的是越抽象的东西。
Transformer论文里面叠了6层只是作者在算力和效果权衡得到的结果,算力足够的话就像后来的Bert、ChatGPT这种大模型一样,可以叠加非常深的层次。
08. 小结
《Attention is all your need》这篇论文的核心贡献之一就是,发现自然语言任务可以直接抛弃类RNN或者CNN结构。
它用极其经典的Attention设计极大地提升了训练的并行度,减少了训练的时间,极致地利用了训练的物理资源(也就是一张卡跑得很满)。
除此之外,设计了适应力和表达力都很强的简洁的位置编码公式,解决了并行处理掉丢位置信息的问题。
丝滑融合了残差链接和层归一化这种针对深度神经网络的训练优化技术,让模型具备很深的层数,也就意味着模型有很强的学习抽象能力。
“Attention”和“逐位置前馈神经网络”交替出现,让Attention机制不断横向捕捉上下文关系,让逐位置前馈神经网络不断纵向总结被上下文加成的信息,配合达成学习效果。
这篇文章写得比我想象中长,因为在尝试用表格手搓的过程中发现很多细节。我尽力从一个"处理问题"的角度去描述Transformer,尽力把我对于设计的一些疑问用问答的方式展现出来。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。
希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容
-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集
从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)
07 deepseek部署包+技巧大全
由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐
 20
20 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)