- @2401_84495872
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
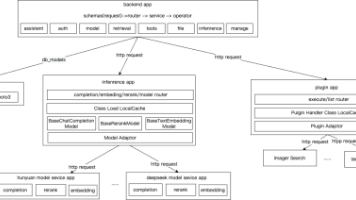
本文介绍了一个开源AI Agent全栈开发项目,采用Next.js框架,结合PostgreSQL、LangChain等技术栈,实现Agent和Workflow两种模式,具备RAG、网页搜索等功能。针对AI领域人才缺口大的现状,作者分享了从入门到实战的AI大模型学习资源包,包含视频教程、学习路线、面试题解等,助力开发者转型AI高薪岗位。资料可免费领取,适合零基础学习者、应届生及传统开发者提升AI技能
本文介绍了一个开源AI Agent全栈开发项目,采用Next.js框架,结合PostgreSQL、LangChain等技术栈,实现Agent和Workflow两种模式,具备RAG、网页搜索等功能。针对AI领域人才缺口大的现状,作者分享了从入门到实战的AI大模型学习资源包,包含视频教程、学习路线、面试题解等,助力开发者转型AI高薪岗位。资料可免费领取,适合零基础学习者、应届生及传统开发者提升AI技能
AI Agent时代:普通人如何抓住机遇? 2024年被视为“AI Agent元年”,比尔·盖茨称其为计算机领域的第三次革命。AI Agent不仅能回答问题,还能自主完成复杂任务,如邮件处理、市场调研和社交媒体运营。 普通人机会: AI Agent训练师:调教AI适应业务场景,高薪稀缺岗位。 个人创业:利用AI Agent实现自媒体、电商等单人高效运营。 垂直领域解决方案:为行业定制AI工具(如法

AI Agent时代:普通人如何抓住机遇? 2024年被视为“AI Agent元年”,比尔·盖茨称其为计算机领域的第三次革命。AI Agent不仅能回答问题,还能自主完成复杂任务,如邮件处理、市场调研和社交媒体运营。 普通人机会: AI Agent训练师:调教AI适应业务场景,高薪稀缺岗位。 个人创业:利用AI Agent实现自媒体、电商等单人高效运营。 垂直领域解决方案:为行业定制AI工具(如法
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。✅从入门到精通的全套视频教程✅AI大模型学习路线图(0基础到项目实战仅需90天)✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实
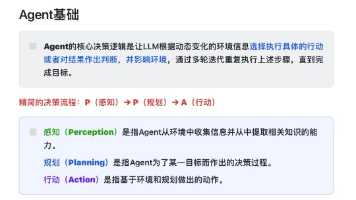
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。✅从入门到精通的全套视频教程✅AI大模型学习路线图(0基础到项目实战仅需90天)✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实
本文详细介绍了智能体平台的定义、特点及8大主流平台(Coze、Dify、n8n等)的功能特点和适用场景。文章区分了智能体与聊天机器人的不同,阐述了平台的核心组件,并根据不同用户需求提供了选择建议。作者鼓励读者通过实践学习,并计划围绕Coze、Dify、n8n三个平台展开系列教程,帮助小白和程序员从入门到掌握AI智能体开发。
ACE框架通过生成器、反思器和整理器三大组件,构建自进化上下文管理系统,解决智能体开发中的简洁性偏差和上下文坍缩问题。该框架采用增量式、结构化知识管理,让AI Agent持续学习而不丢失关键信息,性能最高提升18%,大幅降低开发成本,使普通开源模型能与顶级工业智能体媲美。
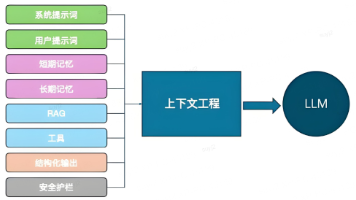
本文详细对比分析了三大智能体开源平台:Coze(零代码AI Bot开发)、Dify(企业级LLM应用)和n8n(工作流自动化)。从开发主体、产品定位、技术路线、核心用户群等维度进行全面比较,并提供了各平台的实践案例和典型应用场景的推荐平台。帮助开发者根据团队技术栈和业务需求,快速选择适合的智能体开发框架,实现AI应用的快速落地。
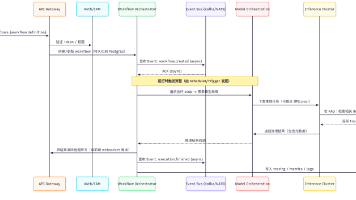
本文深入解析了企业级AI智能体开发平台Tasking AI与Dify的系统架构与核心能力。对比了两类平台的设计思路:Tasking AI以简洁微服务架构适配轻量需求,Dify则凭借异步化处理和GraphEngine任务编排引擎支撑复杂场景。文章详细拆解了四大核心能力:状态管理、模块化组件、多租户隔离与任务编排,并从用户提问到输出的完整流程展示了平台如何实现AI应用全流程开发,为开发者提供了企业级A