
2025年大模型学习路线图:从入门到精通,程序员进阶必备,一篇掌握未来技术!
文章提供大模型学习的系统路径,涵盖数学基础、编程技能、Transformer架构、预训练微调技术、RAG系统开发等核心知识点,并提供90天学习计划。强调实践导向,推荐从基础理论到实际应用的渐进式学习,关注开源动态和工程实践,帮助开发者系统构建大模型知识体系,加速学习进程并规避常见陷阱。
简介
文章提供大模型学习的系统路径,涵盖数学基础、编程技能、Transformer架构、预训练微调技术、RAG系统开发等核心知识点,并提供90天学习计划。强调实践导向,推荐从基础理论到实际应用的渐进式学习,关注开源动态和工程实践,帮助开发者系统构建大模型知识体系,加速学习进程并规避常见陷阱。
引言
当前大模型技术发展迅猛,掌握其核心成为开发者进阶的关键。面对广阔而复杂的学习领域,如何高效入门并深入?本文提炼出一套结构化的大模型学习路径,源于实践总结,旨在帮助您系统构建知识体系,加速学习进程,规避常见陷阱。

一、基础准备阶段
目标:建立数理与编程基础,掌握机器学习核心概念
- 数理基础
- 微积分/线性代数:理解梯度下降、矩阵运算(推荐:3Blue1Brown《线性代数本质》)
- 概率统计:掌握分布、假设检验(资源:可汗学院概率统计)
- 计量经济学(可选):用于经济/金融数据分析
- 编程与工具
- Python核心:NumPy、Pandas、Matplotlib
- 深度学习框架:PyTorch(官方教程)、TensorFlow
- 机器学习基础
- 经典教材:周志华《机器学习》(“西瓜书”)+《南瓜书》公式解析;李航《统计学习方法》
- 课程:吴恩达机器学习(Coursera)、Scikit-Learn实战
- 核心算法:线性回归、决策树、SVM、聚类
二、核心进阶:NLP与大模型技术
目标:深入Transformer架构,掌握预训练与微调技术
- Attention与Transformer
- 论文精读:《Attention Is All You Need》
- 代码实践:复现Transformer(Pytorch实现
- 关键组件:位置编码、多头注意力、FFN(HuggingFace课程)
- BERT/GPT分支模型
- BERT:双向预训练、微调任务(掩码语言模型)
- GPT:自回归生成、因果语言建模(HuggingFace实战)
- 嵌入模型进阶:Sentence-BERT → GTE/GTE
- 大模型训练与优化
- 预训练:数据构建、分布式训练(LLM Pretraining指北)
- 高效微调:LoRA/Adapter/P-tuning(框架:LLaMA-Factory)
- 推理优化:量化、FlashAttention、模型压缩(LLM推理优化技术纵览)
三、应用实战:开发与部署
目标:构建RAG/Agent系统,解决工业级问题
- 大模型应用范式
-
框架:LangChain、Dify
-
案例:金融数据分析、客服机器人(AgenticRAG代码库)
-
框架:LlamaIndex + LangChain
-
优化策略:12种流程优化(参考《最全RAG技术概览》)
-
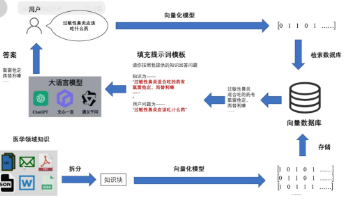
RAG(检索增强生成):
-
Agent开发:
- 强化学习对齐
- RLHF:PPO算法(源码解读)
- DPO/GRPO:直接偏好优化(DeepSeek-V2/V3采用)
- 多模态扩展
- 技术路线:CLIP(对齐)→ LLaVA(MLP融合)→ Qwen-VL(视觉编码器优化)
- 实战:多模态微调(Qwen-VL微调指南)
四、前沿与拓展
- 模型架构演进
- 闭源:GPT-3 → GPT-4
- 开源:LLaMA-3 → DeepSeek-V2/V3 → Qwen-MoE
- 高阶主题
- 图学习:GraphRAG(全局摘要生成)
- 合成数据:人工数据增强(BetterSynth工具)
- 系统优化:CUDA加速、Orca调度
学习路线图与资源
| 阶段 | 核心资源 |
|---|---|
| 基础 | 吴恩达机器学习(Coursera)、PyTorch教程、《统计学习方法》实战代码 |
| 进阶 | HuggingFace NLP课程、李沐Transformer精读、《大规模语言模型:从理论到实践》 |
| 应用 | LangChain文档、OpenAI Cookbook、LLaMA-Factory微调框架 |
| 前沿 | 清华大模型公开课、State of GPT演讲、AIGC论文精读(Arxiv最新) |
关键建议:
- 先跑通再深挖:用HuggingFace快速部署模型,再研究源码(如GPT-2复现)
- 问题驱动学习:从Kaggle比赛/RAG项目切入,反向补足理论
- 关注开源动态:DeepSeek/LLaMA/Qwen的技术报告比论文更贴近工程实践
附:工具栈速查表
- 开发:VS Code + Jupyter
- 模型:HuggingFace Transformers + ModelScope
- 微调:LLaMA-Factory + DeepSpeed
- 部署:vLLM + TensorRT-LLM
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 21
21 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)