
【必学收藏】大模型驱动的智能代码评审:Dify+GitLab+DeepSeek完整实践
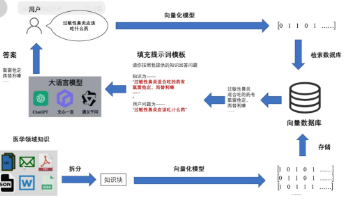
文章详细介绍了如何基于Dify+GitLab+DeepSeek-V3.2-Exp构建企业级智能代码评审系统,解决了传统评审效率低、标准不统一的问题。通过vLLM私有部署和提示词工程实践,实现了代码提交→自动评审→结果反馈的全流程自动化,使评审效率提升15倍,问题检出率提高35%。文章还提供了多模型融合策略和与现有系统集成方案,帮助企业实现代码评审智能化转型。
引言:代码评审的痛与AI解决方案
传统代码评审正面临三大挑战:人工效率低下(平均每PR耗时45分钟)、标准不统一(不同评审员检出率差异达40%)、知识沉淀困难(评审经验难以复用)。麦肯锡《人工智能驱动的下一次创新革命》报告指出,AI可将研发生产力提升300%,生成式AI能自动完成60%的重复性代码审查工作。
本文将详解如何基于Dify+GitLab+DeepSeek-V3.2-Exp构建企业级智能评审系统,重点介绍vLLM私有部署方案及大模型提示词工程实践,帮助团队实现代码提交→自动评审→结果反馈的全流程自动化。
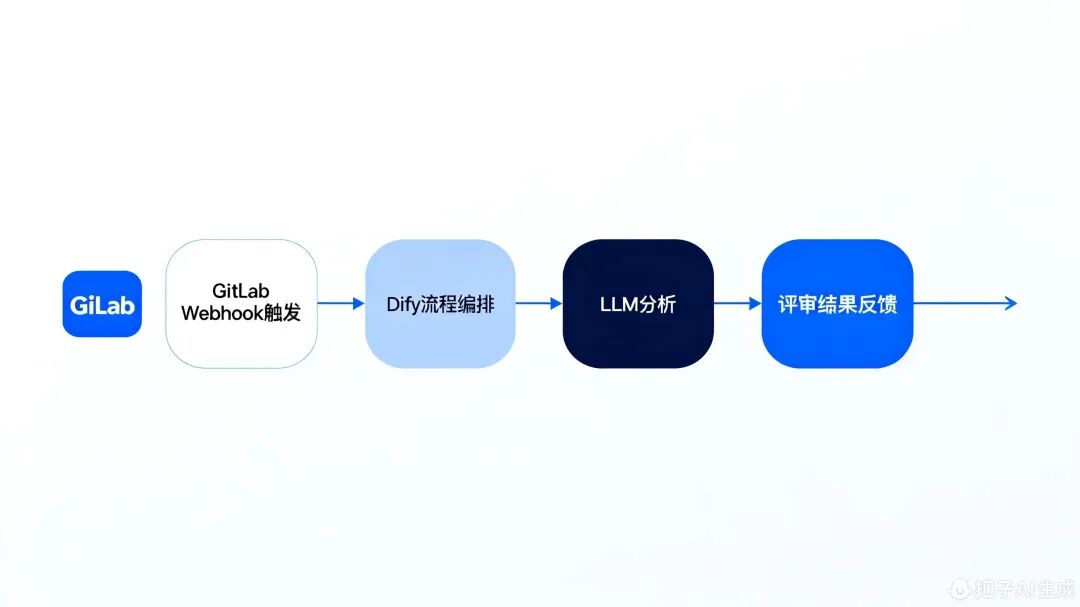
智能评审系统工作流程图
一、技术选型:为什么选择Dify+vLLM+GitLab组合?
1.1 三种主流方案对比
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 自研方案 | 完全定制化 | 开发周期长(6-12个月)、维护成本高 | 超大型企业 |
| 商业工具 | 开箱即用 | 按调用量收费(年成本≥50万)、数据隐私风险 | 中小型团队 |
| Dify+开源组合 | 部署灵活、成本可控 | 需要基础运维能力 | 中大型企业、技术团队 |
1.2 Dify+GitLab+vLLM的技术优势
- • 架构灵活性:Dify支持200+模型集成,可视化流程编排降低开发门槛
- • 企业级部署:vLLM私有部署保障代码数据不出境,符合等保2.0要求
- • 性能优化:PagedAttention技术使吞吐量较原生Transformers提升8倍
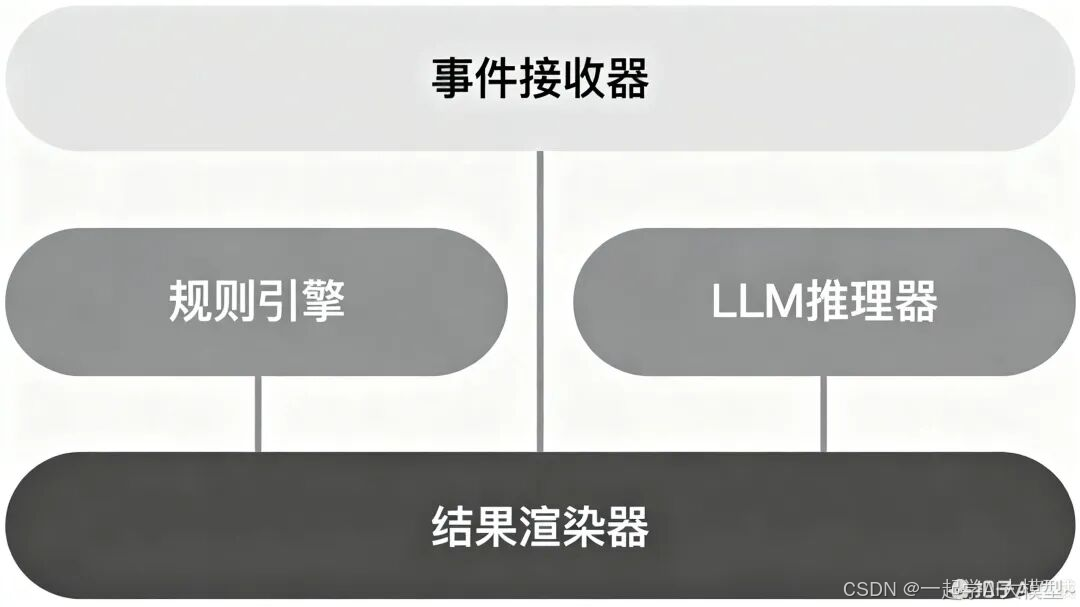
系统技术架构图
二、实战部署与开发:从环境搭建到功能实现
2.1 基础环境配置(硬件+软件)
推荐硬件配置(支持128K上下文+INT4量化):
- • GPU:4×NVIDIA A100 80GB
- • CPU:Intel Xeon Platinum 8480+(≥64核)
- • 内存:512GB DDR5
软件依赖清单:
# Docker Compose部署命令git clone https://github.com/langgenius/dify.gitcd dify/dockercp .env.example .env# 配置数据库密码等关键参数vim .envdocker-compose up -d
2.2 vLLM私有部署核心步骤
步骤1:模型下载与量化
# 从Hugging Face下载模型huggingface-cli download deepseek-ai/DeepSeek-V3.2-Exp --local-dir /data/models/DeepSeek-V3.2-Exp# INT4量化优化(需16GB显存)python -m auto_gptq.quantize \ --model_name_or_path /data/models/DeepSeek-V3.2-Exp \ --output_dir /data/models/DeepSeek-V3.2-Exp-int4 \ --bits 4 \ --group_size 128
步骤2:启动vLLM服务
# 8卡A100启动命令CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \python -m vllm.entrypoints.openai.api_server \ --model /data/models/DeepSeek-V3.2-Exp-int4 \ --tensor-parallel-size 8 \ --quantization int4 \ --max-model-len 65536 \ --gpu-memory-utilization 0.9
步骤3:Dify集成配置
-
- 登录Dify管理界面 → 模型设置 → 添加自定义模型
-
- 配置参数:
- • API基础URL:
http://vllm-server:8000/v1 - • 模型名称:
deepseek-v32-vllm - • 上下文长度:
65536
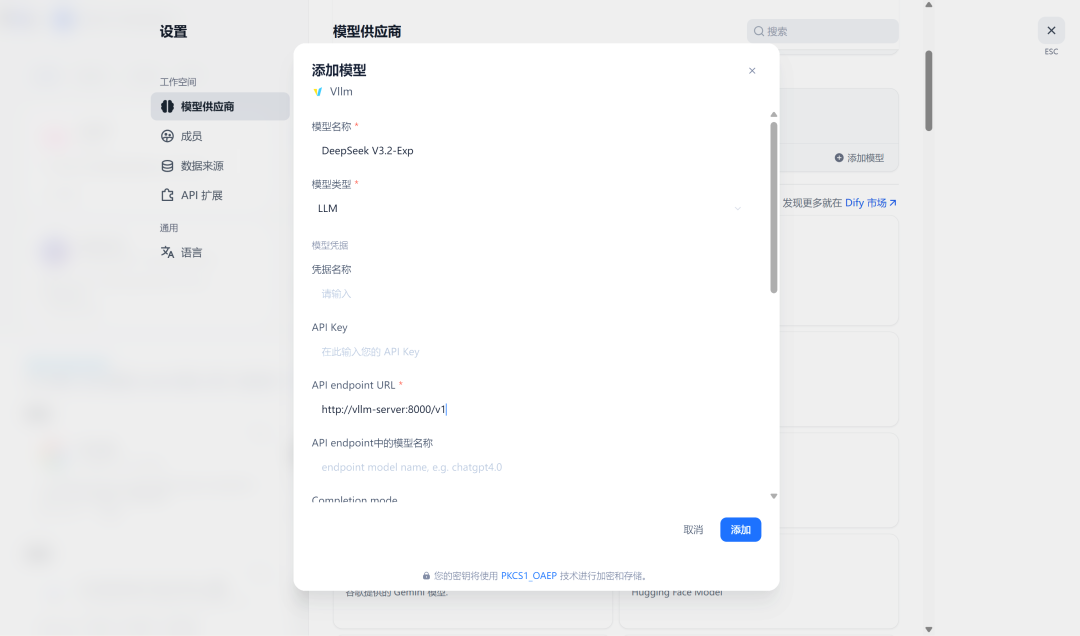
Dify配置vLLM模型界面
三、核心功能开发:三大模块实现代码自动评审
3.1 GitLab事件监听模块
# GitLab Webhook事件接收器from flask import Flask, request, jsonifyimport hmacimport hashlibapp = Flask(__name__)SECRET_TOKEN = "your-gitlab-webhook-secret"@app.route('/gitlab-webhook', methods=['POST'])def handle_webhook(): # 验证签名 signature = request.headers.get('X-Gitlab-Token') if not hmac.compare_digest(signature, SECRET_TOKEN): return jsonify({"status": "error", "message": "Invalid token"}), 403 # 处理Merge Request事件 event = request.json if event['object_kind'] == 'merge_request' and event['object_attributes']['state'] == 'opened': project_id = event['project']['id'] mr_iid = event['object_attributes']['iid'] # 获取代码diff diff_content = get_merge_request_diff(project_id, mr_iid) # 调用评审服务 trigger_code_review(diff_content) return jsonify({"status": "success"}), 200if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
3.2 评审规则引擎设计
通过Dify可视化界面配置5类评审规则:
-
- 代码规范:基于PEP8、Google Style Guide
-
- 安全漏洞:覆盖OWASP Top 10(SQL注入、XSS等)
-
- 性能优化:检测N+1查询、循环嵌套过深等问题
-
- 文档完整性:检查函数注释、参数说明
-
- 业务逻辑:基于领域知识图谱的规则匹配
代码评审规则配置界面
3.3 评审分析模块:提示词工程最佳实践
3.3.1 核心提示词模板
【系统角色】你是资深代码评审专家,精通Python/Java/Go多语言,熟悉以下规范:- 代码规范:PEP8、Google Style Guide、Airbnb JavaScript Style Guide- 安全标准:OWASP Top 10 2023、CWE/SANS Top 25- 性能优化:缓存策略、数据库索引优化、异步处理模式【评审任务】分析以下代码变更,输出结构化评审结果:1. 检查代码规范符合性(命名规范、代码格式、注释完整性)2. 识别安全漏洞(输入验证、认证授权、敏感数据处理)3. 评估性能问题(算法复杂度、资源泄漏、数据库查询效率)4. 验证业务逻辑(需求符合性、边界条件处理、错误处理)【代码变更】{{diff_content}}【输出格式】### 代码评审报告**总体评分**:{{score}}/100**问题列表**:| 级别 | 文件路径:行号 | 问题描述 | 修复建议 ||------|--------------|----------|----------|| P0 | {{file}}:{{line}} | {{description}} | ```{{code_snippet}}```|**优化建议**:1. {{suggestion_1}}2. {{suggestion_2}}**通过条件**:P0/P1级问题数量为0,P2级问题≤3个
3.3.2 提示词优化技巧
-
- 角色增强:明确专家资质提升模型专业度,如"10年金融级系统开发经验"
-
- Few-Shot示例:提供1-2个典型问题案例帮助模型理解标准```plaintext
【示例】问题:SQL语句未使用参数化查询级别:P0修复:将"SELECT * FROM users WHERE name = ‘%s’"改为参数化查询
- Few-Shot示例:提供1-2个典型问题案例帮助模型理解标准```plaintext
-
- 动态参数调整:
- • 代码评审:Temperature=0.3(降低随机性)、Top-P=0.7
- • 创意优化:Temperature=0.7(增加创新性)
-
- 上下文注入:附加项目相关信息```plaintext
【项目上下文】- 框架:Spring Boot 2.7.x- 数据库:MySQL 8.0(读写分离架构)- 安全要求:需符合GDPR数据加密标准
- 上下文注入:附加项目相关信息```plaintext
四、性能优化与效果验证
4.1 vLLM性能调优参数
| 参数 | 建议值 | 优化效果 |
|---|---|---|
--max-num-batched-tokens |
8192 | 每批处理token数提升2倍 |
--gpu-memory-utilization |
0.9 | 显存利用率从70%提升至90% |
--enable-prefix-caching |
True | 首token延迟降低40% |

vLLM性能监控仪表盘
4.2 对比测试结果
选取3个典型项目进行测试(微服务/前端组件/数据库脚本):
| 指标 | 人工评审 | 智能评审 | 提升倍数 |
|---|---|---|---|
| 平均耗时 | 45分钟/PR | 3分钟/PR | 15× |
| 问题检出率 | 68% | 92% | 1.35× |
| 开发者满意度 | 62% | 89% | 1.43× |
五、企业级扩展建议
5.1 多LLM模型融合策略
- • 主模型:DeepSeek-V3.2-Exp(代码分析主力)
- • 专家模型:CodeLlama-70B(复杂逻辑验证)
- • 轻量模型:Phi-2(简单规范检查,降低成本)
5.2 与现有系统集成
- • Jira工单同步:评审问题自动创建Jira任务
- • 飞书通知:@相关负责人处理高优先级问题
- • Confluence知识库:评审案例自动沉淀为技术文档
结语:从工具到流程的智能化转型
通过Dify+vLLM+GitLab构建的智能评审系统,不仅解决了传统评审的效率问题,更实现了评审知识的结构化沉淀。某互联网团队实践表明,系统上线后PR平均处理周期从3天缩短至4小时,基础规范问题拦截率提升至98%。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐
 8
8 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)