




- @2401_84204413
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?答案只有一个:人工智能(尤其是大模型方向)当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应

摘要 文章指出前端开发者转型AI Agent开发常见的学习误区,强调不应直接学习LangChain等框架而忽视底层原理。正确的学习路径应遵循:先掌握LLM原生API,再手动实现Agent循环,接着学习上下文控制、工具契约设计、执行轨迹追踪和运行时恢复等核心能力。作者提醒Agent开发的重点在于设计AI的工作界面和任务流程,而非简单的Prompt工程,建议前端开发者转变思维,培养系统设计能力。文章最

摘要 文章指出前端开发者转型AI Agent开发常见的学习误区,强调不应直接学习LangChain等框架而忽视底层原理。正确的学习路径应遵循:先掌握LLM原生API,再手动实现Agent循环,接着学习上下文控制、工具契约设计、执行轨迹追踪和运行时恢复等核心能力。作者提醒Agent开发的重点在于设计AI的工作界面和任务流程,而非简单的Prompt工程,建议前端开发者转变思维,培养系统设计能力。文章最
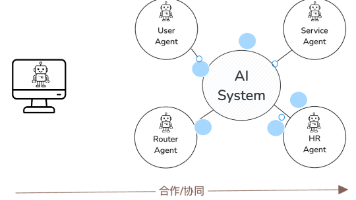
在前面的文章中我们已经体验过MCP与A2A的Demo演示,这里看一个基于AutoGen框架(0.4+)下分布式Agent系统官方示例:【场景描述】一组分布式Agent(比如HR Agent,Finance Agent):假设企业使用这些Agent来管理其人力资源和财务相关业务,这些Agent需要在不同的机器上运行。一个语义路由器Agent会识别用户的意图(暂时采用基于简单的字符串匹配方法),确定最
最近很多同学私信问我:“有没有适合AI产品经理的实战类书单推荐?”确实,随着AI在各行业加速落地,产品经理的认知与能力边界也在不断被拓宽,想要在岗位上有更强的竞争力,单靠经验积累远远不够。系统阅读+带着问题深入思考,是最快的成长方式之一。今天就给大家推荐几本我反复阅读、在实战中验证过价值的好书,针对AI产品经理在实际工作中最常见的几个关键痛点,每一本都非常“解渴”。

本文分享了一套快速转行AI产品经理的五阶段学习路径。通过建立行业感知、体验主流产品、搭建AI工作流、落地业务项目、优化面试技巧五个步骤,帮助学习者在1-2个月内高效完成转型。关键在于遵循"先宏观后微观"的学习逻辑,避免无效摸索,着重培养AI产品设计思维和业务结合能力。文章还提供了免费AI学习资料获取方式,涵盖大模型系统设计、提示词工程、平台开发等核心内容。

摘要: 随着AI技术快速发展,传统产品经理面临转型挑战。AI产品经理需在通用能力基础上,掌握AI技术应用能力,主要分为视觉AI、机器学习、AI应用、语义AI等方向。转行需学习机器学习原理、算法逻辑等基础知识,并具备技术沟通与需求分析能力。AI产品经理的工作涉及多团队协作,需全局思维与技术架构认知。招聘要求显示,企业更看重AI技术背景、产品规划及落地能力。建议从细分领域入手,逐步提升技术理解与业务实
AI产品经理学习路线:从基础到进阶 AI产品经理需兼具技术理解与产品思维,学习路径分为五大模块:1)基础知识:掌握AI概念、计算机基础及Python编程;2)AI技术:深入学习机器学习、深度学习及NLP等核心技术;3)数据分析:熟练使用统计工具及数据预处理方法;4)产品思维:聚焦用户需求与交互设计;5)协作管理:熟悉敏捷开发与跨团队协作。文末提供大模型学习资料包,助力系统化学习与职业发展。

大模型竞技场出现神秘模型"steve",自称来自DeepSeek,引发网友热议。有人猜测是即将发布的DeepSeek-R2,也有人认为是旧版升级或第三方模型。对比测试显示steve表现不及V3和R1,而此前报道称R2因CEO不满意和芯片短缺再度延期。与此同时,大模型AI人才需求激增,相关岗位薪资可观。文章还分享了大模型AI的系统学习方法,分四个阶段从应用到训练再到商业闭环。
随着大模型技术快速发展,企业亟需专业的AI产品经理。本文提出了一套大模型产品经理的学习路径:1)基础阶段需掌握Python编程、数据结构和机器学习原理;2)进阶阶段重点学习神经网络架构、模型训练评估及主流框架使用。该学习路线旨在帮助从业者构建跨学科知识体系,从技术理解到产品落地,实现从零基础到精通的成长过程。
