登录社区云,与社区用户共同成长
邀请您加入社区
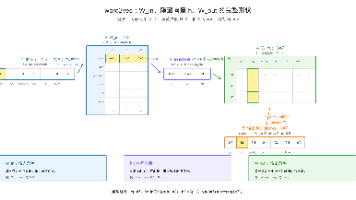
本文介绍了word2vec模型中W_in、h和W_out三个关键组件的功能。W_in是输入矩阵,将one-hot编码的输入词转换为隐藏向量h;h作为中间表示,用于与输出矩阵W_out的列向量计算点积得分,预测目标词。W_out存储每个词作为输出时的向量表示。三者协同工作:W_in将输入词映射为h,h通过与W_out的交互计算各候选词的得分,最终实现词向量学习和上下文预测。这种架构有效捕捉了词语间的
在生物信息学领域,特征工程是构建高性能预测模型的关键步骤,它决定了模型能否从原始数据中提取有效信息。传统方法依赖领域专家手工设计特征,不仅耗时费力,且难以捕捉复杂的非线性关系。随着深度学习技术的发展,自动特征学习成为新的范式,它通过数据驱动的方式让模型自主发现数据的内在结构和规律。词嵌入技术,如word2vec,通过将离散符号映射为连续向量,能有效捕捉序列的语义信息,在自然语言处理中取得了巨大成功
它和我们平时调用 ChatGPT 那种"现成预训练好的大模型 API"完全不同。
凭借CLR的JIT编译和值类型等优化设计,C#在性能上接近Java,在某些场景甚至更优。其语言设计融合了C++的效率和Java的安全性,但跨平台支持虽然通过.NET Core得到改善,在非Windows环境中的普及度仍有限。从纯性能角度排序,C语言通常最高,其次是C#和Java,Python和PHP相对较慢。不同语言在性能特性、开发效率和应用场景上各有优劣。本文将从运行机制、性能表现和典型应用场景
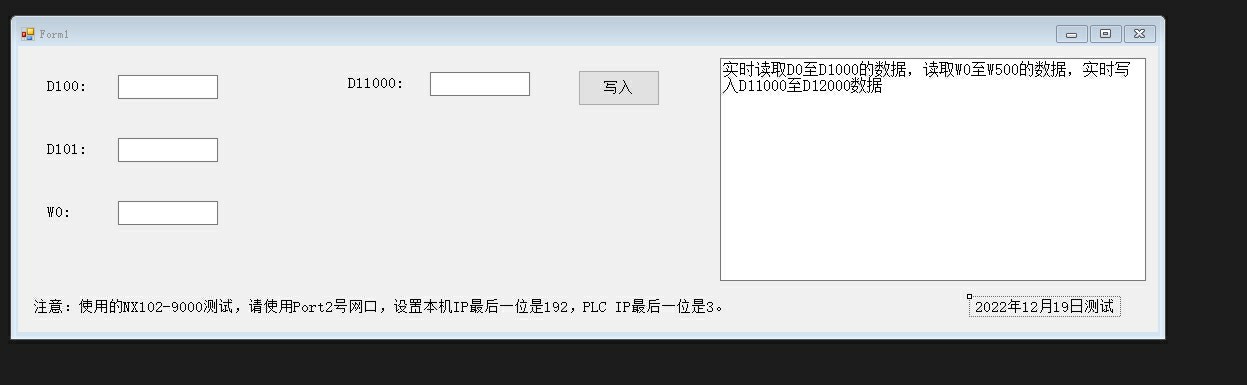
C#与欧姆龙PLC NX102-9000测试FINS通信,使用TCP连接方式,保证通信数据重要性,实时监测是否断线;实时读取D0至D1000寄存器数据,实时读取W0至W500的实时数据,将本机数据写入到D11000至D12000数据寄存器,保证数据交换正常;这里Reverse()不是手滑,欧姆龙的地址排列是反人类的Big-endian(高位在前),必须把字节数组倒过来。最近刚用C#调通欧姆龙NX系
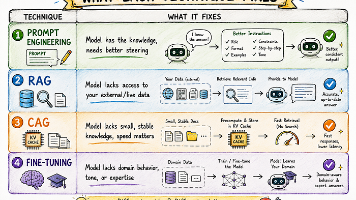
不少人折腾仨月给模型做微调,最后发现一个写得好的提示词,一周就能搞定问题;还有人非要搭全套RAG向量数据库,可那些文档其实一开始就能塞进上下文窗口;也有人总在抠提示词的细节,却没发现真正需要的是给模型做领域重训。
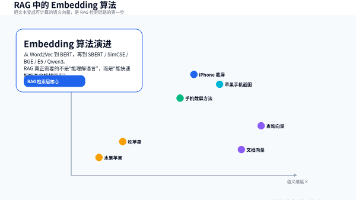
很多人第一次回答“Embedding 算法有哪些”时,容易只说 Word2Vec 或 BERT。这个回答不算错,但会暴露一个问题:没有把 NLP 表示学习和 RAG 检索工程区分开。RAG里真正需要的 Embedding,必须满足三件事:第一,能把语义相近的 Query 和文档 Chunk 拉近;第二,能把文档向量提前算好并存进向量库;第三,在线查询时只算一次 Query 向量,就能在百万甚至千万
6 月 16 日,全国首个省级政务智能中枢平台"湾擎"上线。同步预发布的"湾擎·WorkBuddy",即将面向广东全省公务员开放使用。
注:本文为开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图。
word2vec中最大的问题是,随着语料库中处理的词汇量的增加,计算量也随之增加。对上一章中简单的word2vec进行两点改进:引入名为Embedding 层的新层,以及引入名为的新损失函数。1 word2vec的改进①假设词汇量有100万个,CBOW模型的中间层神经元有100个。
机器人系统与控制需求简介1、工业机器人系统组成机械本体控制柜示教盒2、核心零部件精密减速机伺服电机伺服驱动器控制系统3、本体结构分类关节型机械臂SCARA机械臂笛卡尔机械臂Delta并联机械臂Delta并联机械臂圆柱形机械臂球坐标机械臂4、符号表示机器人:关节+连杆 组成运动链关节:转动关节(Revolute)平动关节(Prismatic)符号表示:[外链图片转存失败,源站可能有防盗链机制,建议将
本文摘要了2025WEB数据管理课程中关于网络爬虫技术和网页分析的核心内容。课程涉及爬虫定义、URL规范化处理、文档指纹算法、爬虫功能特性等基础知识,重点对比了正则表达式与DOM树两种网页分析方法,介绍了Beautiful Soup和Scrapy等常用工具。同时探讨了爬虫与网站的博弈策略,包括反爬技术、验证码识别等。在数据抽取方面,详细讲解了包装器概念、页面分类及不同类型页面的抽取方法,以及Web
基于STM32+ATT7022芯片三相交流电测量RTU可测量电压、电流、功率、功率因素、频率、电量等参数,MCU主控为STM32F103C8T6,支持485通信,Modbus 协议,成熟稳定项目。注意:只提原理图文件、程序代码最近搞了个基于STM32 + ATT7022芯片的三相交流电测量RTU项目,感觉还挺有意思,和大家分享下。这个项目可以测量电压、电流、功率、功率因素、频率、电量等一堆参数,主
深度学习word2vec笔记之基础篇声明:1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的。具体引用的资料请看参考文献。具体的版本声明也参考原文献2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
之前有学习过文本预处理的环节,对文本处理的主要方式有以下三种:1:词袋模型(one-hot编码)2:TF-IDF3:Word2Vec(词向量(Word Embedding) 以及Word2vec(Word Embedding 的方法之一))详细介绍及中英文分词详见pytorch文本分类(一):文本预处理上上上上期主要介绍Embedding,及EmbeddingBag 使用示例(对词索引向量转化为词
【人工智能基础】【练习题】自然语言处理基础: Word2vec逻辑、与预训练模型
这是一篇从实战出发的NLP入门笔记,核心讲解了让计算机“读懂”文字的两个基础步骤:分词与文本向量表示。
word Embedding 将自然语言单个词向量化,转换完向量可以进行计算了(比如:相似度计算)。word2vec是一个简化版的embedding训练工具,训练时语料越多、质量越高,训练后的模型越准确。百炼平台、魔搭平台上有预训练好的embedding模型,可以直接使用,不用自己从头训练,图片和文字的embedding模型是不同的,意味着你不能用文字的embedding模型去处理图片。embed
ChatGPT Team版适合有团队协作需求的用户,个人用Plus版足够Claude API降价后按量付费更划算,适合集成到工作流中Gemini代码运行小而美,Python数据分析够用Grok搜索更快了,实时信息场景有优势工具越来越好,选择越来越多。先用上,再优化。本文内容基于个人实际使用体验整理,供大家参考。具体工具选择及渠道使用请结合自身情况判断。
二是执行能力,包括任务处理的准确率、长流程稳定性、多任务调度效率,是影响实际提效效果的核心指标;三是生态适配,涵盖支持的大模型种类、办公软件与通讯工具的兼容度、可扩展的技能数量,决定了产品的场景边界;四是数据安全,关注数据存储方式、权限管控机制与技能安全审核体系,是个人与企业选型的基础底线;五是场景适配,不同产品在个人办公、团队协同、开发定制等场景的优化程度各有不同,按需匹配即可。本文整理五款不同
一个好玩技巧:让Codex把我的工作流蒸馏成skill
word2vec
——word2vec
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区


 AtomGit AI 社区
AtomGit AI 社区

 AI Agent技术社区
AI Agent技术社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 DAMO开发者矩阵
DAMO开发者矩阵








 脑启社区
脑启社区


 智能体开发者社区
智能体开发者社区



