




- @weixin_43807749
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文记录下,如何使用vLLM部署模型。安装教程参考视频教程:https://www.bilibili.com/video/BV1BijSzfEmQ/。由于vLLM只支持Linux操作系统,所以首先安装WSL2。
第一章的笔记只是做浅层的了解。其中有ai帮我总结的内容,有的知识点我也不太理解…a. 大模型外部工具基本概念 b. MCP技术协议核心概念在 MCP 之前,开发者常常针对每个数据源或工具编写“N×M”次适配器,集成成本高且维护困难。MCP 将外部功能抽象为三类接口——资源(Resources)、工具(Tools)、提示模板(Prompts),模型只需通过统一的 JSON-RPC 调用即可访问
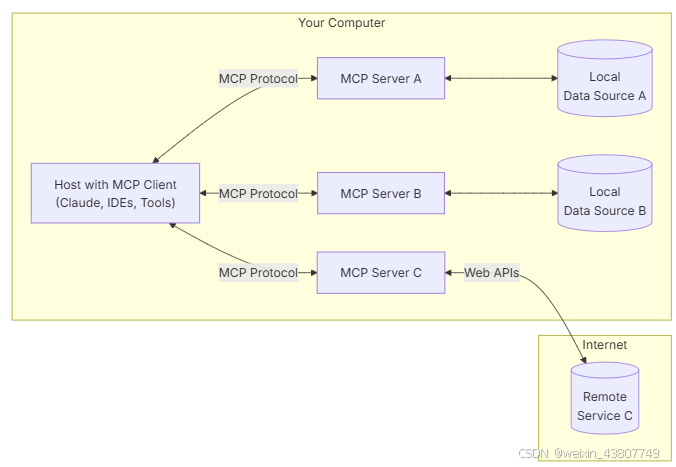
在上一篇博客中,尝试构建了多种mcp_server。接下来考虑,如何将我们的多mcp_server给前端提供api接口。
参考文献:本文仅仅用于学习记录langchain的基础内容。langchain中接入天气查询功能。在笔者的mcp入门博客中,有天气查询这个api更详细的记录。不在此赘述。# 接入自定义工具@tool"""查询即时天气函数:param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\注意,中国的城市需要用对应城市的英文名称代替:return: 解析之后的json格式对象"""par
学习记录claude-cookbooks。今日学习:https://github.com/anthropics/claude-cookbooks/tree/main/patterns/agents。
学习记录claude-cookbooks。今日学习:https://github.com/anthropics/claude-cookbooks/tree/main/patterns/agents。
本文只用于记录,学习如何提交代码到gitee。参考文献:https://www.bilibili.com/video/BV1FE411P7B3/?
在之前的博客中,笔者尝试利用ollama和anythingLLM建立了本地知识库,并在局域网内,提供接口给其他人使用。在本文中,笔者尝试利用另外一个工具RAGFlow,来搭建本地知识库。在大型语言模型(LLM)中,Embedding是指将离散的文本数据(如单词、短语或句子)转换为连续的数值向量的过程。这些向量捕捉了文本的语义和语法特征。具体而言,Embedding将高维度的离散数据映射到低维度的
代码已上传至github中,欢迎star!版本 1.0.2CS336 课程组2025 年春季在本次作业中,你将获得训练语言模型解决数学问题时进行推理的实践经验。需实现的内容对于感兴趣的同学,我们将额外设置一个可选任务——使语言模型与人类偏好对齐,该任务将于未来几天发布。需运行的内容所有作业代码及本说明文档均已上传至 GitHub,地址如下:github.com/stanford-cs336/ass
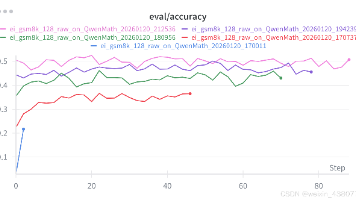
本次作业要求学生从零开始构建Transformer语言模型的关键组件,包括:1)基于字节对编码(BPE)的分词器,需实现Unicode编码处理、子词切分和词汇表训练;2)完整的Transformer语言模型架构;3)交叉熵损失函数和AdamW优化器;4)支持模型保存/加载的训练循环。学生将在TinyStories和OpenWebText数据集上分别训练分词器和语言模型,最终提交模型在测试集上的困惑