




- @v_JULY_v
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
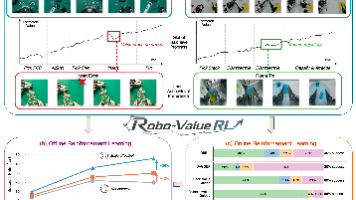
本文提出Robo-ValueRL框架,旨在通过可靠的价值函数提升离线到在线强化学习在机器人操作任务中的性能。该框架包含三个关键组件:历史条件化价值估计器、质量条件化视觉-语言-动作(VLA)策略预训练和在线残差自适应模块。 研究团队设计了全局进展和局部偏好两个指标来评估价值函数的可靠性,发现可靠的价值估计能显著提升策略性能。实验表明,在240小时离线数据和3000条在线轨迹的测试中,该方法使毫米级
如此文《》的第三部分开头所说跑iDP3的整个流程分为:数据采集、数据转换、数据预处理,然后做训练、部署、可视化,具体而言,iDP3开源了两个代码仓库,一个是学习,一个是摇操作,其中对于后者,已经在这两篇文章里「」进行了详尽细致的分析,对于前者,则是本文。

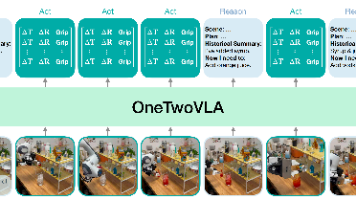
OneTwoVLA:统一视觉-语言-行动模型实现自适应推理与执行协同 本文提出OneTwoVLA模型,通过统一架构解决现有系统在推理与执行分离时产生的问题。该模型创新性地实现了:1)自适应切换推理与执行模式的能力;2)支持视觉-语言数据的联合训练提升泛化性;3)开发可扩展的合成流程自动生成16,000个具身推理数据样本。相比传统双系统框架,OneTwoVLA在错误检测恢复、人机交互和视觉定位等方面
摘要:本文提出RoboTTT方法,通过将测试时训练(TTT)机制整合到机器人基础模型中,实现了8K时间步的长视觉-运动上下文建模。该方法采用快速权重机制,在训练和推理时动态更新模型参数,将历史信息压缩至权重空间,解决了长上下文建模的三大挑战。实验表明,RoboTTT-8K相比单步基线在复杂任务中性能提升87%,首次证明扩展上下文长度能稳定提升闭环性能(比1K上下文模型提升63%)。创新性地结合序列

24年9.28日下午,微信上的好友丁研究员和我说我当时(周六)和家人在李自健美术馆,故回复之:帅气,我晚上到家后看下我个人确实准备 这几天仔细研究下,毕竟我们之前也在基于umi/dexcap做二次开发,有很多契合点我深知这种感觉,因为当我司做出一个大模型应用或机器人解决方案,哪怕只是一篇博客时,都渴望和同行做各种深入交流而且正如技术合伙人姚博士所说,“fastumi数据采集方式的改进强,因为我们当

本文介绍了ABot-AgentOS,一个通用机器人智能体操作系统,旨在连接高层语义推理与物理执行。该系统整合了多模态感知、记忆、推理和技能执行功能,支持跨不同机器人平台的运行。ABot-AgentOS采用边缘-云协同架构,包含验证感知的ReAct框架、分层LLM智能体(主LLM、SkillRunner和Verifier)以及多模态记忆系统。其创新点在于将认知层与硬件解耦,通过场景条件驱动的任务规划
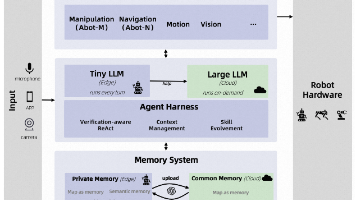
本文介绍了ABot-AgentOS,一个通用机器人智能体操作系统,旨在连接高层语义推理与物理执行。该系统整合了多模态感知、记忆、推理和技能执行功能,支持跨不同机器人平台的运行。ABot-AgentOS采用边缘-云协同架构,包含验证感知的ReAct框架、分层LLM智能体(主LLM、SkillRunner和Verifier)以及多模态记忆系统。其创新点在于将认知层与硬件解耦,通过场景条件驱动的任务规划
本文介绍了ABot-AgentOS,一个通用机器人智能体操作系统,旨在连接高层语义推理与物理执行。该系统整合了多模态感知、记忆、推理和技能执行功能,支持跨不同机器人平台的运行。ABot-AgentOS采用边缘-云协同架构,包含验证感知的ReAct框架、分层LLM智能体(主LLM、SkillRunner和Verifier)以及多模态记忆系统。其创新点在于将认知层与硬件解耦,通过场景条件驱动的任务规划
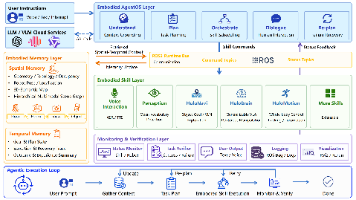
HoloAgent-0是一个面向真实世界机器人的统一具身智能体框架,通过三层架构实现闭环执行:1) Embodied AgentOS作为运行时层进行任务规划与监控;2) 技能层将机器人能力抽象为可组合的带类型动作;3) 记忆层维护3D空间记忆和执行历史。该框架通过ROS2接口连接异构机器人能力,支持导航、操作、全身运动等技能的组合执行,并利用持久化记忆实现长期任务跟踪和失败恢复。实验验证了其在3D
本文提出FurnitureVLA方法,通过视觉-语言-动作模型解决真实尺度双臂家具装配的挑战。针对长时序、高精度装配任务,该方法将装配过程分解为语义子任务,并开发进度增强型VLA模型,在预测动作的同时输出子任务进度信号以降低误差累积。系统包含可扩展仿真流水线生成专家数据,以及优化的VR远程操作系统采集真实示教数据。实验在三种IKEA家具上验证了方法的有效性,重点关注双臂协同操作、几何对齐精度等关键
