登录社区云,与社区用户共同成长
邀请您加入社区
本文是 Python 开发环境相关 IDE 的详细安装流程介绍,手把手带你实现一个简单好用的个人 Python 环境的搭建。同时,也是 Python 数据分析学习笔记的基础。文章主要介绍了 Anaconda、Pytorch、Jupyter Notebook 和 PyCharm 的安装流程。
def jc(n):s=1s*=ireturn ss 是累乘结果return s是把s结果返回给调用函数如果不写return s 函数就执行完了 print(jc(10))会打印None。
Jupyter主要是用来做数据科学,其包含数据分析、数据可视化、机器学习、深度学习、机器人等等,任何Python数据科学第三方库都能在Jupyter上得到很好的应用和支持。其实它是集编程、笔记、数据分析、机器学习、可视化、教学演示、交互协作等于一体的超级web应用,而且支持python、R、Julia、Scala等超40种语言。在产品上,Jupyter不仅有简洁的Notebook ,还有工作台式的
windows7下在pyxll插件下安装xll-jupyter(python3.8.10)
【代码】python3.12以及jupyter notebook的安装。
本文介绍了三种安装Jupyter Notebook的方法:1)通过Anaconda全家桶安装,自带环境配置和数据分析库;2)已有Python环境时使用pip安装,推荐清华源加速;3)在VSCode中通过Python插件使用,需解除受限模式并创建.ipynb文件。每种方法都提供了详细的安装步骤和验证方式,包括Windows和macOS系统的操作指南,以及解决常见问题的技巧(如升级pip、使用国内镜像
一般而言问题到这里就解决了,如果还没有考虑检查site-package里有没有以~开头的相关废弃文件,一起删除。此解决方案对numpy,pytorch,tensorflow,transformers等库广泛试用.
修改jupyter内核的方法介绍
退出再从终端中打开就可以了,打开就是非常干净的界面了,但是我这里有一个小问题,我之前生成了jupyter notebook和jupyter lab的配置文件,如果我只修改jupyter notebook中的地址,从终端打开还是默认位置,我需要把jupyter lab的配置文件中的地址也修改了才可以,jupyter lab中的地址修改和上面的操作相同。可以看见如果我现在在notebook中新建一个文
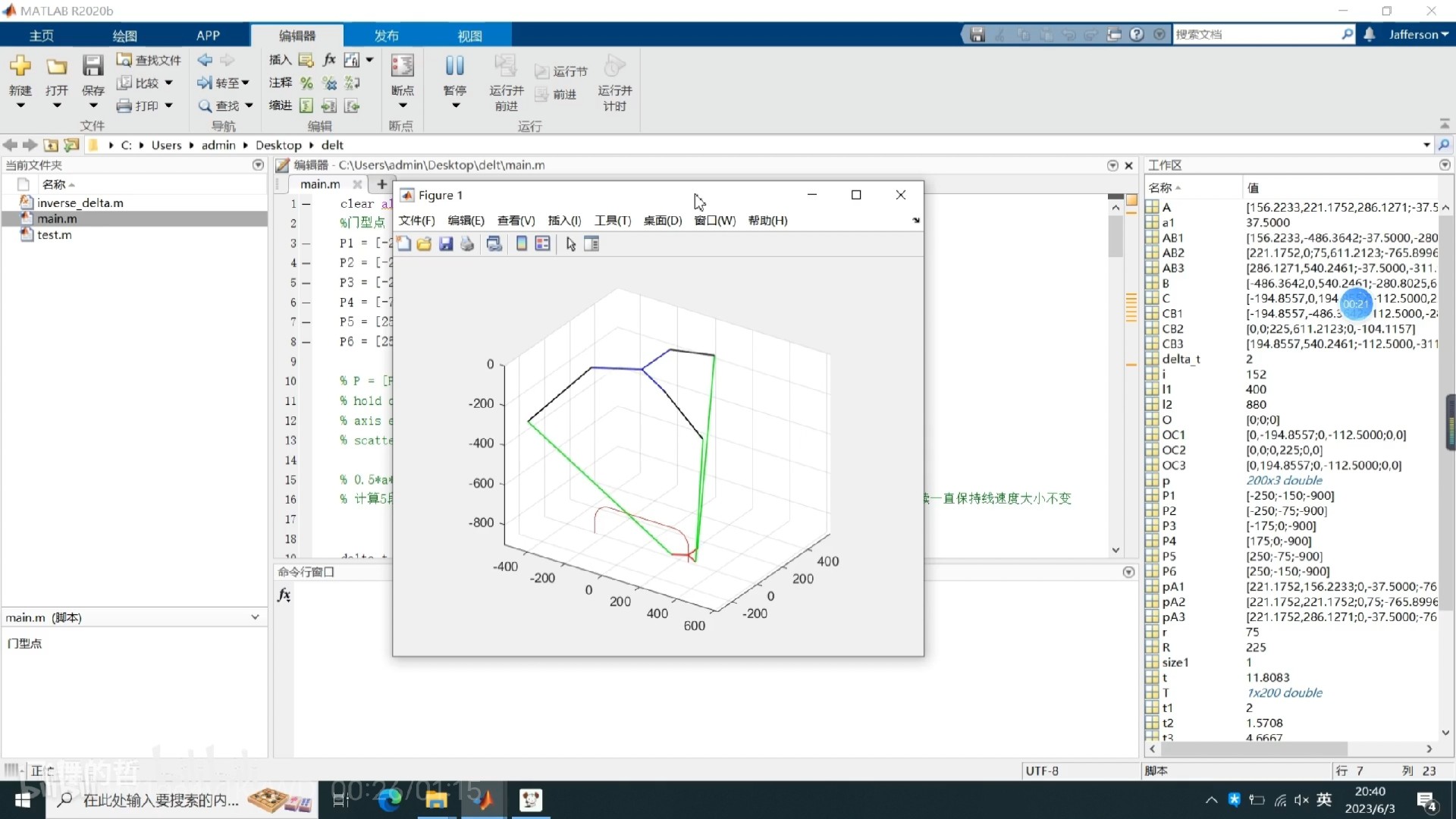
今天咱们来聊聊Delta并联机器人的轨迹规划和工作空间求解,顺便撸点代码,看看怎么搞正逆解。它的结构简单,三个臂膀,末端有个平台,动起来特别灵活。轨迹规划的核心就是插值,就是在路径上取一系列点,然后让机器人依次到达这些点。不过,这只是个简化模型,实际应用中还要考虑更多因素,比如臂膀的偏移、关节的限制等等。这个函数就是逆解的核心代码。不过,这个代码也是个简化模型,实际应用中还要考虑更多细节,比如关节
一、相关库机器学习基础阶段会用到Matplotlib、Numpy、Pandas等库1.MatplotlibMatplotlib是绘图库,可以绘制函数图、统计图等。专门用于开发2D/3D图表安装1.windows:升级 pip:python3 -m pip install -U pip安装 matplotlib 库:(Ubuntu一样)pip install matplotlib下载完成后可以在Py
快捷操作:ctrl+shift+减号:添加代码块shift+回车:程序重新执行一遍数据范围:8月份的订单信息,三个sheet页分别为8月的上中下旬各10天主要使用的数据字段为:place_order_timeread_excel()函数data.info()函数查看数据的基本信息分别取出三个sheet页的数据,并进行合并dropna()函数平均值的两种方法:numpy和pandas,如果数据量笔记
本系列笔记是博主学习 Python 数据分析的详细记录,主要记录了在学习过程中遇到的各种实际问题与解决方法。本文是第二章:开发环境,主要介绍了本系列学习笔记的实机环境的选择和安装步骤。相信小伙伴们跟随本系列笔记,也一定能够成功复现《Excel Python:飞速搞定数据分析与处理》书里的各个案例。
新建文件并选中将要使用的环境:将新建的文件进行命名:两种方式①直接在文件夹中重命名②在jupyter notebook界面中进行重命名:点击Untitled进行重命名。
最近公司有16台服务器要重新部署ubuntu系统和环境,于是写下这篇文章,记录一下自己从安装显卡驱动到jupyter notebook 的过程,并讲述在安装过程中遇到的各种坑。
因为我是用的pycharm,所以我直接在pycharm项目终端中下载pip install jupyter,pip install pyecharts。在你下载的项目路径中输入jupyter notebook。一定要另起一行写展示代码。最常见的问题是不出图。
安装jupyter扩展插件nbextensions报错,百思无果
本系列笔记是博主学习 Python 数据分析的详细记录,主要记录了在学习过程中遇到的各种实际问题与解决方法。本文是附录 B 高级 VS Code 功能,简要介绍了 VS Code 中调试器的使用以及如何运行 Jupyter Notebook。
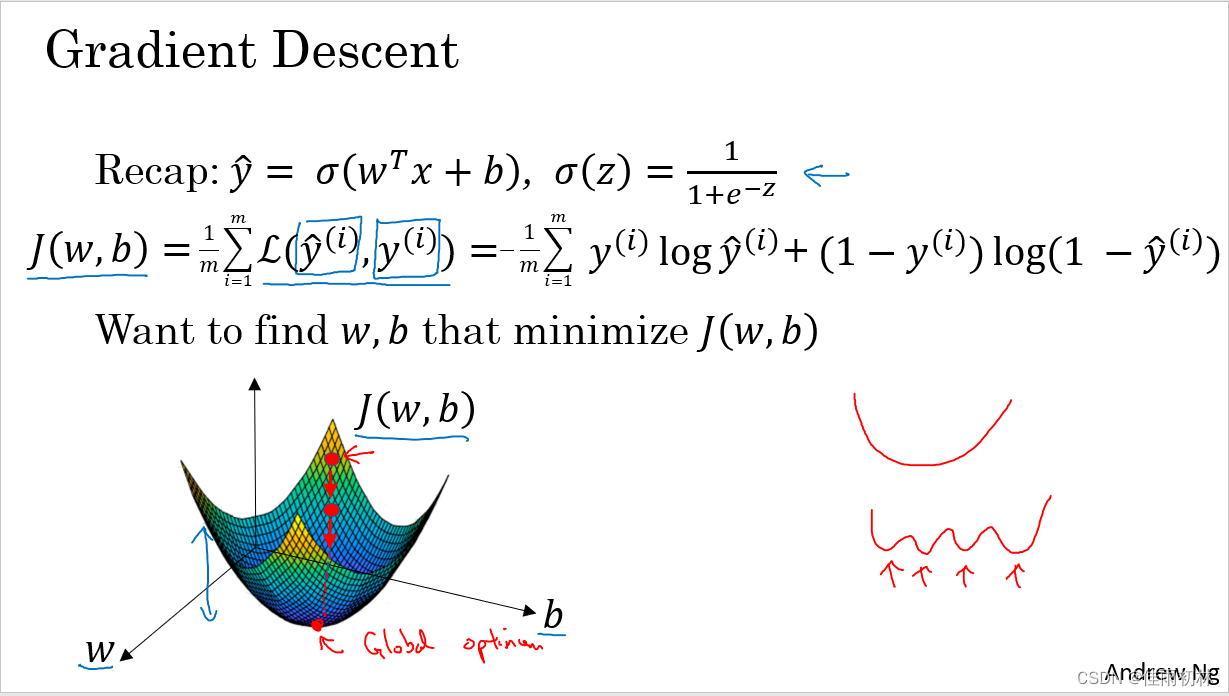
本篇博客主要是个人在完成吴恩达老师第二周的课后作业的实验记录,实现了logistics regression模型
萌新入门机器学习的第一个手把手案例零基础尝试Kaggle-Titanic - Machine Learning from Disaster附代码
具体来说,xy参数指定了标签的位置,xytext参数指定了标签文本的位置偏移量,偏移量是指每一根柱子上的数字的位置改变,这样就可以在图表中显示每个数据点的具体数值。代码进行排序,排序的依据是元素的第二个值(索引为1的值),并且以降序(reverse=True)的方式进行排序。所以,zip(day_money, xs)实际上就是将 day_money 和 xs 中对应位置的元素打包成元组的形式,以(
jupyter
——jupyter
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 DAMO开发者矩阵
DAMO开发者矩阵