




- @u013250861
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Java架构师-分布式(三):分布式文件系统-FastDFS+阿里OSS
下面把你提到的几项逐一整理成「论文(Paper)/ 代码(Code)」入口。备注:你写的目前主流官方拼写是(我按官方名称给链接)。另外并非 DeepSeek 出品(HiStream 作者来自 Meta AI/NTU,Emu2 来自 BAAI),但我仍按你的清单提供对应论文与代码。
大模型pretrain蒸馏训练中(不是sft),如何利用教师模型对学生模型进行蒸馏训练?从蒸馏数据的生产到学生模型的训练,给出详细的步骤下面用“老师带学生做完形填空”的比喻,把从到讲清楚。你可以把它当成一条“流水线”。
- 通常情况下,Agent 每一步操作有一个 reward 对应,但是,当 reward 的分布非常稀疏时,可能三四步甚至更多步之后才能产生reward。这样的话,对于机器而言学习如何行动会十分困难。- 这个一开始的暂时的小的reward 就叫 Sparse Reward- 比如说要让一个机器人倒水进水杯里,如果不对机器人做任何指导,可能它做很多次尝试,reward都一直是零。(不知道杯子在哪,不
【代码】时间序列预测方法:传统统计方法、机器学习方法、深度学习方法、Transformer、大语言模型方法、多模态方法。
内参:相机“像素尺度与中心”畸变:镜头把直线拍弯的规则外参:相机相对世界/另一个相机的摆放姿态标定方法:工程最常用的是Zhang 平面标定法(多张平面标定板图像 + 最小化重投影误差)标定流程:采图 → 检点 → 建对应 → 求初值 → 优化 → 验证 → 保存 → 应用到 2026 年,相机标定依然重要;很多“看起来不标定”的方法,其实是把标定变成了自标定/在线校正/隐藏在优化里。
图像分割是将一幅图像分成多个子区域的过程,使得每个子区域内的像素具有相似的特征。图像分割是计算机视觉领域中的一个基础问题,被广泛应用于医学影像分析、目标跟踪、自动驾驶等领域。语义分割是图像分割的一种特殊形式,即将图像中的每个像素划分到一组预定义的语义类别中,与物体实例无关。因此,语义分割可以被视为图像分类问题的推广,而不是像素级别的物体检测或实例分割问题。语义分割是许多计算机视觉任务中的基础,如自
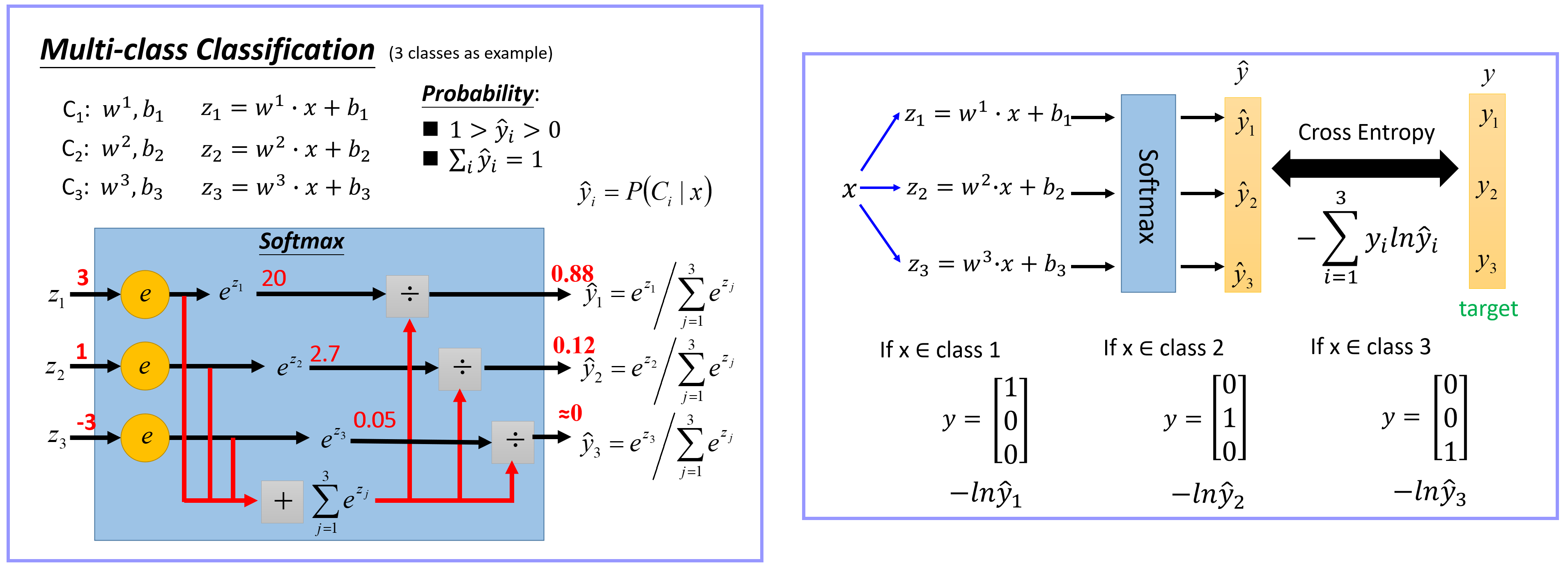
L=−j=1∑Tyjlog(Sj)=−N1i∑log(∑jewjTxiewyiTxi)LSjSjjyjj1Ty1×TT11T−10110样本3真实类别为c1,c5loss3=−∑yi,c⋅log(pi,c)=−[y3,1⋅log(p3,1)+
AlexNet(2012)在 ImageNet 竞赛上实现了巨大突破,直接把 deep learning 推向计算机视觉的中心舞台,“ImageNet moment”。许多模型(ResNet、DenseNet、MobileNet、ViT 等)都先在 ImageNet-1k 上预训练,再迁移到下游任务(检测、分割等)。“在 ImageNet 上预训练”、“ImageNet top-1 acc”、“R