
写文章




- @Richard_Kim
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
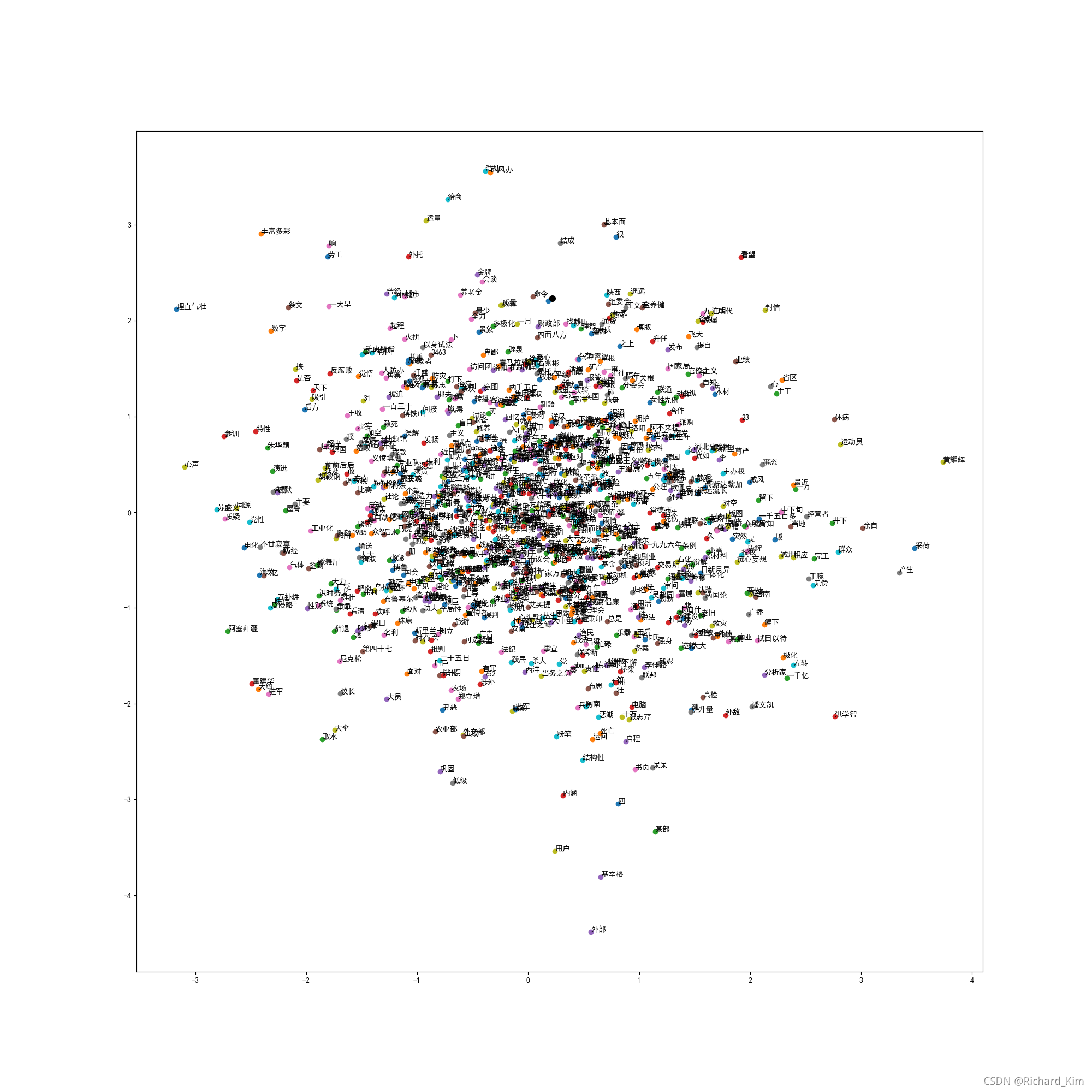
中文词向量:使用pytorch实现CBOW
整个项目和使用说明地址:链接:https://pan.baidu.com/s/1my30wyqOk_WJD0jjM7u4TQ提取码:xxe0关于词向量的理论基础和基础模型都看我之前的文章。里面带有论文和其他博客链接。可以系统学习关于词向量的知识。之前已经使用numpy手动实现skip-gram,现在使用pytorch框架实现CBOW这是pytorch官网的C...
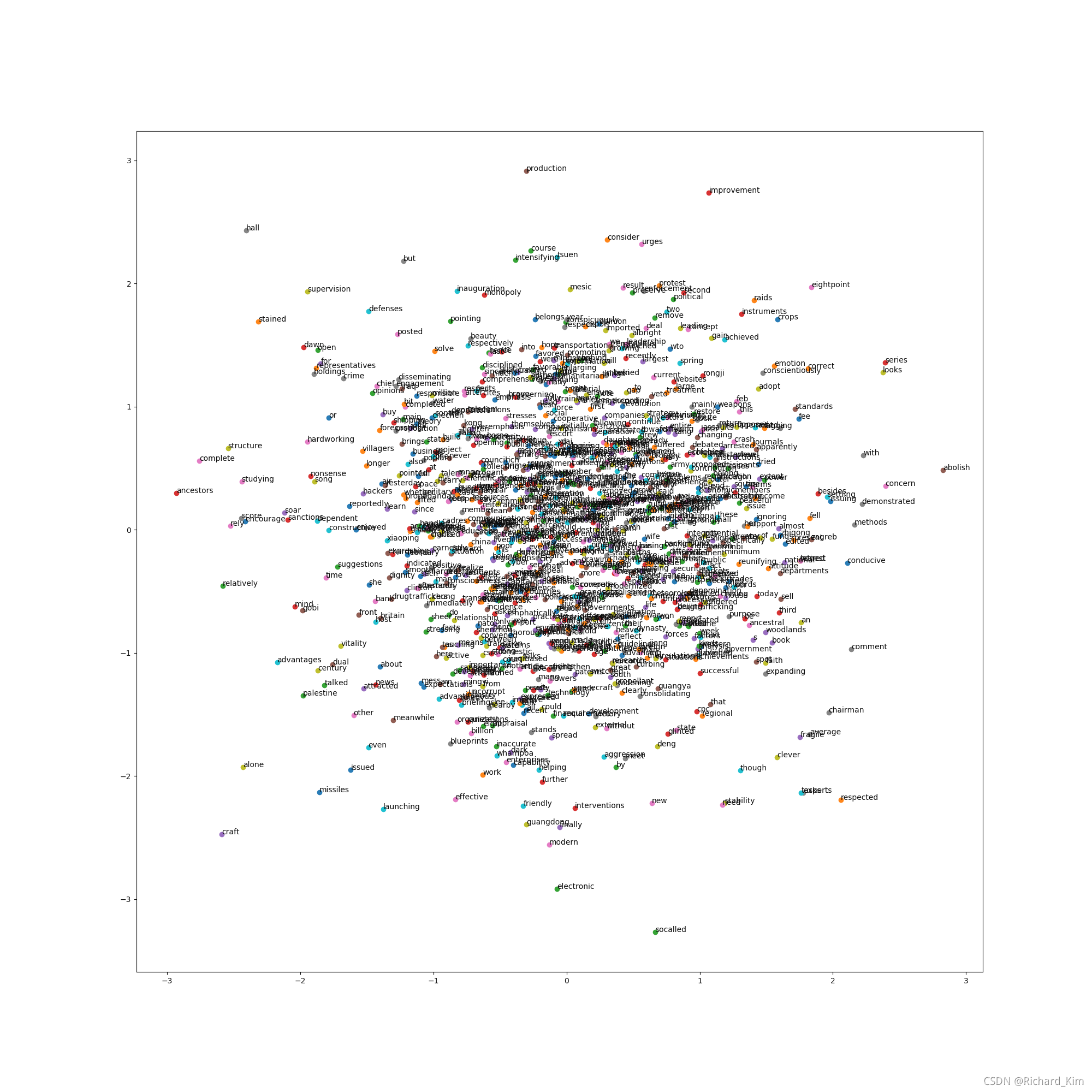
英文词向量:word2vec之skip-gram实现(不使用框架实现词向量模型)
代码中使用的语料:链接:https://pan.baidu.com/s/1nu_TqPtstB8brL2jJ-WtAg提取码:nwdo之前讲了中文的词向量如何训练,这里说说英文的,英语比中文简单多了,也不会有乱码问题,所以这里直接贴出代码。怎么跑起来可以看之前的文章#!/usr/bin/endimension python# -#-coding:utf-8 -*-# author:by ucas
pytorch下使用BiLSTM_CRF完成命名实体识别(BiLSTM_CRF的NER任务)
理论部分有空再写..全部实现实践代码环境: pytorch1.3.1; sklearn;tqdm训练语料:链接:https://pan.baidu.com/s/1Pa42E2q9fZ2zXLJ7vLvx8g提取码:o2rg--来自百度网盘超级会员V1的分享项目结构:#!/...
到底了