登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了如何配置Claude Code CLI工具以兼容DeepSeek API。主要内容包括:1) 环境要求(Node.js 18+、npm 9+、DeepSeek API Key);2) 通过npm全局安装Claude Code CLI;3) 关键配置步骤:创建~/.claude.json文件跳过验证,在~/.claude/settings.json中配置DeepSeek API端点、模型参
我是炫炫,人工智能专业的普通女生一枚。说实话我属于纯零基础选手😭,代码底子特别薄弱,现在啃 C 语言天天抓头发,随便敲几行代码全是报错,调不通程序的时候真的会偷偷 emo 好久。🥰开这个小窝就是用来记录我一点点补c语言基础、冲刺 408的全过程,专门留给和我一样起步困难的女孩子抱团取暖。也欢迎各位业界大佬路过,多多指点我的不足,🙈有学习建议都可以留在评论区,我会认真看、虚心吸收!讲真心话,C
在脉脉上看到一条神贴,GPT5.6发布之后,三种模式怎么选OpenAI 在 7 月 9 日发布了新版 ChatGPT 桌面端。此前独立运行的 Codex App 开始并入新版桌面端,但 Codex 并没有被取消,而是继续作为面向软件开发的专业模式存在。新版 ChatGPT 由三个主要入口组成:Chat:回答问题。Work:完成工作。Codex:完成软件工程。官方给出的区分也很明确:Chat 负责问
最近在闲鱼搜索 Codex 桌宠,结果比我想象中热闹。页面上既有 10 元的指令模板、十几元的互动工具,也有 99 元到 200 元的桌宠定制服务。同一个需求,已经被拆成模板、素材包、代制作和成品交付几档生意。来,我们直接把制作方法拆开。
Subject: Account Suspension Appeal - [your email]Hello Anthropic Support,My account (xxxxx@gmail.com) has been suspended. I believe this may bea mistake and would like to appeal.Account usage context:
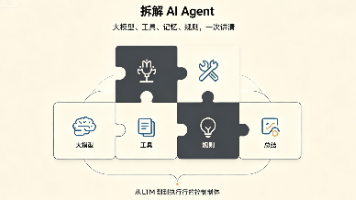
摘要: AIAgent(智能体)区别于传统大模型(LLM),具备自主决策与工具调用能力,能动态执行复杂任务。其核心组件包括:大脑(LLM)负责推理决策,工具(Tools)实现外部交互,记忆系统(短期/长期)保障上下文连贯与知识检索,任务规划(ReAct或Plan-and-Execute模式)拆分复杂目标。Agent通过“感知→推理→行动”循环逐步完成任务(如查天气→取消预约),并依赖消息压缩和人工
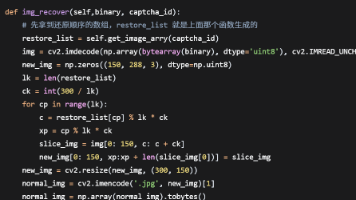
本文分享了破解文字点选验证码的经验:1)通过captcha_id生成乱序映射数组还原图片顺序,注意列映射方向;2)重点解决了加密参数ac长度不足的问题,从153字节补到900多字节才能通过严格站点验证。文章提供了拼图代码和关键思路,提醒开发者注意这两个易错点。最终验证通过证明参数长度和完整性对验证码破解至关重要。
这一段定义了桌子上不同物品的初始放置区域basket_init_region:篮子应该放在桌子的哪个位置。alphabet_soup_init_region、tomato_sauce_init_region 等:每种物品的初始放置范围(x, y 坐标区间)。contain_region:篮子里面的“可容纳区域”。这些区域保证了任务的可重复性(每次初始化位置都在一定范围内)。lisp(:fixtur
之前对代码编译很是畏难,当然现在亦如此,总是听朋友说AI让编程变得特别简单,暂且不论简单与否,因为不同的人使用的方式不同,对方便的概念亦不同,但毫无疑问的是,可以为编程者提供诸多便利。但新学起来,没资料学可怕,资料太多亦多也可怕,多得不知从何去学,这就是困惑,但无论怎么样,考验的是学习能力。诸多文章里都谈到了可以带来革命性替代的作用,真愿如此,学得慢些又如何,让思维转换为人工智能时代的应有模样,让
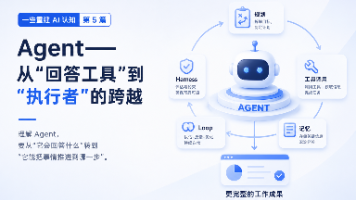
Agent 不是"更聪明的聊天机器人",它真正改变的是交付物:Prompt 给你一段可用文字,Agent 把一个目标推进成一份更完整的工作成果。这个变化背后,不只是模型能力变强,而是规划、工具调用、记忆、Loop 和 Harness 这些系统能力开始接上来。理解 Agent,要从"它会回答什么"转到"它能把事情推进到哪一步"。
Java SEjava语言的标准版,用于桌面应用开发,是其他两个版本的基础学习SE为之后的Java EE开发打基础Java MEjava语言的小型版,用于嵌入式电子设备或者小型移动设备安卓和鸿蒙可以用ME开发Java EEjava语言的企业版,用于Web方向的网站开发。浏览器+服务器。
反射的理解、Java代理模式的总结(未完),看八股,读文献
初步了解Java代理模式(完结),Spring AOP,复现yolo的环境配置、移除链表元素
《快乐记单词》是一款专为3-8岁儿童设计的英语拼写学习游戏,采用React18+Vite技术栈开发。核心功能包括:1)互动拼写系统,支持点击字母完成单词组合;2)语音播放功能,点击中文释义可听标准发音;3)智能反馈机制,实时验证答案并给予鼓励性评价;4)多主题词库,涵盖水果、动物、颜色等8类生活词汇;5)游戏化设计,包含倒计时动画、成就系统等趣味元素。该应用特色在于:响应式布局适配多设备、60fp
本文以通俗易懂的方式介绍了Java数据库编程的核心知识,从JDBC基础到实战应用。首先讲解了建立数据库连接的步骤,通过代码示例演示了查询、更新数据的基本操作。重点说明了PreparedStatement防止SQL注入的优势,以及连接池提升性能的原理。随后以博客系统开发为例,详细展示了用户管理、文章发布、评论、标签、点赞等功能的实现过程,涵盖事务处理、数据库设计等关键知识点。文章通过生动比喻(如&q
本文介绍了JavaWeb开发中的核心技术Servlet和JSP。Servlet作为服务器端小程序,负责处理业务逻辑,接收请求并返回动态响应;JSP则允许在HTML中嵌入Java代码,用于生成动态网页内容。文章详细讲解了Servlet的生命周期、JSP的基本语法,并通过登录注册等实战案例展示了二者如何协同工作。此外,还探讨了表单处理、会话管理、数据库交互等进阶技巧,以及性能优化的关键点。掌握这些核心
XML和JSON是两种常见的数据格式,广泛应用于数据存储和传输。XML结构严谨,适合描述复杂层次关系;而JSON轻量灵活,便于解析生成。本文对比了二者的特点,并详细介绍了Java中处理XML的DOM/SAX解析方法,以及使用Gson/Jackson库处理JSON的实践技巧。同时演示了XML与JSON相互转换的实现方案,帮助开发者根据实际需求选择合适的数据格式。掌握这些数据处理技术,将有效提升Jav
Java反射机制赋予程序在运行时自我检查与操作的能力。本文深入浅出地讲解反射的获取方式、查看类信息、动态操作对象及访问私有成员等核心内容,配合丰富的代码示例,如查看类的字段、方法及动态调用方法等,并辅以中文打印输出增强理解。同时探讨反射的优缺点与应用场景,助您全面掌握反射技术,在框架开发与插件系统等场景中灵活运用,提升编程能力与项目质量。
本文介绍了Java网络编程的核心概念,通过生动比喻和代码示例讲解TCP/UDP通信机制。TCP模拟可靠"快递专车"服务,UDP则类似快速"群发短信"。文章包含TCP单线程/多线程服务端实现,以及UDP通信示例,并进阶讲解Java NIO非阻塞IO技术。所有示例均配有详细注释,将网络通信类比为"商店服务顾客"、"餐厅多线程接待&q
Python 学习笔记摘要函数部分函数定义:使用 def 关键字定义函数,可重复使用的代码段参数传递:支持形式参数和实际参数,参数数量不限返回值:使用 return 返回结果,无返回值时默认返回 None变量作用域:分为局部变量和全局变量,使用 global 声明全局变量综合练习:实现了一个简单的 ATM 机功能,包括查询余额、存款、取款等操作数据容器Python 提供了五种主要数据容器,这些容器
本文全面介绍了Java中的加密解密技术,包括对称加密(AES)、非对称加密(RSA)和哈希算法(SHA系列)三大类。对称加密使用相同密钥进行加解密,速度快但密钥分发困难;非对称加密采用公钥/私钥机制,解决了密钥分发问题但速度较慢;哈希算法用于数据完整性验证,生成不可逆的"数字指纹"。文章通过代码示例展示了各类算法的Java实现,并建议在实际应用中综合使用这些技术,如用AES加密
类的定义:类是创建对象的蓝图或模板,它封装了一组相关的数据和操作这些数据的方法。类定义了对象将拥有的属性和行为。类的声明语法"""类的文档字符串"""# 类属性(所有实例共享)"""构造方法,初始化实例属性""""""实例方法"""# 方法体对象是类的实例:对象是根据类定义创建的具体实体,包含类中定义的数据和方法的具体实现。创建对象的语法# 创建类的实例(对象)clas
本文深入探讨了C++基础特性,包括引用的进阶用法、内联函数和nullptr关键字。重点解析了const引用与临时对象的引用注意事项,指出引用权限不可放大但可缩小;对比了指针与引用的底层实现差异;介绍了内联函数的优化机制及适用场景;最后通过函数重载示例说明了nullptr相比NULL的优势。这些内容为C++初学者提供了重要的语言特性理解,帮助开发者规避常见错误并提升代码效率。
Java 基础反射(Reflection)详解与实战案例
本文介绍了C++中的三个重要特性:缺省参数、函数重载和引用机制。1. 缺省参数分为全缺省和半缺省,半缺省必须从右向左连续定义,且只能在函数声明中指定缺省值;2. 函数重载允许同名函数通过参数个数、类型或顺序不同而区分,但不支持仅返回值不同的重载;3. 引用是变量的别名,不占用额外内存,常用于函数参数传递以替代指针,但链表等数据结构仍需使用指针。文章还通过实例分析了引用作为形参和返回值的正确使用方法
自顶向下,逐步细化。将要实现的功能分解为一系列步骤,依次完成这些步骤。如果某个步骤复杂,可以进一步细化为子步骤。学员提出报名,提供相关材料学生缴纳学费,获得缴费凭证教师凭借学生缴费凭证进行分配班级班级增加学生信息面向过程就是将这些步骤依次执行。面向对象编程的核心是实体和动作。提出、提供、缴纳、获得、分配、增加。学生提出报名学生提供相关资料学生缴费机构收费教师分配教室班级增加学生信息将功能封装到实体
100 个 Java 程序员日常高频使用 的网站/工具,按「官方根站 → 学习教程 → 算法刷题 → 开源项目 → 工具/社区 → 资讯/博客」6 大类分层整理
微信小程序样式不生效问题排查:当组件样式无效时,首先检查开发者工具的wxss文件是否空白。常见原因是页面被错误注册:在HBuilder创建页面时默认勾选注册,导致该页面同时出现在pages.json中。解决方法:删除pages.json中对应的页面注册信息,即可恢复组件正常使用和样式显示。此问题源于页面与组件注册冲突。
Python中的None是一个特殊常量,表示"空值"。函数显式或隐式(无return语句)都会返回None。常见场景包括内置方法(如list.append)、初始化函数、数据查询等。检测None应使用is而非==,避免自定义对象重载==导致误判。使用时需防范NoneType错误,可采用安全访问(getattr)、条件判断或类型提示(Optional)。最佳实践包括明确文档说明、
本文全面介绍了Python函数的核心概念与用法,涵盖函数基础、参数传递、返回值、作用域、高级特性及最佳实践。主要内容包括:1)函数定义与调用;2)位置/默认/可变参数的灵活使用;3)返回值处理;4)局部/全局变量作用域;5)高阶函数特性如闭包与生成器;6)装饰器应用;7)lambda匿名函数;8)函数设计的最佳实践,如单一职责原则和类型提示。通过系统讲解,帮助开发者掌握Python函数式编程的核心
Java泛型是一种类型参数化机制,允许在类、接口和方法中使用类型参数,从而在编译时确定具体类型。泛型提供了类型安全(编译时检查类型转换)、消除强制类型转换和提升性能等优势。其底层通过类型擦除实现,运行时泛型类型会被擦除为Object或指定边界类型。通配符<? extends T>和<? super T>分别用于限制类型的上界和下界,影响读写操作。由于类型擦除,ArrayLi
参数类型语法特点适用场景位置参数按顺序传递必需参数默认参数有默认值可选参数关键字参数按名称传递提高可读性可变位置参数任意数量位置参数处理不定数量输入可变关键字参数任意数量关键字参数处理配置选项仅关键字参数必须关键字传递强制明确参数含义。
本文分析了Java开发中常见的NullPointerException问题,重点讲解了多层对象结构初始化时的空指针异常根源和解决方案。通过用户管理系统的实际案例,指出引用类型默认值为null的特性是问题本质。提供了手动初始化、定义时初始化和构造方法初始化三种解决方案,并扩展到多层嵌套对象的初始化场景。文章强调Lombok注解不会改变Java默认初始化规则,建议开发者根据业务场景选择合适的初始化方式
C++11语法讲解
C++4种类型转化用途
深耕生物医学、以论文课题、临床研究为主,追求稳定、高效、合规,垂直科研工具MedPeer才是归宿。MedPeer无需任何编程、配置操作,网页端、手机APP一键登录,科研绘图、论文写作、智能翻译、文献检索全部模块化封装,可视化操作界面类似平板操作系统,支持自定义壁纸、应用组件,零基础科研人上手即用,彻底规避技术配置门槛。客观来说,Codex绝对是顶尖级别的AI工具,它像一把功能齐全的瑞士军刀,上限极
Java基础——字符串练习——拼接、反转、转换等功能练习
学习方法
——学习方法
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AtomGit AI 社区
AtomGit AI 社区




 智能体开发者社区
智能体开发者社区
 AMD开发者中国社区
AMD开发者中国社区


 DAMO开发者矩阵
DAMO开发者矩阵
 人工智能6S服务平台
人工智能6S服务平台


 AI Agent技术社区
AI Agent技术社区


























 openEuler 社区
openEuler 社区


