




- @HUSTHY
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:作者从PyCharm切换到更轻量的VSCode,因其支持多项目开发、远程调试和Docker连接。但在使用conda环境调试时遇到问题:通过右下角切换环境后调试报错,发现环境路径缺失/bin/python。解决方法是通过F1重新选择Python解释器获取完整路径。该问题可能是VSCode的设计缺陷,导致环境切换时路径信息丢失。终端运行不受影响,因会自动执行conda激活命令。
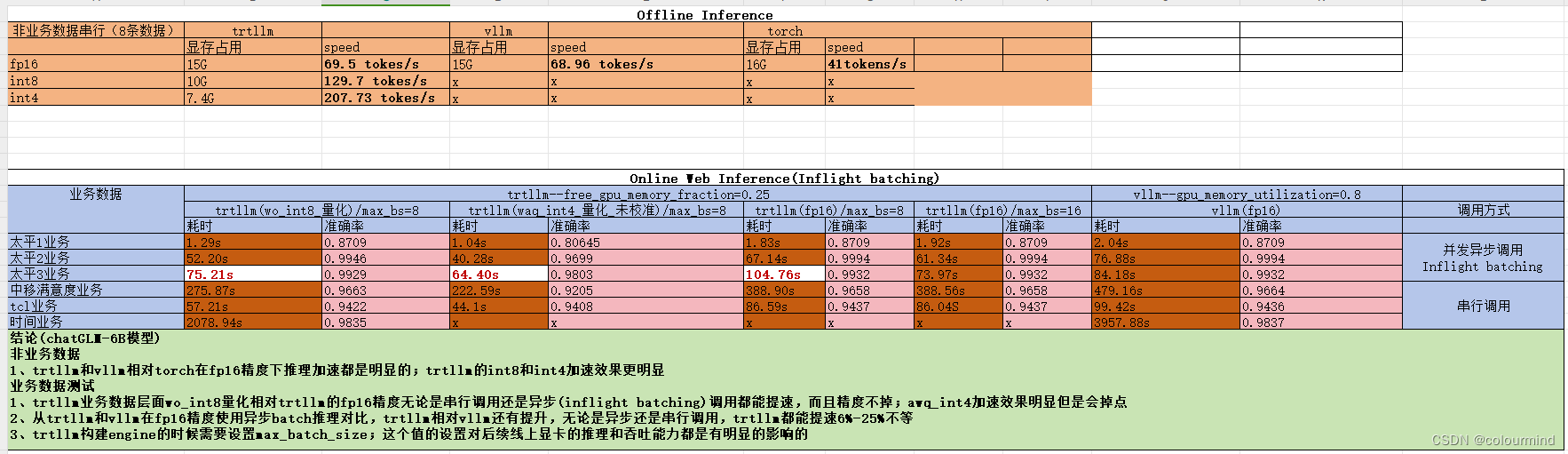
这篇博客就专门对语言大模型推理框架Vllm和TensorRT-LLM在ChatGLM2-6B模型上的推理速度和效果进行一个对比。主要的内容分为三块,第一块简单介绍一下vllm和TensorRT-llM框架的特色和基本技术点,由于篇幅的原因关于技术的原理就不做多的介绍(每个技术点都可以拧出来写一篇文章,工作量非常大);第二块内容就是介绍一下环境安装和重要的API,并且提供一个web推理服务;最后一块
apex的AMP库和pytorch中自带的amp——自动混合精度了解一下算法原理参考文章Pytorch 1.6使用自动混合精度训练(AMP)使用AMP得到更高效的PyTorch模型...
目录一、过拟合的表现以及判定1、模型过拟合的表现2、模型过拟合的判定二、过拟合的原因三、过拟合的解决方案1、模型层面2、数据层面3、训练层面4、其他最近在做NLP相关任务的时候,训练神经网络模型的过程中,遇到过模型过拟合的情况,到底怎么解决过拟合,来提高模型的性能,不是特别的清晰。以前学习机器学习的时候,也讲到了模型的过拟合,对里面怎么来解...
这篇博客就专门对语言大模型推理框架Vllm和TensorRT-LLM在ChatGLM2-6B模型上的推理速度和效果进行一个对比。主要的内容分为三块,第一块简单介绍一下vllm和TensorRT-llM框架的特色和基本技术点,由于篇幅的原因关于技术的原理就不做多的介绍(每个技术点都可以拧出来写一篇文章,工作量非常大);第二块内容就是介绍一下环境安装和重要的API,并且提供一个web推理服务;最后一块
目前随着模型规模越来越大,对于没有很多算力的人来说,使用大模型的门槛越来越高,因此ChatGLM提供的模型支持,fp16、int8和int4的量化,来降低加载模型的显存,让更多的人能使用该大模型。

最近在看迁移学习相关内容,转载一篇入门学习,主要是一些概念性质的东西。原文地址:迁移学习——入门简介目录一、简介二、迁移学习常用概念三、迁移学习的分类按照学习方式分四类:按迁移情境分三类按特征空间分两类:四、迁移学习热门研究领域域适配问题 (domain adaptation)迁移方法:一、简介背景:现如今数据爆炸:对机器学习模型...
摘要:作者从PyCharm切换到更轻量的VSCode,因其支持多项目开发、远程调试和Docker连接。但在使用conda环境调试时遇到问题:通过右下角切换环境后调试报错,发现环境路径缺失/bin/python。解决方法是通过F1重新选择Python解释器获取完整路径。该问题可能是VSCode的设计缺陷,导致环境切换时路径信息丢失。终端运行不受影响,因会自动执行conda激活命令。
文本对话是一个很复杂的任务,难度比较大。按照对话文本产生的方式可以分为检索式和生成式;按照技术实现的方式可以分为端到端和pipeline的方式。为了保证对话的多样性和丰富性,以及减少流程的繁琐例如构建对话管理、对话理解等模块,我们基于GPT2模型以及GPT2-chat项目在保险领域进行了中文文本生成对话应用的尝试。总而言之,本文并不是一个创新性的内容,更多的是一种现有技术和模型在业务中的尝试和验证
大模型时代,模型的推理效率尤为重要,推理速度的快慢和模型生成的质量好坏对用户的体验影响很大。大模型生成速度慢,生成效果好;小模型推理速度快,但是推理质量稍差。当前大模型推理速度满不足不了业务实效性需求,小模型不能满足业务质量指标的情况下存不存在一种业务在实际落地的时候最优选择呢?google论文和deepmind论文给出了相同思路的解决方案,也就是这篇博客要谈到的东西Speculative Dec