登录社区云,与社区用户共同成长
邀请您加入社区
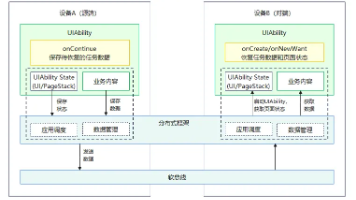
在用户使用设备的过程中,当使用情境发生变化时(例如从室内走到户外或者周围有更适合的设备等),之前使用的设备可能已经不适合继续当前的任务,此时,用户可以选择新的设备来继续当前的任务,原设备可按需决定是否退出任务,这个就是跨端迁移的场景。常见的跨端迁移场景实例:在平板上播放的视频,迁移到智慧屏继续播放,从而获得更佳的观看体验;平板上的视频应用退出。在应用开发层面,跨端迁移指在A端运行的UIAbilit
编译构建流程、编译脚本编写、目录规则、独立编译单个组件、独立编译芯片解决方案等介绍请见 编译构建子系统介绍。
MySQL迁移人大金仓的私有化免费方案推荐 随着信创政策推进,MySQL向人大金仓KingbaseES的迁移需求激增。主流工具如阿里云DTS、DataX、Kettle等存在国产数据库适配差、增量同步难、需外网等问题。 推荐使用轻量级工具DataMover,其优势包括: ✅ 原生支持KingbaseES,自动处理类型映射 ✅ 支持全量+增量同步(时间戳/CDC) ✅ 纯内网私有化部署,数据不出网 ✅
本文介绍了如何在星图GPU平台上自动化部署Git-RSCLIP镜像,高效开展遥感图像理解任务。基于预训练的视觉语言能力,该镜像支持小样本迁移学习,可快速适配农田识别、城市变化检测等典型遥感分析场景,显著降低标注成本并提升地物解译效率。
本文介绍了如何在星图GPU平台上自动化部署Git-RSCLIP图文检索模型,实现特定领域的精准图文匹配。通过迁移学习技术,用户可快速微调该模型,应用于医疗影像检索、电商商品匹配等场景,提升专业领域的内容检索效率。
本文介绍了如何在星图GPU平台自动化部署Git-RSCLIP镜像,实现跨领域遥感图像的高效分析。该平台支持快速搭建环境,通过Git-RSCLIP的迁移学习能力,仅需少量样本即可完成农业监测中的作物识别与分类任务,显著提升遥感图像处理效率。
本文介绍了如何在星图GPU平台上自动化部署Git-RSCLIP图文检索模型,并探讨了其迁移学习技巧与实践。该平台简化了部署流程,用户可快速构建高效的图文检索系统,典型应用于电商商品搜索、医疗影像分析等场景,显著提升跨模态信息的匹配与检索效率。
本文介绍了如何在星图GPU平台上自动化部署Git-RSCLIP镜像,实现遥感图像-文本跨模态模型的快速领域适配。通过该平台,用户可轻松将通用模型迁移至农业监测等特定场景,利用少样本学习和特征对齐技术,快速构建高效的图像分类与描述应用。
Oracle 迁移上云,首选阿里云 PolarDB Oracle 兼容版:95%+ 语法兼容、ADAM + DTS 工具链、零停机切换、TCO 节省 60%–90%、金融政企规模化案例齐全。立即在阿里云控制台开通 PolarDB Oracle 兼容版,启动 ADAM 评估,开启您的去 O 之路。
摘要 本文记录了作者使用Codex开发Agent完成"博士猫"AI个人知识库MVP的全过程。该项目核心功能包括支持PDF/EPUB/Markdown/Word文档导入,实现中文全文与语义混合检索,并基于检索证据生成带真实引用的回答。项目最终封装为macOS应用。 开发过程中,作者对AI编程的认识经历了三个阶段转变:从最初的"自动生成完整产品"的误解,到发现其作为协作开发伙伴的价值,最终形成"人负责
在当今数字化时代,企业面临着大量的数据和复杂的业务场景。企业AI Agent作为一种能够模拟人类行为和决策的智能系统,在提高企业效率、降低成本等方面具有巨大潜力。然而,传统的机器学习方法通常需要大量的标注数据来训练模型,这在一些领域尤其是数据稀缺的领域是难以实现的。迁移学习作为一种能够将一个领域的知识迁移到另一个领域的技术,为解决这一问题提供了有效的途径。本文的目的是深入探讨企业AI Agent的
Java 8引入的Stream API为集合操作带来了革命性的变化。它允许开发者以声明式的方式处理数据集合,使代码更加简洁、易读。Stream API不仅提高了代码的可维护性,还通过并行处理能力显著提升了大数据集的处理效率。与传统的循环操作相比,Stream操作更加函数式,能够有效减少中间变量的使用。
Cleer Arc5通过迁移学习实现跨场景语音识别优化,结合预训练与本地微调,在开放式耳机中实现低信噪比环境下的高精度语音捕捉。系统利用端侧NPU、波束成形和场景自适应技术,完成隐私安全、低功耗的个性化语音交互体验。
将所有的分类组成一个二叉树每个类别是一个叶子节点,预测一个词的概率不是直接算这个词的softmax而是从根节点出发走到这个词的叶子节点,每一步都是一个二分类问题,最终概率是路径上决策概率的乘积。传统的softmax的时间复杂度为L(labels的数量), 但是使用层次化softmax之后时间复杂度的log(L) (二叉树的高度和宽度的近似), 从而在多分类的场景提高了效率.2.选出两个权重值最小的
斯坦福与康奈尔:机器人先"玩耍"再"精通",精密装配成功率高达60%
本文解析了AutoGen Studio中的智能体迁移学习技术,探讨了如何让多智能体团队快速适应新任务。在星图GPU平台上,用户可以自动化部署AutoGen Studio镜像,快速搭建多智能体开发环境,并将其应用于如智能客服、内容创作等场景,实现团队协作能力的快速复用与迁移,显著提升开发效率。
在将多模态OCR业务从GPU迁移至昇腾NPU的过程中,由于硬件架构的差异,原有推理链路在性能和资源管理方面出现了新的瓶颈。本文基于一套五层架构的文档解析系统,详细记录了在昇腾NPU环境下的性能调优过程,涵盖推理调用结构重组、并发模型重构以及底层内存分配策略调整。通过一系列优化,最终在单卡单进程场景下实现了显著的性能提升和资源优化。该文档解析系统采用流水线架构,核心功能是对PDF或图片进行版面分析,
本文深入探讨了最大均值差异(MMD)在迁移学习中的应用,通过Python+PyTorch实战演示如何利用MMD解决分布对齐问题。相较于传统KL散度,MMD基于核方法直接比较样本分布,特别适合处理图像风格迁移等高维数据任务。文章从原理推导到代码实现,详细介绍了多核MMD策略及其在图像风格迁移中的优化技巧。
直接运行就能跑通的猫狗图像二分类项目,用TensorFlow/Keras搭建CNN模型,支持从原始图片加载、自动划分训练/验证/测试集、标准化预处理(kaggle_process.py),到迁移学习微调(transerfer_learning.py)、自定义模型构建(model_build.py)和端到端训练(code_train.py)。数据已整理在cats_and_dogs_small目录下,
迁移学习是解决小样本图像分类问题的核心范式,其原理在于复用预训练模型的通用视觉特征,仅微调任务相关层以降低数据与算力成本。在Java技术栈中,DJL(Deep Java Library)提供了引擎无关、内存可控、模型即服务的工业级支持,显著提升CV模型在Spring Boot等生产环境中的可部署性与稳定性。结合ResNet嵌入层冻结、分层学习率、NDManager显式管理等关键技术点,DJL让Ja
计算机视觉中的图像分类技术是深度学习的核心应用之一,通过卷积神经网络(CNN)自动提取图像特征实现物体识别。基于迁移学习的方法可以利用ImageNet等大型数据集预训练模型,显著提升小规模专项任务的准确率。在PyTorch框架下,开发者可以快速实现VGG、ResNet等经典架构的迁移适配,结合数据增强和模型量化技术优化部署效率。这类技术在智能环保领域具有重要价值,如本项目的智能垃圾分类系统,通过P
摘要 本文实现了一套完整的人脸考勤系统,基于ResNet50迁移学习技术,在5CelebrityFaces数据集(93张样本)上训练5分类人脸识别模型,准确率达98.92%。系统包含OpenCV人脸检测、数据增强、模型训练与评估模块,并集成考勤业务逻辑(签到去重、迟到/早退判定)及Excel/CSV报表自动导出功能。代码支持Kaggle Notebook一键运行,涵盖图像分类、工程化落地全流程,适
本文探讨了深度学习技术在皮肤癌图像分类中的应用和进展。文章首先介绍了皮肤癌的严重性和早期检测的重要性,随后详细阐述了使用卷积神经网络(CNN)和迁移学习等技术在自动化皮肤癌检查和诊断方面的最新研究。文章重点介绍了在ISIC 2019数据集上实施的基于深度学习的自动系统,该系统通过数据预处理和增强、迁移学习以及微调预训练模型等方法,显著提高了对皮肤病变图像分类的准确性。
PyTorch与TensorFlow2.x深度学习框架对比摘要 本文对比了两大主流深度学习框架PyTorch和TensorFlow2.x的核心特点。PyTorch以简洁灵活著称,采用动态计算图,调试直观,学习曲线平缓,适合科研和快速原型开发;TensorFlow2.x则注重工业级应用,提供全链路工具链,支持跨平台部署,适合生产环境。建议入门者根据目标选择:科研优先选PyTorch,工业应用选Ten
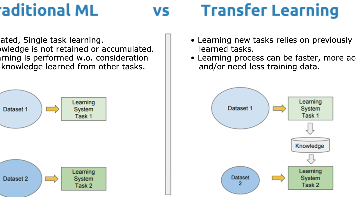
1.传统机器学习(Traditional Machine Learning)传统机器学习是一类通过算法让计算机从特定任务的标注数据中自主学习规律,进而对未知数据进行预测或决策的技术。其核心逻辑是“为单一任务定制学习模型”,即针对每个新任务,都需要重新收集足量标注数据、设计特征工程,并训练全新的模型。模型的学习过程局限于当前任务的数据集,无法利用其他任务的知识经验,学习结果也仅适用于当前任务场景。
迁移学习
——迁移学习
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 HarmonyOS开发者社区
HarmonyOS开发者社区


 AI编程社区
AI编程社区




 2048 AI社区
2048 AI社区

 AI Agent技术社区
AI Agent技术社区

 DAMO开发者矩阵
DAMO开发者矩阵



 人工智能6S服务平台
人工智能6S服务平台

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区