- @a2875254060
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目前来看,RAG方向的人才需求非常旺盛,AI搜索领域各大厂都在加速布局,对Agent、RAG技术的要求也在不断提高。保持对技术社区的敏感度:大模型技术更新太快,只有持续关注、持续学习,才能跟上节奏;强化学习能力:转型过程中会遇到很多新知识点,快速学习、快速落地的能力,比现有技术储备更重要;培养产品思维:技术是工具,能解决业务问题的技术,才是有价值的技术,这也是区别于普通开发者的核心竞争力。现在大家
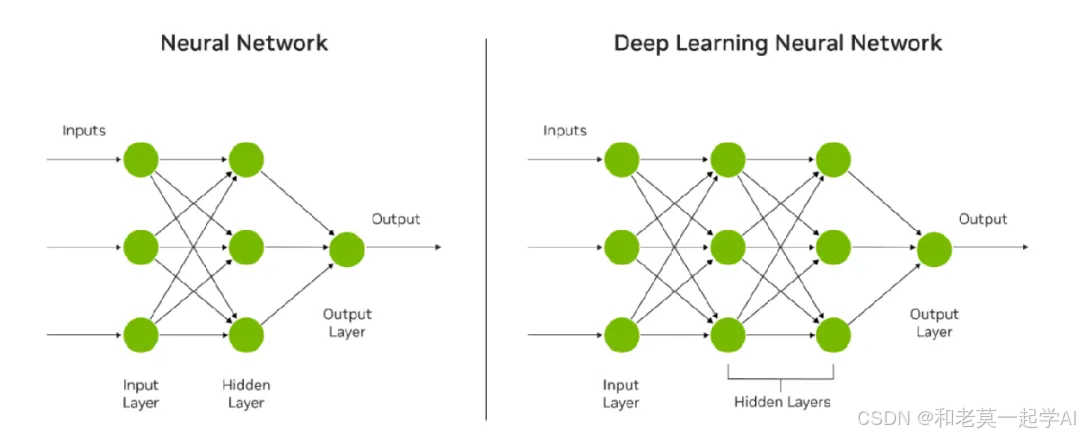
在当今的技术讨论中,“人工智能”(AI)、“机器学习”(ML)、“深度学习”(DL)和“大模型”(LLM)等术语常被混用,以至于令人困惑。本文将简要梳理这些概念,帮助读者清晰理解它们的关系与区别。对于人工智能(AI)的定义,业界其实并没有一个统一的、公认的说法,我比较喜欢的是中国科学院院士谭铁牛在《求实》上发表的一篇文章里对人工智能的定义——“人工智能是研究开发能够模拟、延伸和扩展人类智能的理论、
病理;人工智能;Nature随着人工智能(AI)技术的快速发展,多模态生成式AI助手在多个临床领域展现出巨大的潜力。在病理学领域,计算病理学的进步使得基于图像和语言的综合分析成为可能。2024年6月12日,哈佛医学院的科学家针对名为PathChat的多模态生成式AI助手的研究发表在_Nature_杂志。结果显示:PathChat能够理解并处理视觉和语言输入,提供精确的病理学相关查询响应;。而且,与

本文介绍了如何基于LoRA对Qwen模型进行微调,涵盖了从环境准备到单机单卡、单机多卡训练的全过程。首先,需要克隆Qwen仓库并安装相关依赖包,接着下载模型文件。单机单卡训练通过执行Python脚本进行,详细解释了各个参数的含义。单机多卡训练则通过修改脚本并运行torchrun命令实现。微调完成后,模型可以与原始模型合并并保存,最终通过测试代码验证微调效果。文章还提供了测试数据的GitHub仓库链

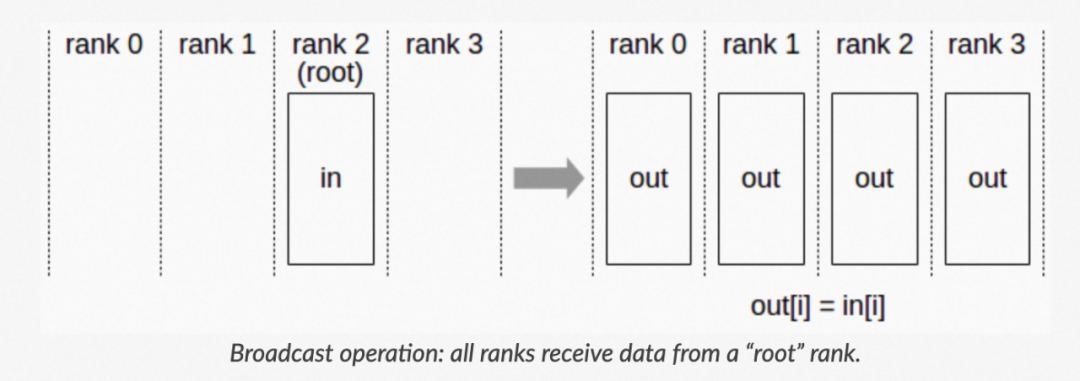
随着 ChatGPT 的火爆出圈,大模型也逐渐受到越来越多研究者的关注。有一份来自 OpenAI 的研究报告 (Scaling laws for neural language models) 曾经指出模型的性能常与模型的参数规模息息相关,那么如何训练一个超大规模的 LLM 也是大家比较关心的问题,常用的分布式训练框架有 Megatron-LM 和 DeepSpeed,下面我们将简单介绍这些框架及
本文介绍了2025年国内外AI大模型排名情况。国内有通义千问、豆包大模型等多个模型,各有核心能力与应用场景,且不断更新迭代。国外GPT‑4o、Gemini 2.0 Ultra等模型也各有特性,如多模态输入、大规模参数等。如何学习AI大模型?最先掌握AI的人,将会比较晚掌握AI的人有竞争优势这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。倘若大家对大模型抱有兴趣,那么这套大模型学习
在自然语言处理(NLP)中,数据预处理,又可称数据清洗,是指将原始文本数据转换成适合机器学习模型处理的格式的过程。根据特定领域的术语或特定的数据集特性,可能需要开发自定义的预处理规则。在以上方法中,我只挑选了部分比较常用且重要的方法进行了详细地分析和讲解并分别给出了代码示例便于大家进一步理解或者运用。数据预处理是NLP任务成功的基础,它有助于提高模型的性能和准确性。预处理步骤的选择和实现取决于具体

创建anaconda环境,记得使用python3.11,anaconda在linux上安装和创建环境的过程可以去其他教程查找,暂且不多赘述。

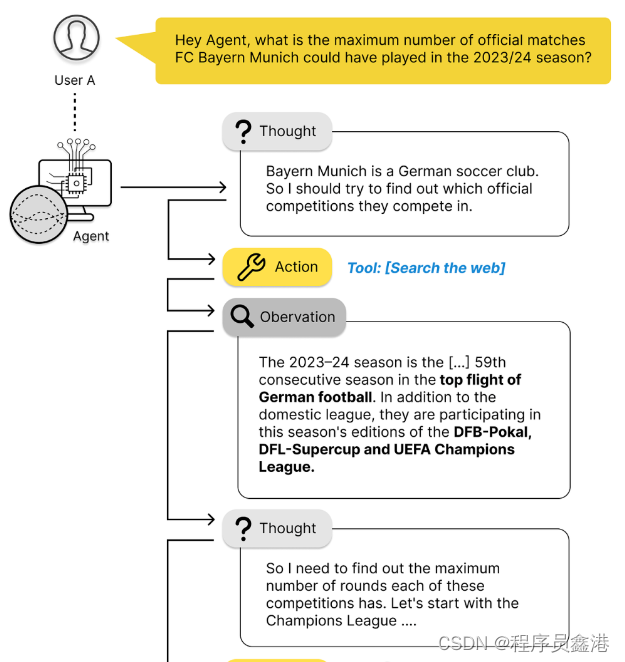
科幻电影和间谍电影中经常出现一种中央人工智能,它与主角交流,搜索互联网和各种秘密数据库,引导主角完成任务。例如电影《钢铁侠》中的贾维斯(J.A.R.V.I.S.)就是一个典型例子。是什么让贾维斯如此特别?钢铁侠甚至不需要告诉它如何解决问题,它会自己找到方法。这正是我们希望通过智能体实现的目标。我们人类将复杂问题分解成更小的子任务和假设,并试图一步一步地证明或证伪它们,以逐步接近解决更大的难题。我们
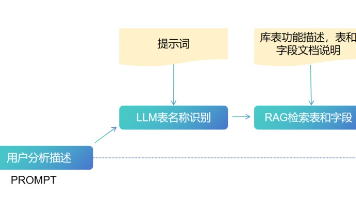
文章介绍了如何构建自然语言转SQL的数据分析智能体,使用Qwen-Text2SQL模型将自然语言查询转化为可执行SQL,结合DeepSeek-R1作为智能体大脑,通过langchain框架搭建AI Agent,并利用Rag知识库优化提示词。该智能体能将非技术人员的自然语言需求转化为SQL查询,降低数据分析门槛,提升效率,让更多人能够利用数据进行决策,释放数据价值。