




- @weixin_44649780
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先一定要明确自己的json格式,把自己的数据集设置为yolo所需要的格式。#Json文件属性不同,提取信息不同。
ICCV的全称是IEEEInternationalConferenceonComputerVision,即国际计算机视觉大会,是公认的三个会议中级别最高的。它的举办地方会在世界范围内选,每两年召开一次(奇数年份)。dblpICCVECCV的全称是EuropeanConferenceonComputerVision,即欧洲计算机视觉国际会议。每两年召开一次,与ICCV正好错开(偶数年份)。ECCV官
我们应该如何整合来自互补传感器的表示以用于自动驾驶?基于几何的融合已经显示出感知的前景(例如对象检测、运动预测)。然而,在端到端驾驶的背景下,我们发现基于现有传感器融合方法的模仿学习在具有高密度动态代理的复杂驾驶场景中表现不佳。因此,我们提出了TransFuser,这是一种使用自注意力集成图像和LiDAR表示的机制。我们的方法使用多种分辨率的变压器模块来融合透视图和鸟瞰图特征图。我们在具有挑战性的
环境:win10, VS code, 远程服务器Ubuntu16.04(远程服务器上已经安装好了dockers),
快速创建属于自己的GitHub页面~
我们应该如何整合来自互补传感器的表示以用于自动驾驶?基于几何的融合已经显示出感知的前景(例如对象检测、运动预测)。然而,在端到端驾驶的背景下,我们发现基于现有传感器融合方法的模仿学习在具有高密度动态代理的复杂驾驶场景中表现不佳。因此,我们提出了TransFuser,这是一种使用自注意力集成图像和LiDAR表示的机制。我们的方法使用多种分辨率的变压器模块来融合透视图和鸟瞰图特征图。我们在具有挑战性的
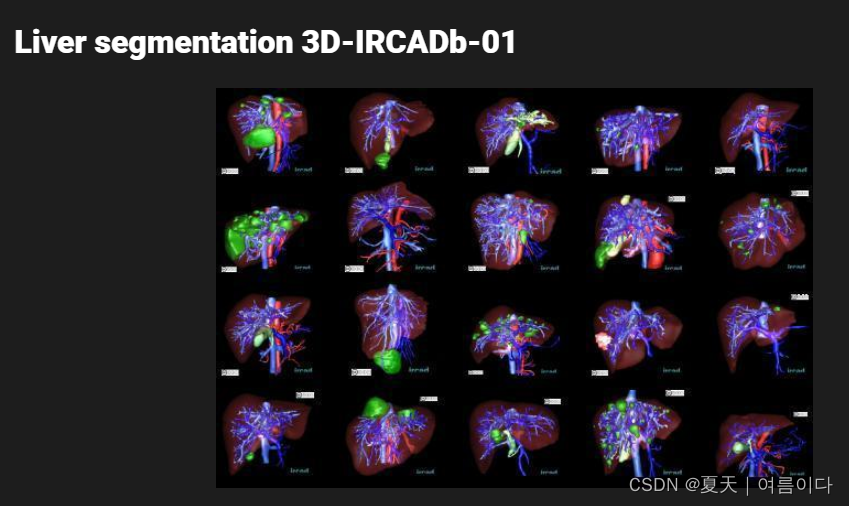
计算机视觉分支-医学影响相关数据集概况。
ICCV的全称是IEEEInternationalConferenceonComputerVision,即国际计算机视觉大会,是公认的三个会议中级别最高的。它的举办地方会在世界范围内选,每两年召开一次(奇数年份)。dblpICCVECCV的全称是EuropeanConferenceonComputerVision,即欧洲计算机视觉国际会议。每两年召开一次,与ICCV正好错开(偶数年份)。ECCV官
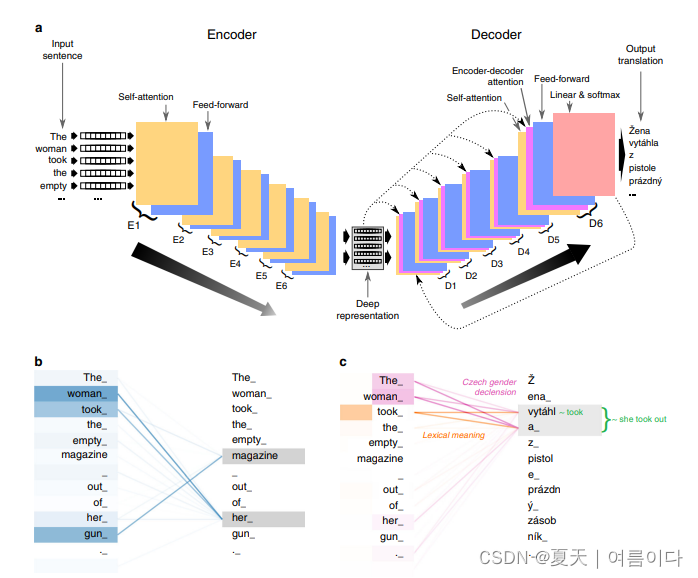
长期以来,人们一直认为人类翻译的质量对于计算机翻译系统来说是无法实现的。在这项研究中,我们提出了一个深度学习系统CUBBITT,它挑战了这一观点。在人类法官的上下文感知盲测评估中,CUBBITT在保留文本含义(翻译充分性)方面显着优于专业机构的英语到捷克语新闻翻译。虽然人工翻译仍然被评为更流畅,但CUBBIT被证明比以前最先进的系统更流畅。此外,翻译图灵测试的大多数参与者都很难将CUBBITT翻译
本文主要是介绍了语音中最常见的数据集(包含各个语种),及其格式等。
