登录社区云,与社区用户共同成长
邀请您加入社区
下面给你做一份结构化学习总结(偏工程+原理融合版),把今天关于 GAN → WGAN → Diffusion 的关键认知全部串起来,方便你后续复习和扩展。目标:生成数据 方法:对抗训练 问题:不稳定 + collapse 根因:JS散度。你今天完成了从“会用生成模型”到“理解生成模型为什么这样设计”的关键跃迁。Diffusion的成功,本质是: 把“生成问题”转化成“去噪回归问题”检测模型 → 表
第二届化学工程与生物科学国际学术会议(CEBS 2026)将于2026年7月10-12日在中国大理召开。本次大会旨在汇聚全球顶尖科学家、工程师及行业专家,共同探讨化学工程与生物科学领域的最新进展与未来趋势。随着科技的飞速发展,化学工程和生物科学在医疗、能源、环境和材料科学等领域的应用日益广泛,并在推动可持续发展中发挥着关键作用。
本文探讨了生成对抗网络(GAN)在工业界的核心应用,重点分析了超分辨率、人脸合成与数据增强三大领域。文章首先梳理了超分辨率技术的发展历程,从传统插值方法到基于GAN的SRGAN、ESRGAN和Real-ESRGAN,并介绍了感知损失函数如何解决传统MSE损失导致的模糊问题。在人脸合成方面,文章讨论了DeepFake技术原理及其检测方法。此外,还展示了GAN在医疗影像增强和数据稀缺场景中的应用价值。
2025年生成式AI与数字媒体艺术国际学术会议 (GAIDMA 2025)将于2025年08月29-31日在中国-赣州召开。近年来,生成式人工智能技术(Generative AI)在艺术创作、影视制作、游戏设计等多个数字媒体艺术领域展现出巨大的潜力与影响力。从生成对抗网络(GAN)到人工智能驱动的音乐和图像创作工具,这些技术不仅推动了艺术创作的新形式,也重新定义了创意产业的生产流程。随着技术的不断
这位某安朋友应该还没入门,基本的webtop10(owasp)漏洞如何检测还没掌握,虽然现在有现成工具来进行web漏洞检测,但是原理咱们还是要知道,因为后期咱们实战中遇到大部分都带waf,waf就算了关键waf还带着自主学习的功能,之前就遇好几家带人工智能的waf防火墙哈哈哈。代码原理咱们理解以后聊聊这几个漏洞,xss分三大类,反射,存储dom(其他扩展flask,pdf,uxss),怎么判断xs
在当今数字化时代,用户对应用程序的体验要求越来越高。他们渴望看到独特、个性化且引人入胜的内容。传统的内容生成方式,如基于规则或预定义模板的方法,已难以满足用户日益增长的多样化需求。生成对抗网络(GAN)的出现,为解决这一问题带来了新的曙光。GAN是一种强大的深度学习模型,自2014年由伊恩·古德费洛(Ian Goodfellow)等人提出以来,在图像生成、语音合成、数据增强等众多领域取得了令人瞩目
使用魔珐星云参数流API,2小时搭建教育培训AI数字人视频生成平台。该平台支持纯文本输入,自动转换SSML,约500ms响应,3分钟生成1分半视频,低成本、可规模化。作为**具身交互智能**的重要应用场景,Digital human video generation technology provides a brand-new content production method for the
# AI与人类创造力:协同进化中的无限可能人工智能(AI)作为一种新兴的技术力量正在迅速改变世界,它不仅在生产和服务领域表现出强大能力,也在传统上被认为专属于人类的领域——创造力方面展现出惊人潜力。在AI与人类协同创作的过程中,人类负责提供方向、情感和意义,而AI则承担繁重的执行任务,两者形成互补。未来展望:重新定义创造力随着AI技术的不断进步,人类与AI的创造性合作将更加深入。未来的创造力可能不
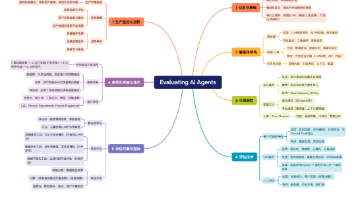
吴恩达《Evaluating AI Agents》课程系统介绍了AI智能体评估方法论。课程从智能体架构(路由器、技能、内存)入手,强调通过OpenTelemetry和Arize Phoenix实现运行可观测性。核心提出三种评估技术:代码评估(确定性高)、LLM裁判(灵活性好)和人工标注(准确性优),并演示如何评估路由器决策、技能输出和执行路径效率。课程创新性地提出"评估驱动开发"
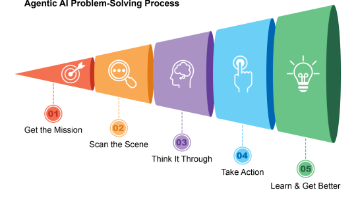
AI智能体的演进与未来展望 AI智能体正从简单的语言模型发展为能感知环境、规划行动并自我学习的复杂系统。其发展经历了四个阶段:基础LLM、工具增强型、战略规划型,直至当前协同工作的多智能体系统。未来五大趋势包括:1)全能型通才智能体的出现;2)深度个性化服务;3)具身化与物理世界交互;4)智能体驱动的新经济模式;5)目标导向的自适应多智能体系统。这些发展将重塑工作方式和经济结构,预计到2034年市
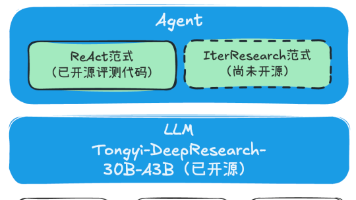
阿里开源的通义DeepResearch-30B模型在深度研究任务评测中表现优异,超越现有开源/闭源方案。该30B MoE模型(每次激活3B)专为研究任务优化,支持128K上下文和两种Agent范式:ReAct和独创的IterResearch(支持多Agent并行探索)。本文详解了模型部署方案(本地/vLLM/API调用)及基于LangGraph的ReAct Agent实现,包括工具调用流程和提示词
多智能体AI系统正变革企业销售配置流程。这种基于大语言模型的Multi-Agent系统由8个专业AI智能体组成,能像真人团队一样分工协作,将复杂配置流程从数天缩短至几分钟。系统包含交互层、智能协作层、知识库和执行引擎四大模块,实现从需求理解到方案输出的全自动闭环。该方案显著提升了销售精准度、响应速度和可靠性,使企业销售从经验驱动转向策略驱动。随着AI能力扩展,这类系统有望从销售助手升级为企业决策大
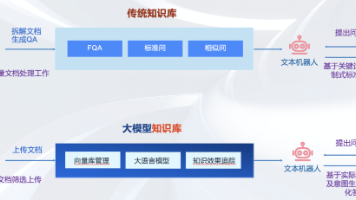
智能问答系统中,知识库构建是RAG(检索增强生成)技术的核心基础。知识库质量直接决定了系统能力上限,其构建是一项需要深刻理解业务的定制化工程。不同行业的知识体系、数据形态和应用场景差异显著,使得知识库难以通用化,必须结合业务特点采用混合存储方案和精细化管理。构建卓越知识库需要系统性地开展需求分析、技术选型、数据处理和持续优化,这需要深度融合业务洞察与工程技术。在当前AI大模型技术快速发展的背景下,
提示工程十年演进(2015-2025) 从早期GPT的"前缀玄学"到GPT-3的思维链突破,再到2025年自动推理与内核级语义安全,提示工程经历了三大范式跃迁: 结构化指令期(2015-2018):依赖文本前缀的零样本探索 思维链革命期(2019-2022):Few-shot提示和CoT技术突破逻辑推理瓶颈 自主进化期(2025):DSPy程序化优化、eBPF内核级语义审计实现
生成对抗网络(GAN)和风格迁移技术正在重塑设计领域,使非专业人士也能快速创建高质量视觉内容。这些AI设计工具通过分析海量标注数据,自动生成符合色彩心理学和行业特性的Logo方案。在品牌标识设计中,关键技术价值体现在快速原型生成、风格匹配和负空间优化等方面。实测表明,合理使用AI工具可使设计效率提升6-8倍,同时降低80%的VI系统开发成本。针对初创团队和中小企业,AI辅助设计特别适合快速验证品牌
本文介绍了Ai创想实验室平台如何在中小学AI教育中实现GAN模型教学。以AnimeFaces数据集(64×64彩色图像)为例,详细说明了生成器模型参数设计过程:从100维噪声输入,通过全连接层(16384神经元)、Reshape层(8×8×256)到最终输出64×64×3图像的完整计算逻辑。使用800个样本在普通硬件上训练,10轮后即可生成基本成型的动漫头像。该平台无需编程基础、专用硬件或云端算力
【代码】【GAN】pix2pix算法的数据集制作。
生成对抗网络(GAN)是一种创新的深度学习架构,由生成器和判别器两个核心部分组成。生成器负责生成看似真实的数据,试图欺骗判别器;判别器则努力区分真实数据和生成器生成的数据。两者在不断的对抗训练中逐渐优化自身能力。GAN 在多个领域展现出强大的应用潜力,如生成逼真的图像、实现图像到图像的转换、用于数据增强、语音合成、自然语言处理等。然而,GAN 的训练过程存在不稳定、模式崩溃等挑战,需要不断改进和优
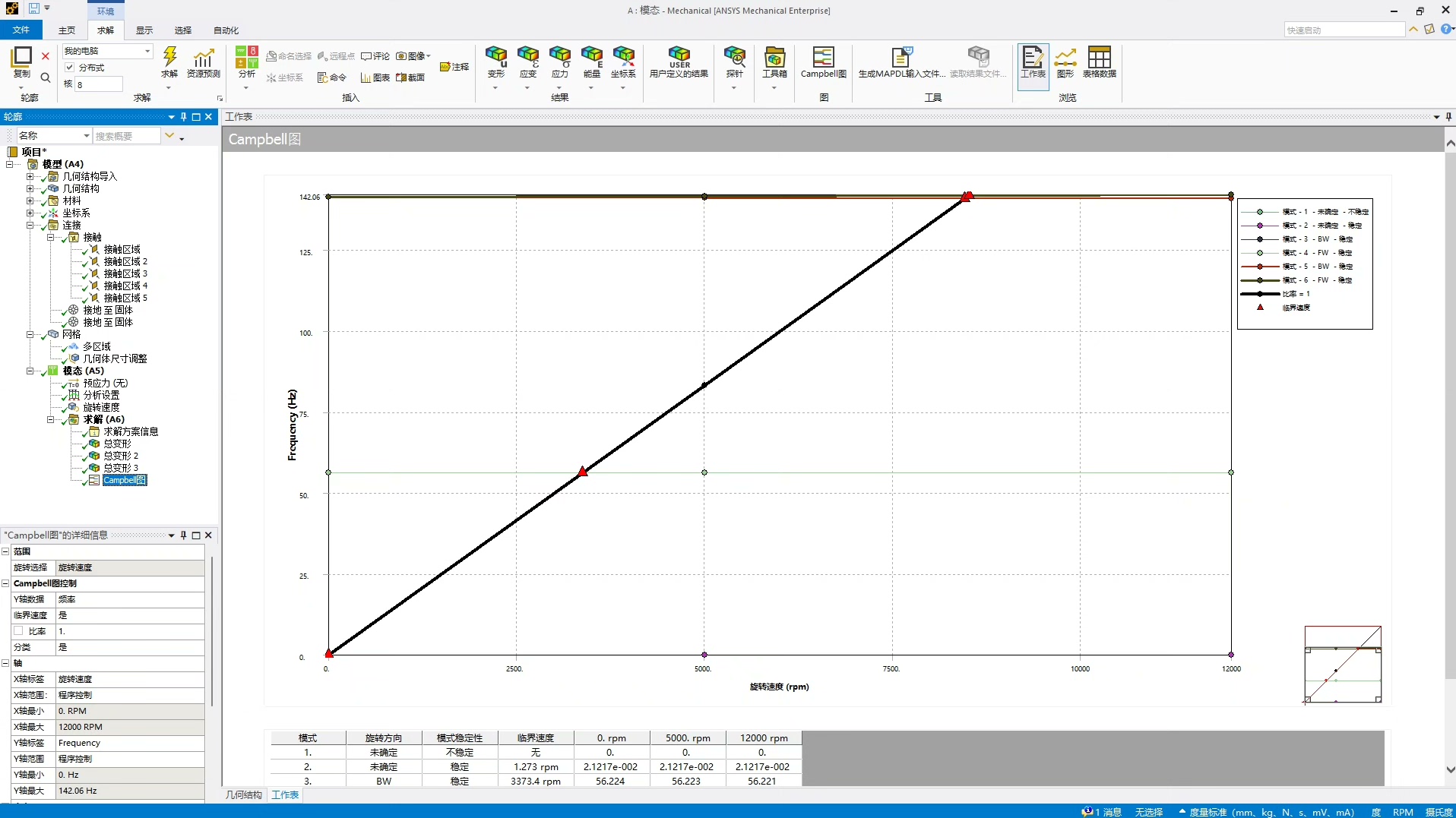
在Workbench后处理里点几下生成这个神器,你会看到三条妖娆的曲线:蓝色的是固有频率随转速变化,红色的是1倍频线,绿色的是2倍频线。在工厂里那台嗡嗡作响的鼓风机又双叒叕出问题了,轴承温度异常升高时老师傅叼着烟说了句:"这转子怕是遇上临界转速了"。就像相亲照和真人差距太大,模型和实物之间,永远隔着一条叫"简化假设"的鸿沟啊。这时候要特别注意第三阶模态,它的频率线刚好在3000转时和1倍频线亲密接
生成对抗网络
——生成对抗网络
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区



 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 DAMO开发者矩阵
DAMO开发者矩阵