登录社区云,与社区用户共同成长
邀请您加入社区
使用预训练模型学习判断imdb评论正负面模型本节的模型与上节见过的那个类似:将句子嵌入到向量序列中,然后将其展平,最后在上面训练一个 Dense 层。但此处将使用预训练的词嵌入。此外,我们将从头开始,先下载IMDB 原始文本数据,而不是使用 Keras 内置的已经预先分词的 IMDB 数据。首先,在 http://mng.bz/0tIo ,下载原始IMDB数据集并解压。文件夹的结构如下:a...
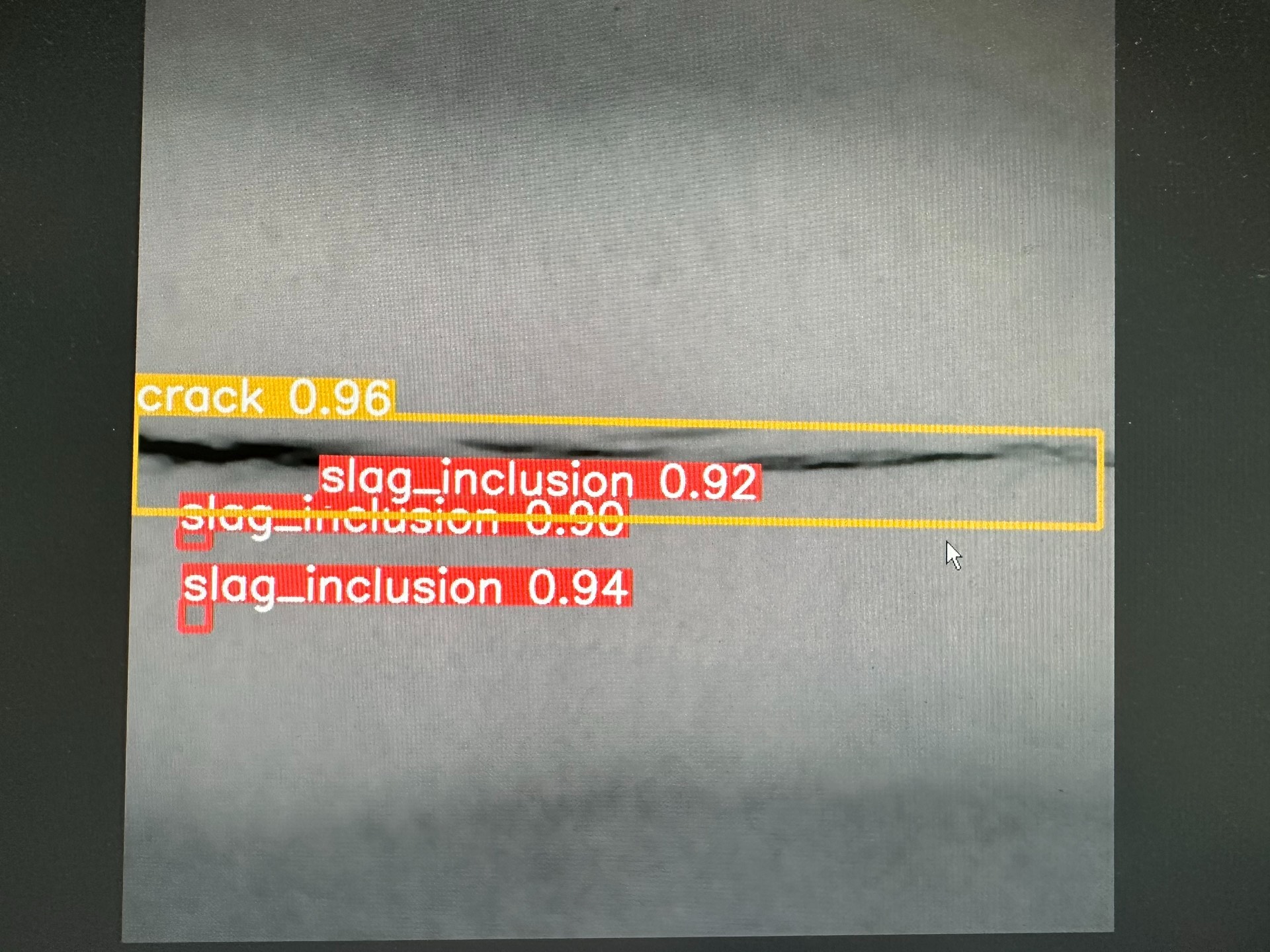
最后在YOLOv5上跑出的效果:mAP@0.5达到87.4%,但实际部署时发现对密集气孔的误检率偏高。最近折腾了个X射线底片数据集,5232张带VOC格式标注,包含裂纹、气孔、夹渣、未融合四类缺陷。构建的焊缝缺陷目标检测数据集,扩增5232张,缺陷标注4类,裂纹 气孔 夹渣 未融合/未焊透,VOC格式,处理…注意边缘区域的缺陷要复制扩充,避免被截断。这套组合技重点保留缺陷区域特征,在保持标注框有效
深度学习之tf.keras.preprocessing.image_dataset_from_directory()函数
YOLO3目标检测实现目标为识别空教室人数以及教室占用状态,计算教室置空率DEMO测试YOLO提供了模型以及源码,首先使用YOLO训练好的权重文件进行快速测试,首先下载权重文件https://pjreddie.com/media/files/yolov3.weights将yolo3的版本库clone到本地,本次测试的commit id为e6598d1git clone git@git...
kerasCV为语义分割提供了便利的解决方案。语义分割旨在给图像每个像素分配语义标签,如道路、建筑等。使用kerasCV,用户可以轻松构建和训练基于卷积神经网络的语义分割模型。支持多种数据集如COCO、PASCAL VOC和Cityscapes,并允许使用自定义数据集进行微调。此外,kerasCV还提供了图像生成和增强功能,以提高模型的泛化能力。总之,kerasCV为语义分割任务提供了高效且易用的
深度学习环境搭建:Win10+TensorFlow2.7+CUDA11.2+cuDNN8.1.1
一. 数据集方面1. 关于深度学习数据集的介绍可以参见此博客Tensorflow知识点总结(一)_竹叶青lvye的博客-CSDN博客2.mnist数据集获取的三种方式见博客Tensorflow知识点总结(二)_竹叶青lvye的博客-CSDN博客3.对于一些深度学习框架,已经包含了常用的数据集,如下博客的最后有相关代码获取Ubuntu配置TensorRT及验证_竹叶青lvye的博客-CSDN博客获取
深度卷积神经网络导语:之前在MLP做数字识别时,我们将图片压扁成为一个一维向量,损失了原本的空间特性。那么,直接对图像进行处理,也就会得到一个巨大的矩阵,若给矩阵中的每个值都配一个权重,那么计算上会是相当复杂的。我们人在看图时有些地方是投机取巧的,我们不需要看到整张图片就可以一定程度上猜到这是什么,所以我们可以将图片分割,分块来处理(局部感受野)。既然图片模块化了,那么每块的权重也可以批量处理..
基于keras框架的MobileNetV3深度学习神经网络花卉/花朵分类识别系统源码
keras
——keras
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵