登录社区云,与社区用户共同成长
邀请您加入社区
7月17日,2026世界人工智能大会 (WAIC) 主论坛正式揭晓了大会最高荣誉——卓越人工智能引领者奖(Super AI Leader,简称SAIL大奖),昇腾950超节点(Atlas 950 SuperPoD)凭借系统架构创新和突破,从众多海内外参评项目中脱颖而出,荣获SAIL大奖。
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
二者并非 “高低配” 的关系,而是完全不同赛道的产品:Jetson 是面向边缘端的异构嵌入式计算平台,算力价值体现在 “低功耗下的实时推理与外设整合”;NVIDIA 桌面显卡是面向桌面 / 数据中心的通用高性能计算设备,算力价值体现在 “高吞吐的训练与批量处理”。脱离场景单纯对比 TOPS 数值,没有实际参考意义。
看到这里,估计大家都明白了:GitCode Notebook 本质上是华为版的 Google Colab,是华为为了推广昇腾 NPU 生态而投入的免费算力资源。写本文的时候,个人额度还有 1000 核时/月。如果选 4 核 CPU 配置,相当于每月 250 小时——考虑到一天只有 24 小时——这个额度对个人开发者来说绝对是够够的了。当然,免费资源也有它的局限:单次 2 小时、单卡、阉割版显存、临
如果AI持续指数级耗电,双碳目标还有解吗?当大模型参数从十亿级跃升至万亿级,AI训练算力每数月翻倍、单机柜功耗突破百千瓦,一场由人工智能掀起的电力消耗风暴正在席卷全球能源体系。国际能源署数据显示,2024年全球数据中心耗电415太瓦时,占全球总用电量1.5%;基准情景预测2030年总量将翻倍至945太瓦时,其中AI专属算力耗电将较2025年增长3倍,占全部数据中心用电超53%。
注册地址-https://cloud.siliconflow.cn/i/plR5LXnz。
韩国政府联合国内顶尖科技巨头宣布:将狂砸 1万亿美元(约合超过7万亿人民币),启动一系列国家级超级旗舰项目。他们的终极野心很明确:在2028年前,彻底确立韩国在“物理人工智能(Physical AI)”领域的全球霸主地位,并全面实现商用人形机器人的社会化部署。
6月11日美东时段,美国商务部下达出口管制行政指令,限制外籍用户及境外主体使用两款全新旗舰模型;6月12日,Anthropic官宣两款模型全球全域停服。
中国以国产算力集群筑牢自主根基,以 AI 安全测试完善治理体系,海外以技术创新领跑安全对抗,双方路线分化、竞争加剧,也将共同推动 AI 产业向更安全、更自主、更可控的方向发展。,曾自主发现 Linux 内核、Firefox 浏览器等数千个高危零日漏洞,其中包含 27 年未被发现的隐蔽漏洞,在 SWE-bench、CyberGym 等测试中碾压主流大模型。:专注 AI 训练与推理,实现通用算力与智能
你负责提出目标,Kerminal 和你一起交付。
大模型的爆发式发展正将算力推至数字经济的核心战略地位。GPT-4o与DeepSeek-R1等模型的多模态突破,不仅标志着AI进入"参数爆炸"时代(GPT-4单次训练需2.15×10^25 FLOPs,等同3万台A100全年运转),更暴露出算力供需的尖锐矛盾——据智源研究院的报告预估国内大模型训练算力缺口已达109EFLOPS(约20个太湖之光年产能)。在新技术广泛应用和全球算力短缺的背景下,信创国
云计算计费单位解析 云计算服务采用多样化的计费单位:1)通用计算以vCPU-hour和内存(GiB/GB)为主,Kubernetes使用millicores配额;2)加速器按GPU/TPU核心时长计费,算力单位含FLOPS/TOPS;3)Serverless服务采用GB-second等内存时长组合;4)大数据服务多定义专属单位(如slot-hour、DBU-hour);5)网络存储关注带宽/IOP
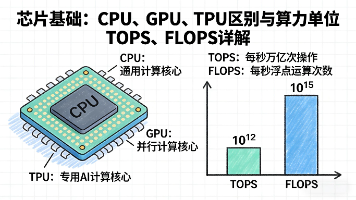
CPU、GPU 和 TPU 都是处理器,但它们的设计目标和擅长的任务截然不同,可以将它们理解为不同类型的员工。
2026年,DeepSeek以500亿融资和4000亿估值引发AI行业震动,宣布全员翻倍扩招,标志着AI从实验室研究转向工业化落地的关键转折。其战略目标是构建覆盖算力、基础模型和行业应用的AI全产业链生态。资金将重点投入人才梯队建设(分核心科学家、工程骨干、行业专家三级)、算力扩张和数据争夺。这一举措将重塑人才市场:虹吸顶尖人才、倒逼巨头跟进、优化薪资结构。文章以管仲"轻重之术"
企业控制 AI 支出的关键,在于利用 FinOps(云财务运营)的思想,消除技术、财务与管理层之间的信息壁垒。通过智能化的算力追踪、大小模型的高效混搭、以及在团队内部培养精细化的 Token 节约文化,企业才能在享受 AI 带来生产力狂飙的同时,牢牢守住财务底线。
本文介绍了如何为本地大模型工具Ollama安装OpenWebUI网页界面,提升使用体验。主要内容包括:OpenWebUI的作用(提供类似ChatGPT的网页交互界面)、安装前的准备工作、使用Docker安装OpenWebUI的具体步骤、常见问题解决方法以及OpenWebUI与自建网页的对比。通过OpenWebUI,用户可以获得更直观的聊天界面、更方便的模型切换和对话管理功能,使本地大模型的使用更接
上集讲到翠花想本地部署AI大模型,结果被我泼了冷水——他的电脑跑不动。临走时他问了一个问题:"那7B、13B、70B到底是什么意思?为什么数字越大越厉害?"这个问题问到了点子上,今天专门讲。
显存(VRAM)和算力(TFLOPS)是GPU的两个正交物理指标:显存决定模型能否加载运行,算力影响推理响应速度。理解二者差异是本地部署大模型的前提——显存不足导致CUDA OOM崩溃,而算力瓶颈仅表现为延迟升高。真实场景中,‘显存不够’常被误判为‘算力不足’,尤其在Windows系统下,硬件加速、WSL2 GPU支持等隐性占用可吞噬1.5GB以上显存;同时,未启用torch.compile、未优
在人工智能领域,算力是驱动模型推理的核心资源,其消耗直接决定了AIGC应用的运营成本。算力通常以FLOPS衡量,而模型推理则是将训练好的模型用于处理用户请求的过程,这涉及到吞吐量、延迟和Token处理等关键性能指标。理解这些原理对于评估技术价值和进行工程实践至关重要,尤其是在构建高并发、低延迟的在线服务时。通过量化、模型压缩和动态批处理等技术,可以显著优化推理效率,从而降低对昂贵GPU资源的依赖。
本文以Windows系统为例,详细介绍了Ollama本地大语言模型的安装和使用流程。主要内容包括:系统硬件要求(建议Win10/11、16GB内存)、两种安装方式(安装包/PowerShell命令)、基础命令操作(运行/下载/删除模型等),并推荐了适合新手的轻量级模型(llama3.2、qwen2.5等)。文章特别提醒初学者从小模型入手,避免直接下载大模型导致的性能问题,同时提供了判断本地运行的验
本文探讨 AMD ROCm 作为 AI 底座的优势,强调开放生态打破算力垄断。通过硬件兼容性、成本控制及社区活力,ROCm 提供多元韧性选择,助力开发者构建可持续 AI 基础设施。
站在2026年回看AI的普及进程,最有趣的事情不是AI有多厉害,而是大多数人根本不知道AI发生了什么。82亿人里有65亿从没用过AI。10亿月活用户的ChatGPT,深度使用者不过几百万。中国AI渗透率53%——但如果你去二线以下城市问问"用AI做什么",绝大多数人的答案是"聊天呗"。AI的冰山,露在水面的尖顶已经被媒体炒成了珠穆朗玛峰。水面之下的基座,深得看不到底。GPU、HBM、先进封装、AI
200万Token听起来像是一个遥不可及的数字,但它已经在Gemini 1.5 Pro、GPT-6(Spud)等模型中成为现实。对于开发者而言,这意味着可以设计出此前根本无法想象的应用:让AI管理整个代码仓库、担任私人律师阅读全部合同、作为学习伙伴通读整个学期的教材……限制我们的将不再是上下文长度,而是想象力。下一步,请思考:如果你的AI助手拥有你过去十年所有的聊天记录、邮件和文档,你会让它帮你做
算力
——算力
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台


 DAMO开发者矩阵
DAMO开发者矩阵

 AMD开发者中国社区
AMD开发者中国社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI Agent技术社区
AI Agent技术社区









 DeepSeek技术社区
DeepSeek技术社区


 AtomGit AI 社区
AtomGit AI 社区

 脑启社区
脑启社区



 AI编程社区
AI编程社区
