登录社区云,与社区用户共同成长
邀请您加入社区
这是AI Insight系列的第一篇文章,但其实关于AI日报与每日论文精读我已经做了一个月,因为这个领域每日的新进展过于迅速,很多idea不及时记录或留存就会被带过去,所以特此开这个专栏记录笔记与一些个人思考,问题清单会在文末放出,若是有对这些方面感兴趣的大佬欢迎随时交流 yunzennz@gmail.com
摘要: PyCharm配置Python环境时可能遇到“Not Python at”错误或无法导入conda环境的问题。前者通常因虚拟环境的pyvenv.cfg文件指向的解释器路径失效导致,需修改文件内容或替换解释器;后者多由PyCharm与conda版本不兼容或缓存未更新引起,可通过重启PyCharm、更新conda或手动选择解释器路径解决。对于conda环境创建按钮灰色问题,可尝试切换conda
创建一个新环境:conda create -n 【自定义环境名字】 python=3.9。激活新环境:conda activate【环境名字】特此鸣谢我的好同学@重中之重的特级教学,非常之好用。二、创建包含nodejs的conda环境。一、conda环境下载安装。
conda环境配置及IDE(vsCode、PyCharm、Jupyter)开发环境配置
🎯 为什么路径治理至关重要?在传统开发环境中,路径混乱常导致以下问题:系统盘污染、权限冲突、安装失败;默认路径层级过深,易触发 Windows 路径长度限制(260 字符);环境分散在用户目录中,不利于迁移、备份与教学分发。特殊场景下可添加环境变量使用,为覆盖所有使用场景,环境变量路径长度应有预见性地尽量保持精简。因此,建立集中统一、路径简短、可读性强、易记易写的环境路径结构,是治理的基础
是一个开源的和工具用于管理软件包及其依赖关系,并创建隔离的虚拟环境。是一个强大的工具,特别适合需要管理复杂依赖和隔离环境的用户。无论是数据科学、机器学习还是科学计算,Conda 都能提供高效的包和环境管理支持。
只用 Anaconda + PyCharm,打造覆盖全类型 Python 虚拟环境的统一管理体系
配置文件改写:CC Switch 将 Codex 的 live 配置指向 http://127.0.0.1:15721/v1,并强制锁定 wire_api = “responses”,确保 Codex 发出的所有请求均使用 Responses 协议。请求转发与改写:路由拦截 /responses 或 /v1/responses 路径,将其映射为 /chat/completions,同时将 Resp
本文介绍了conda虚拟环境的基本操作:1)查看已有环境(conda env list);2)创建新环境(conda create -n 环境名 python=版本);3)激活/退出环境(conda activate/deactivate);4)安装依赖包(conda install);5)删除环境(conda remove -n 环境名 --all);6)查看环境中的包(conda list)。
摘要:IDEA用户在使用JDK编译Java时出现2-4秒延迟,发现是IDE自动加载Anaconda全局库导致。解决方法是将其复制到项目库并禁用Python代码检查。建议遇到编译变慢时检查外部库列表,避免意外加载的全局环境拖慢效率。该问题揭示了IDE可能存在的"幽灵触手"现象,提醒开发者注意项目配置优化。
python 项目环境管理,conda , pip , conda , poetry , uv , pdm , rye 。。。。。
下面把与最佳实践一次讲清:环境与包管理、通道与配置、导入导出、复现回滚、加速与清理、排错。你可以把这当“conda 作业手册”。
对我来说是一个邪修方法!!!哈哈哈哈哈哈。
或者安装 GPU 版本(如果有NVIDIA显卡)# 安装 PyTorch(CPU版本)# 创建 PyTorch 虚拟环境。
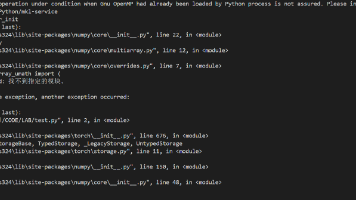
摘要:安装PyTorch时出现numpy导入错误,提示MKL服务包缺失和DLL加载失败。问题源于通过conda安装依赖包导致兼容性问题。解决方法是先用pip卸载相关包,再通过pip重新安装。经验表明,使用conda直接安装容易出现异常,推荐优先使用pip进行包管理。该问题涉及numpy、PyTorch等科学计算包的依赖冲突。
Python 3.13(2024年10月发布)带来多项重大升级:性能方面引入实验性JIT编译器(PEP 744)和无GIL模式(PEP 703),显著提升计算和多线程性能;语法增强包括改进的交互式解释器、扩展的模式匹配和类型提示功能;标准库移除老旧模块并强化安全特性。实验性功能需谨慎评估,但整体标志着Python向高性能计算的重要迈进。建议开发者逐步迁移以体验这些突破性改进,特别是高性能计算和多线
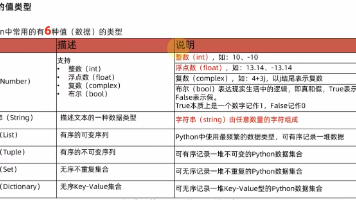
Python异常处理与文件操作摘要 本文全面介绍了Python中的异常处理和文件操作技术。异常处理部分涵盖基础语法、多异常捕获、自定义异常、finally子句和异常堆栈等核心概念,通过try/except/else/finally结构实现程序健壮性。文件操作部分详细讲解文件打开模式、绝对/相对路径、读写方法及with语句的自动资源管理,重点包括read()/write()方法使用和不同模式(r/w
pip 是 Python 最常用的包管理工具,名称来自 “Pip Installs Packages”。它的主要作用是安装、升级、卸载和管理各种第三方库,让开发者能够快速复用社区已有的工具和框架,而不用从零开始编写代码。pip 默认连接的仓库是 PyPI (Python Package Index),这是全球最大的 Python 包生态系统,收录了数十万个开源项目,涵盖了数据分析、人工智能、Web
对于科研人员来说,还是推荐使用conda。尽管其比较笨重,但使用方便,而且也是科研领域的主流解决方案。但对于开发人员来说,强烈建议转向uv这个现代化工具。这是目前Python依赖管理的集大成者。
首先,查看当前所有已创建的 Conda 环境,确认要删除的环境名称:然后找到你要删除的环境名称(
如果问题持续,可能是 Conda 版本与 Python 3.12.3 兼容性问题,可暂时尝试安装稍早版本的 Python(如 3.11)。看起来你的 Conda 在安装 Python 包时遇到了文件损坏的问题。这个关键文件在指定的路径中缺失了。
若现有环境 Python 版本不符,需强制使用 Conda 环境的 Python 路径。通过以上步骤,可确保在 Python 3.10.6 环境中稳定运行 Stable Diffusion WebUI,并实现局域网共享访问。下载 Miniconda 或 Anaconda 并完成安装。同一局域网下的设备可通过主机 IP 地址访问,格式为。: 检查模型文件完整性及存放路径是否符合要求。运行启动脚本后,
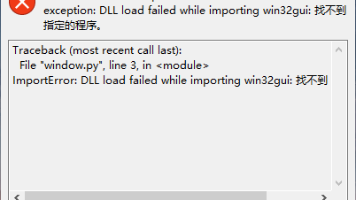
在使用 Anaconda 虚拟环境时,通过 PyInstaller 打包 Python 程序可能会遇到某些导入的库未被正确打包的解决办法。
Token令牌机制是实现接口幂等性的常见方案。SpringBoot中可通过枚举定义状态机,并在Service层添加状态校验逻辑,实现清晰可靠的幂等控制。所谓幂等性,即无论一次或多次调用某个接口,其对系统资源状态产生的影响都是一致的。综上所述,SpringBoot实现接口幂等性的五种主流方案各有适用场景:Token机制适合前置验证,唯一索引简单直接,乐观锁擅长更新操作,状态机契合有状态业务,分布式锁
选择venv还是conda主要取决于项目的需求和个人偏好。venv适合轻量级的 Python 项目,简单易用,安装速度快,资源消耗低。而conda适合数据科学和复杂依赖项目,提供了更强大的包管理功能、更好的环境隔离性和跨平台支持。无论选择哪种工具,都需要注意合理使用虚拟环境,避免在不同项目之间造成依赖冲突。
本文详细介绍了Python开发环境搭建方法,重点讲解VSCode与Anaconda的组合配置。主要内容包括:1)VSCode下载安装步骤;2)Anaconda安装与环境变量配置方法;3)创建和管理Anaconda虚拟环境;4)VSCode与虚拟环境的集成操作;5)常见问题解决方案。文章强调虚拟环境对隔离项目依赖的重要性,并提供了完整的配置流程,帮助开发者快速搭建Python开发环境。建议读者按照步
随着项目数量的增加、依赖库的多样化、操作系统的差异,如何有效地隔离项目环境、安装正确的依赖版本成为了开发者面临的核心问题。Conda 正是在这样的背景下诞生的强大工具,它不仅可以管理 Python 包,还能创建独立的环境,从而帮助开发者轻松切换不同项目环境。而 Anaconda 与 Miniconda 则是基于 Conda 的两个发行版,它们为不同需求的用户提供了不同层级的便利性。本文将系统地介绍
发现conda的pip路径在python路径上面,如果大家显示的路径跟我的不一样可以自己配置,或者在系统变量里的path变量找相应的pip路径剪切到用户变量的path里面。随后三连击确定,重新打开cmd,输入where pip,即可显示python的pip路径在conda之上,问题解决!找到“高级系统设置”并点击。为了更全面、更详细地教大家如何更改pip安装路径,提高安装或卸载python第三方库
简单接受了初次使用python时候,环境怎么安装?怎么管理?conda怎么使用?镜像源有哪些?怎么更换等。快来看看吧
注意事项:这两个命令完成之后,重启电脑。刚进入linux系统找不到AppData文件夹,勾选隐藏的项目。
input默认接收的为字符串。
conda : 无法将“conda”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路 径正确,然后再试一次。1.检查系统cmd是否可执行conda -V 这个命令,一般情况下出现这个问题,系统cmd也无法执行conda指令。(包括 VS Code 中的终端),重新打开一个新的 CMD 窗口(必须新建,否则环境变量不刷新)。6.若仍提示错误,检查步骤
摘要:在Windows PowerShell中执行conda init powershell时遇到脚本禁止运行的错误,可通过修改执行策略解决。使用命令Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser更改策略后,重新执行conda初始化命令即可成功。该问题常见于PyCharm和VSCode等使用系统自带Power
•何时选择 mamba:当你需要频繁创建新环境、安装像 PyTorch、TensorFlow 这样依赖关系复杂的大型科学计算包,或者在自动化流程(如 CI/CD)中希望快速构建测试环境时,mamba 是绝佳选择,能为你节省大量等待时间。另外,对于要求绝对稳定的生产环境,一些保守的建议会倾向于优先使用经过更长时间考验的 conda。mamba 是一款高性能的 Python 包管理和环境管理工具,你可
本文系统介绍了Linux环境下Python开发环境的配置与管理,重点讲解了Conda工具链的使用方法。主要内容包括:1)环境管理工具对比分析,推荐不同场景下的工具组合;2)Conda的安装配置、镜像优化和环境管理全流程;3)虚拟环境实战技巧与依赖管理方案;4)性能优化和项目部署方案。文章还提供了常见问题解决方法、学习路线建议,特别适合数据科学和机器学习开发者参考。
开发阶段:Conda 确保环境隔离性,满足 $\text{Env}打包阶段:PyInstaller 实现 $\text{Code} \to \text{Executable}$ 的自动化转换分发阶段:单文件可执行程序消除环境依赖完整代码示例可在GitHub 仓库获取,实现从开发到分发的全流程自动化。开发阶段:Conda 确保环境隔离性,满足 $\text{Env}打包阶段:PyInstaller
在 Python 开发中,使用 Conda 管理多个环境(如不同 Python 版本或依赖包)能提高项目灵活性。PyCharm 作为强大的 IDE,支持无缝集成 Conda 环境,实现快速切换。整个过程基于 PyCharm 2023.1+ 和 Conda 4.10+ 版本,操作简单可靠。通过以上步骤,您可以在 PyCharm 中高效管理 Conda 环境,提升多项目开发效率。如需进一步帮助,请提供
通过 Conda 安装特定版本包,并结合环境隔离,您可以精准控制 Python 依赖版本,避免“依赖地狱”。始终在新环境中操作。使用=版本号锁定精确版本。利用 YAML 文件实现项目复现。这样,您的开发环境将更稳定可靠。如果您有具体包或版本需求,请提供更多细节,我可以给出针对性示例!
通过以上方法,可同时维护如 Python $3.6$(旧项目兼容)、$3.9$(主流开发)、$3.11$(新特性测试)等多版本环境,实现开发环境的完全隔离与灵活切换。在数据科学和开发工作中,常需同时管理不同 Python 版本的项目。:为每个项目创建独立环境,在。在终端执行以下命令,替换。中记录环境配置,使用。
生产环境务必使用新环境方案,避免依赖链断裂。升级后需全面测试业务代码兼容性。在 Conda 环境中直接升级 Python 存在依赖冲突风险。
Conda-forge 是一个社区驱动的软件包分发平台,提供超过20,000 个开源软件包,专注于 Python 生态系统的扩展。包更新更快:相比官方 Anaconda 仓库,新版本包通常提前 1-2 周发布覆盖更广:包含小众库(如geopandas)和特定领域工具(如生物信息学包biopython跨平台支持:支持 Windows/macOS/Linux 及 ARM 架构。
注:最新适配信息请参考。
选择参数量大、精度高的模型作为教师(如BERT、ResNet152),需确保其在目标任务上表现优异。通过上述流程,可系统化构建高效轻量模型,平衡性能与资源消耗。实际应用中需根据任务需求调整蒸馏强度和模型结构。知识蒸馏通过迁移教师模型(复杂、高精度)的知识到学生模型(轻量、高效)中实现模型压缩。
conda
——conda
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区


 AI Agent技术社区
AI Agent技术社区








 AI硬件创业社区
AI硬件创业社区






 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区