登录社区云,与社区用户共同成长
邀请您加入社区
在 AMD Instinct GPU 上部署多租户模型服务时,K8s 默认的进程级隔离会出现显存竞争与计算抢占问题。本文通过实测 ROCm 5.6 环境下的隔离方案,揭示 PCIe 通道竞争、缓存污染等边界条件,给出包含内核参数调优、硬件校验在内的加固清单,并通过性能对比表展示不同虚拟化方案的取舍,帮助 AI 工程团队控制故障爆炸半径。
只要你开启了 GPU 加速器(比如选择了 P100 或 T4x2),无论 GPU 利用率是 100% 还是 0%(空转),只要 Notebook 处于运行状态,时间就会一直扣除。,其中Header Editor下载&安装地址:https://he.firefoxcn.net/guide/install-full-version.html。2、手机验证: 验证时,国内输入手机号码验证界面无反应,如下
5月18日,摩尔线程在北京举办主题为“词元时代,万物智能”的年度产品发布会,全方位展示了其作为智算底座的战略纵深,全面展示了“云-边-端”全栈智算矩阵:从万卡级规模的夸娥智算集群,到自研“长江”SoC驱动的智能终端MTT AICUBE和MTT AIBOOK;从数字世界智能体“小麦”,到加速物理AI落地的首个全栈具身智能仿真平台MT Lambda,再到持续进化的MUSA生态。
本文探讨了AI浪潮下智算中心面临的算力调度管理挑战,提出了"智算调度10维评估模型"作为选型参考。文章从算力调度平台的定义出发,分析了其核心功能包括资源池化、任务调度、计量计费等,并对比了企业级平台与轻量方案的适用场景。重点解答了6个常见选型问题,强调平台需适配国产芯片、支持模型网关和数据治理等能力。最后指出,有效的算力调度需要兼顾硬件异构性与业务需求,通过多维度评估才能确保智
本文详细解析了PyTorch训练中常见的‘indices should be on the same device’报错,帮助开发者快速定位并修复GPU/CPU设备不匹配问题。通过三步诊断法和多种设备同步策略,确保张量操作的一致性,提升训练效率。文章还提供了防御性编程和高级调试技巧,适用于各种复杂场景。
本文详细介绍了如何开发一个生产级的PyTorch模型性能评估工具,重点解决GPU测量失真、warmup机制和batch size调整等核心问题。通过科学的FPS测量方法,帮助开发者在模型部署前精准评估推理效率,优化GPU和CPU资源利用,提升工业级应用的性能表现。
本文详细介绍了PyTorch模型推理时间测量的专业方法,揭示了为什么简单的`time.time()`在GPU上不准确,并提供了使用`torch.cuda.synchronize()`和`time.perf_counter()`的正确实践。文章还强调了`model.eval()`和`torch.no_grad()`对性能的影响,并提供了完整的测量工具函数,帮助开发者准确评估模型在GPU和CPU上的推
本文提供PyTorch/TensorFlow多GPU环境变量设置的保姆级教程,解决深度学习开发中GPU资源冲突问题。通过环境变量CUDA_VISIBLE_DEVICES和框架级控制方法,实现GPU资源的精准管控,提升团队协作效率和计算资源利用率。
本文详细解析了PyTorch GPU安装过程中常见的CUDA版本冲突及‘torch.cuda.is_available()‘返回False的问题,提供了从系统级诊断到驱动优化的完整解决方案。涵盖硬件验证、版本兼容性分析、安装方案优化及系统级疑难杂症处理,帮助开发者高效解决GPU加速失效问题。
模型部署的成本是可预见的,也是可控的。如果只是做实验跑demo,一张消费级显卡就够了,几千块钱的事。如果是线上服务,月活不高的场景,一个月一两万也能搞定。真正烧钱的是那些日活几十万、又用大模型的场景——那种情况确实花钱如流水。别先买卡。先租三个月的云GPU或者算力租赁,跑一段时间,拿到真实数据后再决定要不要买硬件。这样可以避免最惨的情况——花了几十万买卡,发现业务没起来,卡在机房吃灰。这是从业者的
本文详细解析了N卡GPU过热保护导致的训练中断问题(Error 79),提供了从实时监控到散热优化的全套解决方案。通过自动化监控系统、散热材料升级和环境温度控制,有效预防GPU过热,保障深度学习训练的稳定性。特别适合面临GPU温度过高问题的开发者和研究人员。
本文详细介绍了如何利用Kaggle Notebook高效管理深度学习实验,包括版本控制、日志归档和实验可视化对比等实用技巧。通过自动化输出归档系统和环境快照保存,显著提升实验复现性和管理效率,特别适合在GPU资源有限的场景下优化研究流程。
本文深入分析了PyTorch Dataloader在数据加载过程中的3个隐藏性能瓶颈,包括重复的transform计算、零散的GPU数据传输和低效的内存访问模式,并提供了针对性的优化技巧。通过预处理前置、预加载和内存布局优化等方法,实测CIFAR10数据集上的训练速度提升7.2倍,GPU利用率提高31%。文章附有完整代码实现,帮助开发者彻底解决数据加载拖慢训练的问题。
本文深入探讨了PyTorch Dataloader性能调优的关键技巧,包括pin_memory、num_workers参数配置和自定义Dataset优化。通过实测数据和代码示例,揭示了如何避免常见性能陷阱,提升GPU利用率,加速模型训练过程。特别针对数据预加载、智能预处理流水线和存储格式选择提供了实用解决方案。
本文深入探讨了PyTorch训练中Dataloader性能优化的进阶策略,从基础参数调整到数据预处理流水线重构,再到极端优化方案如GPU预加载和共享内存技术。通过系统化的方法,帮助开发者突破数据读取瓶颈,显著提升GPU利用率,实现训练加速。
本文详细解析了NVIDIA 536.40驱动中的显存扩展技术,通过将系统内存作为显存补充,有效解决PyTorch/TensorFlow等框架的显存不足问题。文章涵盖技术原理、环境配置、性能优化及适用场景,为开发者提供实用指南,特别适合调试阶段和紧急任务处理。
本文深入分析了大模型训练中的通信开销问题,通过实测数据对比了A100/H100与RTX 4090在分布式训练中的性能差异。研究发现,通信带宽和延迟是影响训练效率的关键因素,特别是在数据并行、流水线并行和张量并行等策略中。NVLink技术显著提升了GPU间通信效率,而消费级显卡的PCIe瓶颈导致通信税高达96%。文章还提供了硬件选型建议和通信优化技术,帮助开发者降低训练成本。
本文探讨了使用共享内存技术为GPU显存扩容的可行性,特别是在本地调试Stable Diffusion等大模型时的实际效果。通过详细的性能测试和场景分析,揭示了共享内存技术在显存不足时的应急价值与性能折衷,并提供了优化配置和避坑指南,帮助开发者在速度与显存之间找到平衡点。
当你在电影院观看某电影,被某个宏大逼真的光影特效震撼时,这个就是图形渲染(Rendering)。图形渲染:就是把三维世界,变成你屏幕上看到的二维图像。图形渲染的核心逻辑是:(1)世界由点、线、三角形 构成(2)屏幕由像素构成(3)渲染的任务就是:计算每个像素该显示什么颜色为了让屏幕上的3D模型拥有真实感,计算机需要精确模拟每一束光线的传播、反射与折射,并计算出屏幕上数以百万计像素点的颜色。
AI模型工程化落地的核心在于打通训练、推理与部署的端到端闭环。其底层依赖GPU加速能力,涉及CUDA环境兼容性、混合精度计算原理、ONNX模型跨框架泛化机制等关键技术;技术价值体现在显著提升推理吞吐、降低服务延迟并保障生产稳定性;典型应用场景包括计算机视觉模型(如YOLO)在边缘设备或云服务器上的低延迟API服务、医学影像实时分析系统及工业质检流水线。本文聚焦GPU环境下从PyTorch训练到ON
本文档详细介绍了在UOS V25服务器操作系统上安装和配置沐曦C500 AI加速卡的完整流程。主要内容包括:环境准备(系统要求、硬件兼容性检查)、驱动安装(权限配置、DKMS支持)、固件升级(风险提示、操作步骤)、SDK开发环境部署(解压安装、环境变量配置)以及验证测试方法(驱动模块检查、工具链验证)。文档提供了不同硬件架构(x86/aarch64)的差异化操作指南,并包含关键步骤的预期输出示例,
AI大模型的训练与推理对算力需求呈现指数级增长,如何高效利用GPU、FPGA等异构计算资源成为关键。本文从算力需求评估、成本优化策略到典型场景技术方案,深入解析AI大模型算力选型的核心要点。通过对比阿里云神龙架构、腾讯云星星海服务器等主流算力供应商的技术特点,结合燧原科技邃思2.0芯片等专业算力服务商的技术突破,为开发者提供从理论到实践的完整算力选型指南。特别是在百亿参数模型训练、高并发推理服务等
本文通过PyTorch实测分析了GPU与CPU在深度学习中的计算开销,重点量化了数据搬运成本。实验从张量尺寸、计算复杂度和PCIe带宽三个维度展开,揭示了小张量场景下GPU加速效果被抵消的现象,并提供了批量处理、内存管理等优化策略,帮助开发者更高效地利用硬件资源。
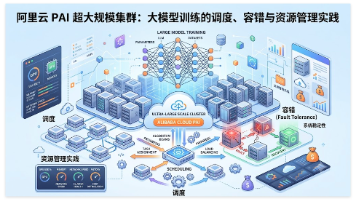
阿里云PAI平台分享了大模型云上训练的工程实践,重点解决超大规模集群下的调度与容错挑战。面对大模型训练长周期、高故障率的特点,PAI构建了三层防护体系:事前30-50项指标检查(1分钟完成)、事中AImaster实时容错(分钟级恢复)、事后EasyCKPT异步快照(分钟级重启)。通过Serverless架构、拓扑感知调度和QuotaTree资源管理,实现了90%以上的资源利用率,支持万卡级训练。
本文详细介绍了YOLOv8在大图切图训练中的实战方案,通过640x640窗口和0.2重叠率策略,显著提升小目标检测的召回率15%。文章深入解析了切图算法的工程实现细节,包括滑动窗口计算、标签映射和多线程加速,并提供了完整的YOLOv8训练配置和推理阶段的拼图策略,帮助开发者在保持GPU显存效率的同时优化目标检测性能。
本文深入分析了PyTorch/CUDA 11.8在异常退出后显存释放的四种进程终止方式,包括正常退出、SIGINT信号、SIGTERM信号和SIGKILL信号。通过对比实验和详细的技术解析,提供了显存管理的最佳实践和自动化解决方案,帮助开发者有效解决显存残留问题,提升GPU资源利用率。
本文深入探讨了PyTorch 2.0中显存泄漏的三大典型场景:梯度未清零、测试模式下的计算图滞留以及中间变量的幽灵持有。通过详细的代码示例和显存对比分析,提供了实用的诊断工具包和优化技巧,帮助开发者有效解决爆显存问题,提升深度学习项目的稳定性和效率。
本文详细介绍了PyTorch 2.1中四种显存优化策略,帮助用户在不升级硬件的情况下将ResNet-50训练的batch size提升2倍。通过混合精度训练、梯度累积、梯度检查点和激活值重计算等技术的组合应用,显著减少显存占用并提升训练效率,特别适合GPU资源有限的环境。
本文深入分析了PyTorch CUDA 12.x在不同尺寸张量计算中的性能拐点,从8x8到4096x4096的实测数据揭示了GPU与CPU的性能对比。通过五个关键拐点的详细解析,帮助开发者优化张量计算策略,提升GPU利用率并避免性能陷阱。
本文详细解析了在Windows 11系统下,RTX 40系显卡配置CUDA 12.4与PyTorch 2.4环境时常见的5个错误及其修复方法。从驱动版本冲突到环境变量配置,再到PyTorch安装陷阱,提供了实用的解决方案,帮助开发者高效搭建深度学习开发环境。
本文通过实测分析PyTorch在CUDA与CPU计算中的性能差异,重点量化了数据搬运成本对计算效率的影响。实验显示,小规模计算时GPU可能因数据搬运开销而慢于CPU,并提供了优化策略如批处理、内存复用等,帮助开发者在实际应用中做出更高效的技术决策。
本文详细介绍了如何配置PyTorch 2.3.1 GPU开发环境,包括CUDA 12.4与cuDNN 9.2.1的安装与兼容性验证。通过3步验证流程确保环境正确配置,帮助开发者快速搭建深度学习开发环境,提升GPU加速计算效率。
本文详细介绍了如何在PyTorch 2.x中仅通过pip安装快速配置GPU支持,特别针对CUDA 12.1环境。通过5分钟验证流程,开发者可以轻松检查GPU加速功能,无需复杂的环境配置。文章还提供了常见问题排查和进阶使用技巧,帮助用户高效利用PyTorch的GPU加速能力。
本文详细对比了PyTorch 2.1.0 GPU环境配置的三种主流方案:Conda全量安装、Pip精简安装和手动完整CUDA Toolkit,并提供了CUDA 12.1的实测性能数据。通过具体步骤和优化建议,帮助开发者根据需求选择最佳配置方案,提升深度学习模型训练效率。
本文对比了三种GPU机器学习加速方案:本地原生CUDA开发、RAPIDS生态工具链(cuDF/cuML)和云端托管环境(Colab Enterprise)。通过实测数据和成本分析,帮助开发者根据项目需求选择最优技术路径,提升机器学习任务的性能和效率。
本文详细介绍了如何在阿里云PAI-DSW平台上配置GPU实例,从MNIST手写数字识别训练到EAS模型部署的全流程实战。涵盖GPU实例创建、数据预处理、模型训练优化、ONNX格式转换以及EAS服务部署等关键步骤,帮助开发者掌握企业级AI应用的开发与部署技巧。
本文详细解析了PyTorch 2.3.1在CUDA 12.1与11.8双版本下的GPU环境配置与兼容性测试。通过硬件检查、驱动兼容矩阵和性能对比,为开发者提供实战建议,帮助优化深度学习项目的GPU加速效率。特别适合使用Anaconda管理环境的PyTorch开发者。
优先选择 AutoDL、润云、晨涧云、矩池云。这类平台上手快、生态完善、成本可控,适配轻量化实验与入门训练。测试环节建议覆盖 GPU 压力测试、IO 吞吐测试、网络带宽测试和 6—12 小时长稳测试,提前排查卡顿、重启与性能漂移问题。与 AutoDL 同期起步,资源池运行稳定,可提供免费存储空间,4090、A100 算力单价相对亲民。北交所上市超算服务商,背靠国家级超算中心,具备工业级网络、电力、
上个月你订了一张机票,票价显示只要。结果最后选个不是中间的座位花了,托运行李花了,为了让行李有地方放、买个优先登机又花了,最后还被加收了一项谁也解释不清的‘航空公司燃油附加费’。原本 283 元的机票,愣是让你掏了。你以为票价全包了,结果全都被拆开来单独算钱。你的 GPU 账单其实也是这么个套路。每小时的单价就像那张廉价机票,而你最终的推理费用之所以比定价页面高出三分之二,全是因为这四个“隐藏加价
本文对比了在AutoDL云服务中使用PyCharm和JupyterLab进行PyTorch 1.13远程训练的效率和适用场景。详细分析了两种环境在配置、调试、交互式实验及GPU资源管理方面的差异,帮助开发者根据项目需求选择最佳工具组合,提升神经网络模型训练效率。
本文深入解析了GPU算力指标TFLOPS与TOPS的演变及其在AI推理与训练中的实际效能。从精度优化(FP32、TF32、INT8)到架构革命(Tensor Core),揭示了如何根据任务需求选择合适算力指标,并提醒警惕厂商参数游戏。文章还探讨了未来趋势,如内存容量、稀疏计算和异构计算的重要性。
本文详细介绍了从零开始配置PyTorch+GPU环境的完整流程,包括显卡驱动检查、CUDA Toolkit安装、PyTorch版本选择及常见问题解决方案。通过保姆级避坑指南,帮助开发者高效搭建深度学习环境,充分利用GPU的并行计算能力提升训练速度。
本文深入探讨了PyTorch训练中num_workers参数对GPU利用率的影响,揭示了数据加载与GPU计算之间的关键平衡。通过实际案例和优化公式,指导开发者如何设置最佳worker数量以提升训练效率,同时介绍了包括预加载策略和混合精度训练在内的全方位优化技巧,帮助实现高达92%的GPU利用率。
GPU
——GPU
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AMD开发者中国社区
AMD开发者中国社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

 AI编程社区
AI编程社区





 AI Agent技术社区
AI Agent技术社区




 智能体开发者社区
智能体开发者社区

 openEuler 社区
openEuler 社区