




- @m0_49711991
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
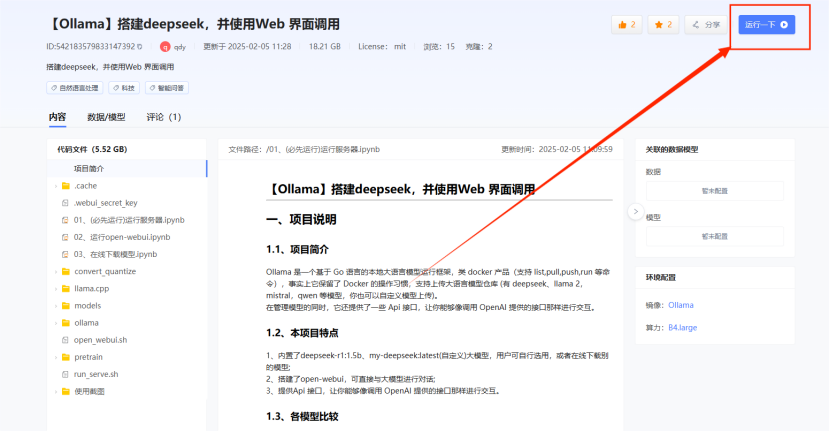
DeepSeek-R1 一经发布引起国际热议,其性能比肩 OpenAI o1 正式版,但是花费却大大减少,并且该模型已经完全开源。目前使用Ollama搭建的deepseek模型1.5b版本已经在趋动云『社区项目』上线,无需自己创建环境、下载模型,一键即可快速部署,快来体验搭建deepseek 带来的精彩体验吧!视频教程:趋动云一键体验爆火模型【deepseek】
DeepSeek-OCR 2 是DeepSeek团队推出的第二代 OCR 模型,通过引入 DeepEncoder V2 架构,实现从固定扫描到语义推理的范式转变。模型采用因果流查询和双流注意力机制,能动态重排视觉 Token,更精准地还原复杂文档的自然阅读逻辑。在OmniDocBench v1.5 评测中,模型综合得分达到 91.09%,较前代提升显著,同时显著降低了 OCR 识别结果的重复率,为
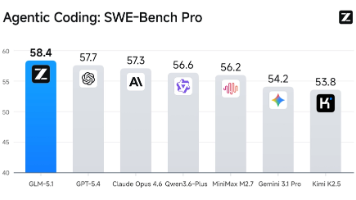
GLM-5.1在权威测试中超越Claude Opus4.6,特别擅长复杂工程任务和自主Agent工作流。通过llama.cpp项目可在各种硬件高效推理,趋动云平台提供一键部署服务,免除环境配置烦恼。新用户可参与限时活动获取150元算力金。该社区项目汇聚全球技术爱好者,支持快速体验AI模型并分享创新成果。
Falcon H1R 7B —— 一款由阿联酋阿布扎比技术与创新研究院(Technology Innovation Institute, TII)研发的纯解码器(decoder-only)大语言模型。该模型在 Falcon-H1 基础模型这一坚实底座之上构建,实现了推理能力的重大飞跃。

OrionX社区版发布:轻量级AI算力池化解决方案助力企业降本增效 摘要:OrionX社区版推出轻量级AI算力资源池化方案,解决企业GPU利用率低、运维复杂等痛点。该方案支持算力与显存独立切分及超分技术,单卡可并行多任务,提升资源利用率300%以上;具备智能调度系统实现资源自动分配回收;提供可视化监控和开放API接口,简化运维并支持二次开发。产品部署简便,兼容主流硬件和CUDA应用,适用于各类规模

AI时代,算力正成为制约中小团队发展的“隐形成本”。调查显示,许多团队面临GPU硬件昂贵、利用率低、管理混乱等问题,导致算力浪费严重。例如,初创公司GPU闲置率达25%,高校实验室因抢卡冲突降低科研效率。 OrionX社区版提出“更聪明的算力调度”方案,通过GPU池化技术(显存超分、vGPU隔离、K8s集成等),让多任务共享物理GPU资源,提升利用率至80%以上。实际案例中,企业节省50%硬件成本

通过支持在 ModelScope 上发布的工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并促进语音识别生态系统的发展。SpeechBrain 是一个基于 PyTorch 的开源、全能的对话人工智能工具包,可用于开发最先进的语音技术,包括语音识别系统,说话人识别、鉴定和记录,语音增强,语音分离,语言识别,语言翻译等。ASRT 是一个基于深度学习的中文语音
FaceFusion v3 是一款基于AI的换脸工具,专注于图像和视频的面部替换。该工具使用先进的算法,能够精确处理多角度下的人脸,使换脸效果更加逼真。它的最新版本支持高质量的面部替换,适用于从简单照片到复杂视频的多种场景。
打 Kaggle 或国产大模型比赛,进入冲刺阶段,团队成员要同时跑不同的特征工程和模型融合方案。租云 GPU 成本飙升,一个月花掉好几千,团队预算吃紧。把团队已有的几张消费级显卡(如 4090)通过 OrionX 池化成一个虚拟算力池。显存超分技术让每张卡能支撑更大 batch size 或更高分辨率输入。成员按需申请算力,跑完即释放,避免资源闲置。云 GPU 租用成本降低 60%并行实验数量翻倍

打 Kaggle 或国产大模型比赛,进入冲刺阶段,团队成员要同时跑不同的特征工程和模型融合方案。租云 GPU 成本飙升,一个月花掉好几千,团队预算吃紧。把团队已有的几张消费级显卡(如 4090)通过 OrionX 池化成一个虚拟算力池。显存超分技术让每张卡能支撑更大 batch size 或更高分辨率输入。成员按需申请算力,跑完即释放,避免资源闲置。云 GPU 租用成本降低 60%并行实验数量翻倍
