




- @2401_85325397
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
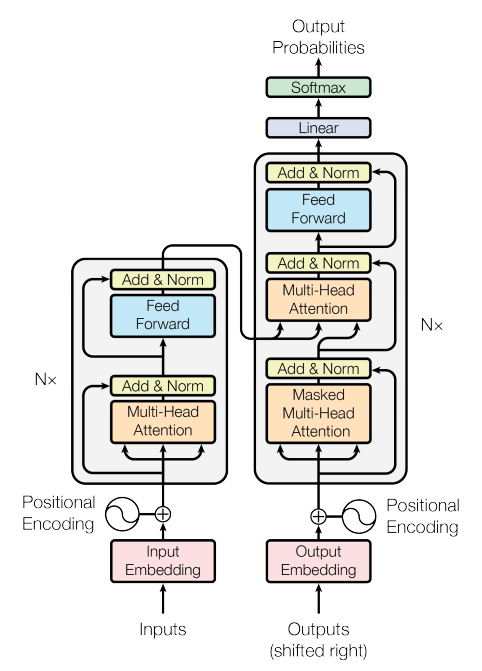
GNN是一类用于处理图数据的深度学习模型,能够捕捉节点间的依赖关系。它们在多个领域表现出色,如社交网络分析、物理系统建模、蛋白质接口预测和疾病分类。由于Transformer强大的性能,Transformer模型及其变体已经被广泛应用于各种自然语言处理任务,如机器翻译、文本摘要、问答系统等。

GPT是由openAI提出的一种算法思想\[2\],其主要思想是通过在大规模的预料上进行模型的训练,然后在特定任务上进行为调。所以其总体思想分为无监督的训练和有监督的微调。
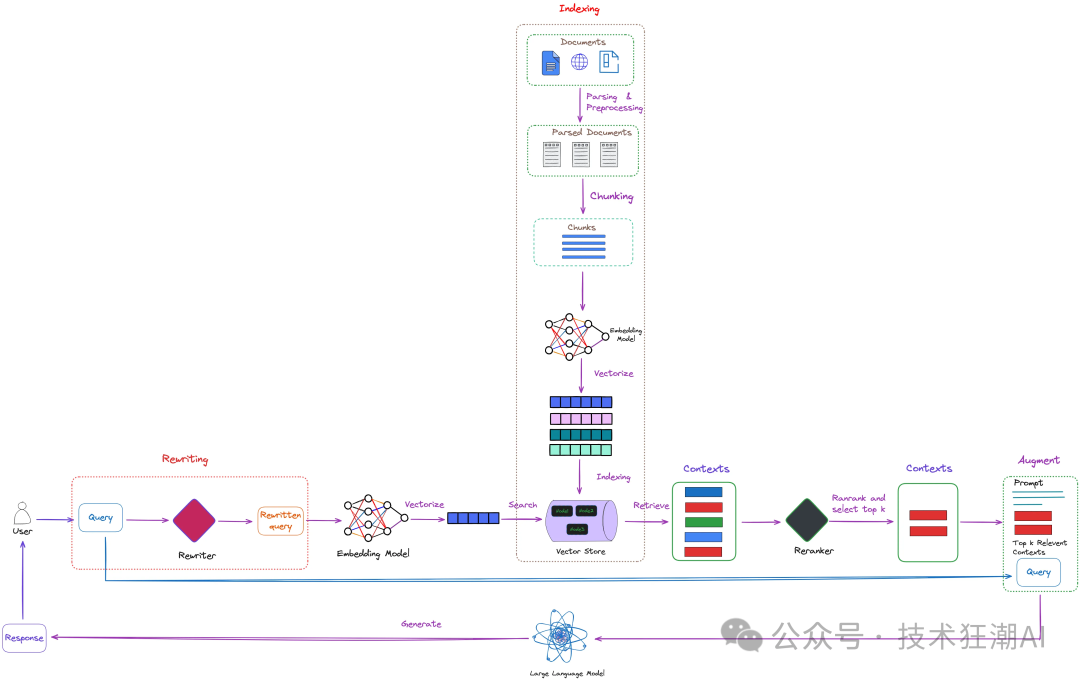
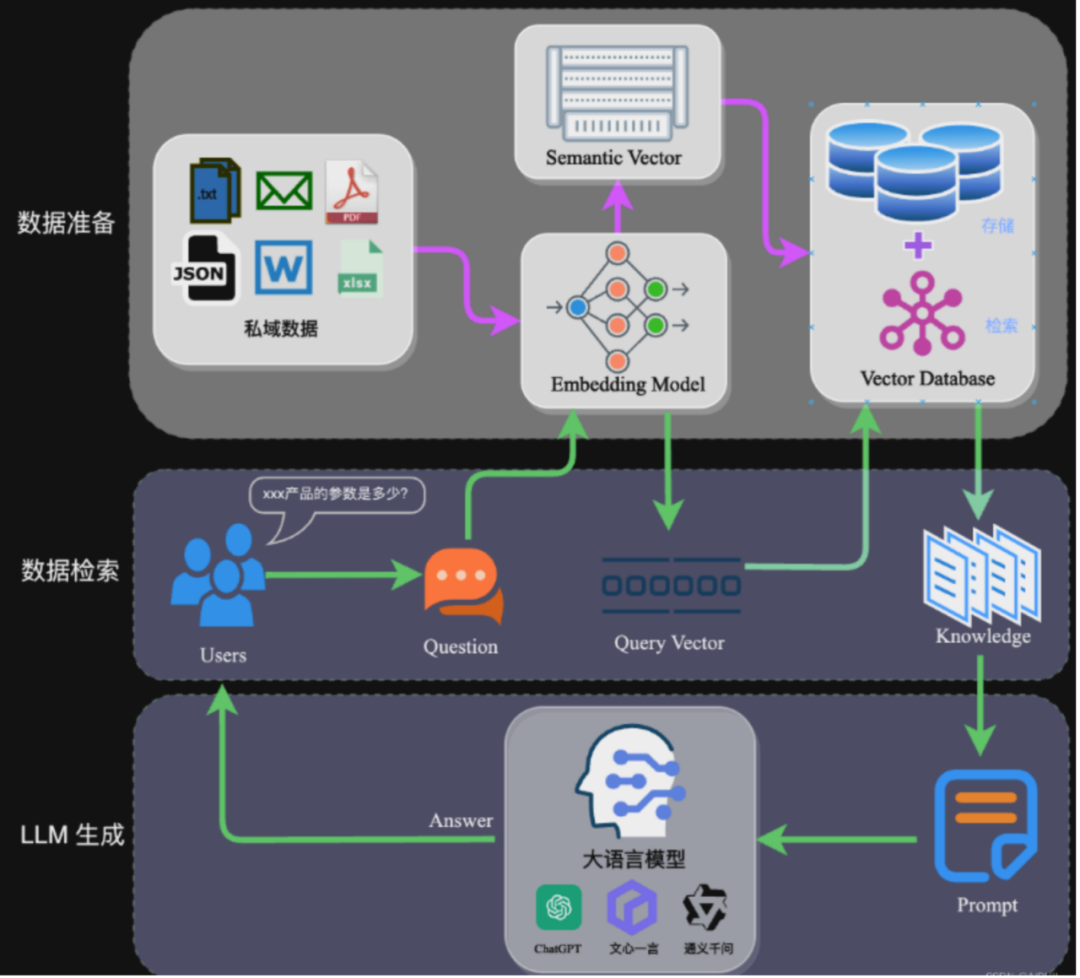
检索增强生成 (RAG) 作为人工智能 (AI) 领域的一项重要技术,近年来得到了飞速发展。它将基于检索模型和基于生成的模型相结合,利用海量外部数据,生成更具信息量、更准确、更具语境相关性的回复。检索策略是 RAG 系统的关键组成部分,它直接影响着系统的性能和效率。
在人工智能飞速发展的今天,大语言模型(LLMs)凭借其强大的语言处理能力在诸多领域大放异彩。检索增强生成(RAG)系统的出现,通过整合外部知识源进一步提升了 LLMs 的性能,使其能针对用户查询提供更准确、更具上下文相关性的回答,在众多知名应用中得到广泛采用。然而,这一系统并非坚不可摧,语料库中毒攻击成为了严重威胁其性能的安全隐患。在此背景下,TrustRAG 应运而生,为解决 RAG 系统的安全

RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。RAG模型由Facebook AI Research(FAIR)团队于2020年首次提出,并迅
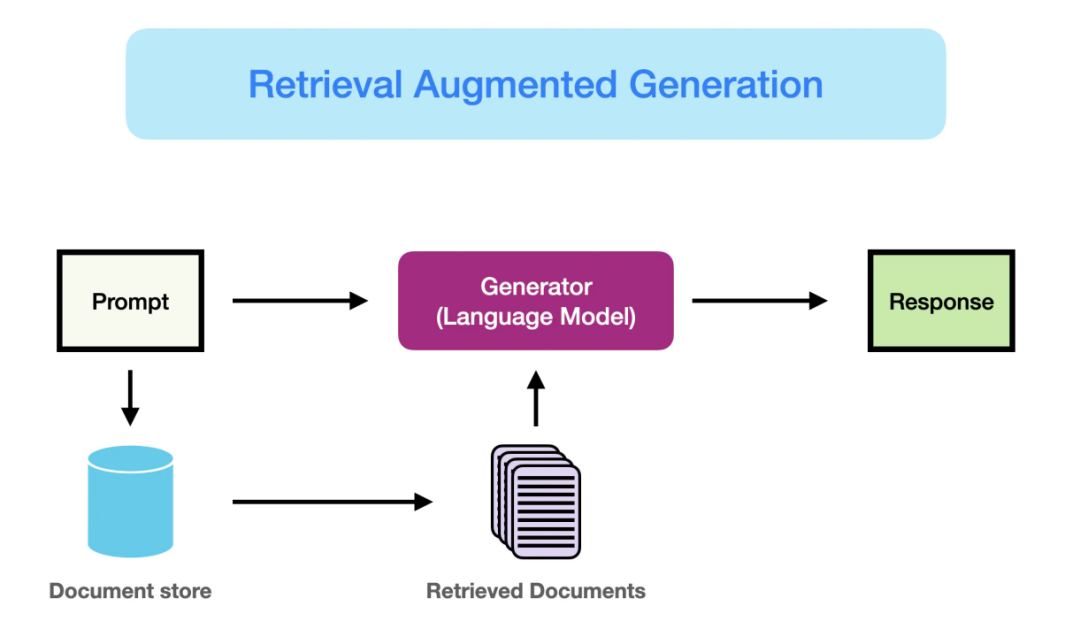
RAG,即检索增强生成(Retrieval-Augmented Generation)。在大型语言模型不断发展的背景下,它应运而生,成为解决语言模型诸多挑战的一把利器。大型语言模型尽管强大,但有时会存在信息偏差、知识更新滞后、内容不可追溯、领域专业知识能力欠缺、推理能力限制以及应用场景适应性受限等问题。而 RAG 巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精

OpenAl 2022年底发布ChatGPT再度引爆人工智能的全球研究热潮,各国纷纷投入或加强对A|大模型的研究,其中中国、美国成果频出,引领产业发展。从市场格局来看,海外企业占据大模型先发优势,几大巨头科技企业及个别人工智能企业已经完成几轮A大模型迭代,性能不断提升;国内AI大模型建设方“百花齐放”,依托技术优势及业务经验,在构建通用大模型的同时,打造具备企业业务特色、行业特色的专用A大模型,并

当我们谈论AI,谈论人工智能领域时,经常会提到“模型微调”。这个词儿听起来可能有些专业,但它的的确确是解锁AI强大潜力,让AI更加精准地服务于我们的需求,推动人工智能落地的关键。
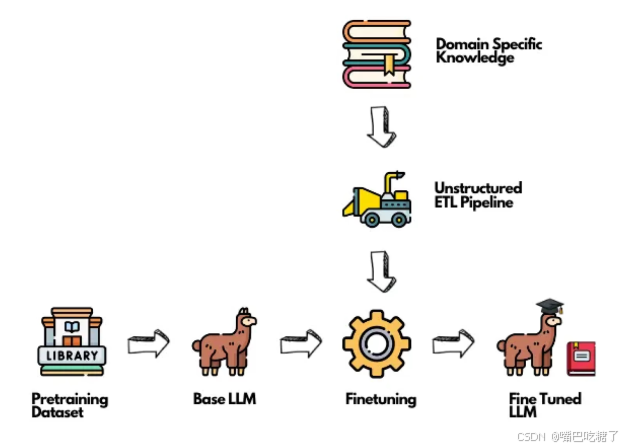
当下人工智能(Generative AI)快速发展,各种大模型(文心一言、通义千问、豆包、混元等)以及文生图、文生视频、以及其他功能性AI层出不穷。目前AI的发展趋势从增加参数数量使大模型更加智能转向大模型在行业内的应用落地。
近日,应急管理部正式发布应急管理领域的“久安”AI(人工智能)大模型。抓住新一轮科技革命的历史机遇,优化整合资源,强化科技支撑,是提升应急管理工作科学化、专业化、智能化、精细化水平的必答题。“久安”AI大模型一经发布,就引起了社会的广泛关注。“久安”AI大模型是什么,有哪些功能功效,