
CUDA:解锁并行计算潜能的通用加速引擎
CUDA作为NVIDIA推出的并行计算平台,自2006年问世以来,已成推动人工智能、科学计算等领域技术突破的核心引擎。其架构涵盖硬件抽象层、运行时环境及开发工具链三层,通过SIMT架构、内存层次优化等实现性能突破,在金融、医学等多领域广泛应用。CUDA构建了从硬件到软件的闭环生态,拥有庞大开发者群体和行业认证标准。尽管面临华为CANN等开放生态竞争及光子计算等能效挑战,CUDA仍持续进化,其开创的
目录
在人工智能训练需处理万亿参数、气候模拟需解析千米级网格、基因测序需比对百亿碱基对的今天,传统CPU的串行计算模式已触及物理极限。一种名为CUDA的并行计算范式,正通过重构计算架构,将计算效率提升百倍以上,重新定义高性能计算的边界。
一、从图形渲染到通用计算的范式革命
早期GPU设计聚焦于像素渲染的并行处理,其架构包含数千个简化计算单元,可同时处理数百万像素的相似运算。2001年,可编程着色器的出现使开发者首次获得GPU软件控制权,学术界随即发现其浮点运算能力远超CPU。2006年,统一计算单元架构的诞生,彻底打破图形与计算的界限,形成灵活的并行核心阵列。
次年,CUDA编程模型正式发布,通过类C语言语法和三级线程架构(Grid→Block→Thread),将复杂的并行编程简化为线程调度问题。开发者无需掌握图形API,即可直接操控GPU的数千核心,实现数据并行任务的加速。这种变革使GPU从图形处理器进化为通用并行计算引擎,为深度学习、科学计算等领域带来颠覆性突破。
二、异构计算的黄金分割法则
CUDA采用CPU+GPU的异构架构,遵循"逻辑控制归CPU,数值计算归GPU"的黄金法则。以矩阵乘法为例,CPU负责任务分解与数据调度,GPU则通过32线程组成的Warp同步执行浮点运算。这种分工使万亿次浮点运算的矩阵乘法,在GPU上仅需毫秒级完成,而传统CPU需数分钟。
内存架构设计堪称CUDA性能核心。其分层内存模型包含:
- 全局内存:64GB/s带宽的显存,支持TB级数据存储
- 共享内存:线程块内高速缓存,延迟比全局内存低100倍
- 寄存器:每个线程独享的KB级存储,访问速度达纳秒级
- 常量/纹理内存:针对特定访问模式优化的只读缓存
在气象模拟中,共享内存可缓存相邻网格点的气压数据,避免全局内存的重复访问;在深度学习卷积运算中,寄存器可存储中间计算结果,减少内存带宽占用。这种精细化的内存管理,使CUDA程序能充分利用GPU的30TFLOPS算力。
三、超越硬件的生态壁垒
CUDA的成功不仅源于硬件性能,更在于其构建的完整生态:
- 开发工具链:nvcc编译器支持C/C++/Fortran扩展,Nsight工具提供纳米级性能分析
- 数学库矩阵:cuBLAS实现线性代数运算加速,cuFFT优化傅里叶变换,cuDNN专为神经网络设计
- 领域框架:OptiX加速光线追踪,Thrust提供并行算法模板,TensorRT优化推理部署
这种生态优势形成强大的技术护城河。在金融风险建模领域,CUDA加速使蒙特卡洛模拟速度提升18倍,使高频交易策略的回测周期从周级缩短至小时级。在生命科学领域,AlphaFold2的蛋白质结构预测通过CUDA优化,将推理时间从数天压缩至分钟级。
四、未来演进:从加速计算到认知增强
随着Blackwell架构的发布,CUDA进入3.0时代。新一代Tensor Core支持FP8精度运算,使LLM训练的内存占用降低50%;动态内存压缩技术将显存带宽利用率提升至95%;多实例GPU(MIG)技术实现单个GPU的7路虚拟化,大幅提升资源利用率。
在应用层面,CUDA正从后台加速走向认知增强。实时医学影像分析系统通过CUDA加速,使MRI扫描的3D重建时间从10分钟降至8秒;自动驾驶感知模块利用CUDA优化,实现200TOPS算力下的40帧/秒处理速度;气候预测模型通过CUDA加速,将台风路径预测的时空分辨率提升至1公里/小时。
从2006年G80架构的诞生,到如今支撑万亿参数大模型训练,CUDA用18年时间证明:当软件生态与硬件创新形成共振,就能创造出改变行业格局的技术范式。在算力需求呈指数级增长的AI时代,这种并行计算加速引擎将继续推动人类认知边界的拓展。
文章正下方可以看到我的联系方式:鼠标“点击” 下面的 “威迪斯特-就是video system 微信名片”字样,就会出现我的二维码,欢迎沟通探讨。
更多推荐
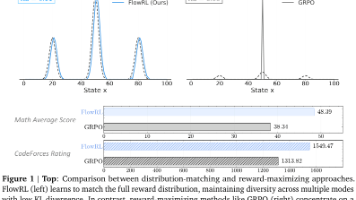

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)