




- @weixin_43156294
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在精准医疗与数字化健康管理的浪潮下,生命体征检测正从传统单一参数监测向多维度同步感知演进。心率、血压、呼吸率、体温等核心生理指标的精准捕获,是临床诊断、慢性病管理及健康风险预警的核心基础。然而,单一传感器易受环境干扰、生理波动等因素影响,存在数据碎片化、精度不足等局限。多模态传感器融合技术通过整合不同类型传感器的互补信息,构建全维度生命体征监测体系,实现从“数据采集”到“精准解读”的跨越式升级,为

20世纪末,柔性电子技术开始起步,为柔性传感器的发展奠定了基础。2004年,香港理工大学研发团队开始探索softceptor技术。同年,Someya等人提出了基于有机场效应晶体管的大面积柔性压力传感器矩阵,为人工皮肤应用等奠定了基础。2011年,界面超级电容式传感的全新压力传感模式被提出。2022年,厦门大学周伟教授团队发表了关于超灵敏高频动态力检测的柔性触觉传感器工作新模式的研究,突破了传感器灵

智能机器人,这一曾经只存在于科幻作品中的概念,如今正逐步从虚幻走向现实,在工业制造、医疗健康、服务行业等诸多领域崭露头角,发挥着愈发重要的作用。在工业制造领域,智能机器人能够承担高精度、高强度的生产任务,极大地提高生产效率和产品质量;在医疗健康领域,它们可辅助医生进行手术、护理病人,为医疗服务带来更多的精准性和便利性;在服务行业,智能机器人能为顾客提供个性化的服务,如餐厅的点餐送餐、酒店的客户引导

稠密大模型与稀疏大模型代表了大语言模型两种核心设计理念:稠密模型追求全参数协同、极致通用,稀疏模型坚持按需激活、高效低成本。二者没有绝对优劣之分,仅存在场景适配差异。稠密模型是通用智能的基石,稀疏模型是规模化落地的关键。随着技术不断完善,两类模型将协同发展,共同平衡大模型性能、成本与落地难度,持续推动人工智能技术向产业化、平民化方向进阶。
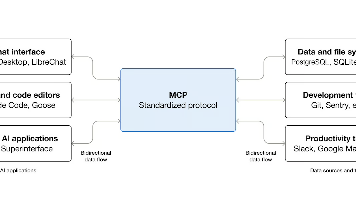
1.协议基本信息•发布方:Anthropic•正式发布时间:2024年11月•底层依赖:JSON-RPC 2.0•协议特性:有状态双向会话、能力自动协商、分层通信架构、支持本地STDIO与远程HTTP双传输模式•配套生态:官方规范文档、多语言SDK(Python/TypeScript等)、MCP Inspector调试工具、官方参考服务端2.核心设计理念1)关注点分离:拆分AI应用主机、协议客户端
1.面向大模型的标准化能力封装区别于传统大模型Prompt提示词、Function Calling函数调用、RAG知识库片段,Agent Skills是完整闭环的能力封装单元:•封装完整性:单一Skill文件夹同时收纳领域知识、标准业务流程、可调用工具、输出格式规范、异常兜底方案五大核心要素,而非单一知识或单一接口;•调用自动化:摆脱人工指定函数、手动输入prompt的限制,依靠文件夹标签、场景语

1.普通后端数据对象:以人为中心,数据是业务的台账,规矩越多、结构越固定越好;2.传统机器学习数据对象:以模型特征为中心,抛弃业务含义,一切为数值计算服务;3.大模型数据对象:以语义和向量为中心,抛弃固定数据表结构,适配自然语言和高维空间计算。后端开发学的是如何让数据准确,AI开发学的是如何让数据更适合机器理解,这就是二者数据对象最底层、永远无法逾越的核心区别。

Tree of Thought思维树的核心突破,不在于简单优化推理步骤,而在于重构了大模型的思考逻辑。它让大模型彻底摆脱了机器式的线性生成,拥有了人类独有的分层思考、多试错、可回溯、善择优的高阶认知能力,填补了大模型在复杂逻辑推理、智能决策领域的能力空白。从线性思维到树形思维,是大模型从“被动生成”向“主动思考”的关键跨越。随着技术的持续迭代,ToT将成为大模型基础推理的核心标配,赋能人工智能在科

当下AI行业门槛看似越来越低,开源框架遍地、API接口通用、现成Demo随处可见。很多新手入门AI的最快路径,就是复制代码、调用开源库、拼接大模型接口,跑通一个可视化项目,就自诩掌握了AI开发,顺利入行成为AI应用开发工程师。但行业真实的残酷真相是:只会调包、不懂底层的开发者,终其一生只能停留在初级执行岗,永远无法突破瓶颈成为高薪、稀缺的高级AI工程师。在AI行业洗牌加剧、基础工具愈发普及的202

基础数据结构是机器学习的底层基石。机器学习的模型算法是上层“表象”,而数组、链表、哈希表则是支撑表象落地的底层“根基”。数组以连续内存与高效数值运算,撑起了机器学习所有核心计算场景;链表以动态灵活的特性,适配了各类可变数据与动态迭代场景;哈希表以高效键值映射,实现了全流程的检索加速与冗余优化。从数据预处理到模型训练,从迭代优化到线上部署,三类基础数据结构贯穿机器学习全过程,其内存特性与时间复杂度的
