




- @ttsta
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LLaMA-Mesh 是一个创新项目,旨在利用大型语言模型(LLM)的能力,实现文本描述到 3D 网格模型的统一生成。用户只需输入自然语言描述(例如,“Create a 3D model of a wooden hammer”),模型就能理解并生成对应的 3D 网格。它直接输出包含顶点坐标和面定义等数值信息的标准 OBJ 格式文件。
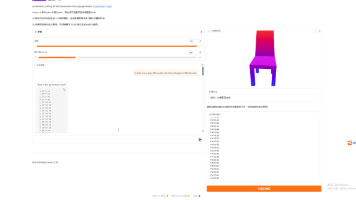
人工智能(AI)最早由约翰·麦卡锡在 1956 年的达特茅斯会议上提出。简单说,人工智能就是让机器能够像人一样思考、学习和解决问题。从学术上看,它研究如何模拟、延伸和扩展人的智能,试图理解智能的本质,并制造出能以类似人类智能方式做出反应的机器。日常生活中的语音助手、购物推荐、导航规划,背后都有人工智能的影子。根据能力水平,人工智能可以分为三个层次。第一是弱人工智能,也就是专用人工智能,只擅长解决特

Hermes Agent 是一个来自 Nous Research 的开源 AI Agent 框架,能够连接 Ollama 本地模型、OpenRouter、Anthropic 等多种后端。其核心能力包括:文件系统操作(读取、写入、搜索、打补丁)终端命令执行浏览器自动化(点击、填写表单、截图)代码生成与调试任务委托与流程自动化可以将其理解为一个运行在终端里的 AI 助手,接收自然语言指令并完成具体操作

AI Agent不是遥不可及的科幻,而是正在发生的变革。它就像当年的个人电脑、智能手机、云计算一样,会重塑我们与数字世界交互的方式。你不必成为AI专家,但至少应该成为AI的使用者。从今天开始,试着给你的AI一个“行动”指令,而不是只问“是什么”。你会发现,一个全新的效率世界正在向你敞开。想快速体验AI Agent的魅力?星海智算平台已集成多款热门AI Agent镜像,一键部署,开箱即用。

当 AI 学会彼此协作,我们迎来的不是更聪明的工具,而是一个新的“物种社会”无论单个模型有多聪明、手里的工具(MCP Server)有多全,它终究只是一个“单体大脑”。让同一个 Agent 同时扮演产品经理、资深程序员、测试员和运维专家,它很快就会陷入角色混乱和上下文爆炸。真正的突破,在于让 AI 形成社会。这就是本文要讲的核心:Agent-to-Agent(A2A)通信与多智能体协同。我们将从单

当 AI 学会彼此协作,我们迎来的不是更聪明的工具,而是一个新的“物种社会”无论单个模型有多聪明、手里的工具(MCP Server)有多全,它终究只是一个“单体大脑”。让同一个 Agent 同时扮演产品经理、资深程序员、测试员和运维专家,它很快就会陷入角色混乱和上下文爆炸。真正的突破,在于让 AI 形成社会。这就是本文要讲的核心:Agent-to-Agent(A2A)通信与多智能体协同。我们将从单
Hermes Agent 是一个来自 Nous Research 的开源 AI Agent 框架,能够连接 Ollama 本地模型、OpenRouter、Anthropic 等多种后端。其核心能力包括:文件系统操作(读取、写入、搜索、打补丁)终端命令执行浏览器自动化(点击、填写表单、截图)代码生成与调试任务委托与流程自动化可以将其理解为一个运行在终端里的 AI 助手,接收自然语言指令并完成具体操作
Hermes Agent 是一个来自 Nous Research 的开源 AI Agent 框架,能够连接 Ollama 本地模型、OpenRouter、Anthropic 等多种后端。其核心能力包括:文件系统操作(读取、写入、搜索、打补丁)终端命令执行浏览器自动化(点击、填写表单、截图)代码生成与调试任务委托与流程自动化可以将其理解为一个运行在终端里的 AI 助手,接收自然语言指令并完成具体操作
USO(Unified Style and Subject-Driven Generation via Disentangled and Reward Learning)是一项前沿的生成式AI框架,由智能创作实验室UXO团队研发。该框架创新性地解决了生成式模型中风格与主题控制相互割裂的痛点,通过统一的架构实现了内容与风格的有效分离与重新组合,为多模态图像生成提供了全新的解决方案。
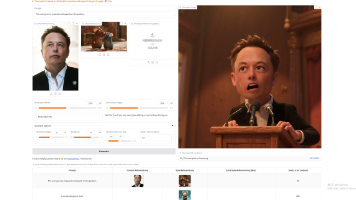
人工智能(AI)最早由约翰·麦卡锡在 1956 年的达特茅斯会议上提出。简单说,人工智能就是让机器能够像人一样思考、学习和解决问题。从学术上看,它研究如何模拟、延伸和扩展人的智能,试图理解智能的本质,并制造出能以类似人类智能方式做出反应的机器。日常生活中的语音助手、购物推荐、导航规划,背后都有人工智能的影子。根据能力水平,人工智能可以分为三个层次。第一是弱人工智能,也就是专用人工智能,只擅长解决特