
写文章




- @SJJS_1
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
告别“残血”iPhone体验,“Apple智能”大模型正式完成备案!
2026年7月15日,苹果中国版生成式AI服务“Apple智能”通过国家网信办备案,采用“端侧轻量化模型+阿里通义千问云端底座”的混合架构,数据完全国内合规。

告别“残血”iPhone体验,“Apple智能”大模型正式完成备案!
2026年7月15日,苹果中国版生成式AI服务“Apple智能”通过国家网信办备案,采用“端侧轻量化模型+阿里通义千问云端底座”的混合架构,数据完全国内合规。
真金白银加码 AI!贵州重磅推出 20 条扶持新政,算力与应用双向提速
贵州省发布《大数据发展专项资金支持人工智能发展指南(2026年版)》,推出20条专项政策加速AI产业发展。
硅谷规模最大种子轮!OpenAI 前 CTO 初创企业获20亿美元融资,英伟达、AMD联投
硅谷史上规模最大的种子轮融资诞生了!前OpenAI CTO新公司刚成立就拿下20亿美元,估值破百亿。

深夜重磅!OpenAI 开源双模型:120B 近 o4-mini,20B 笔记本可用
时隔六年,OpenAI 终于重新踏入开源领域。
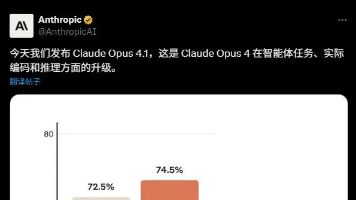
AI编程避坑指南:常见错误与解决策略
AI编程并不是简单的偷懒工具,而是一个反向促使你思考的过程。刚开始使用AI写代码可能觉得比自己写还累,因为它就像一个“不能自动对齐语境”的智能搭档。但随着使用的深入,你会意识到AI编程并没有降低难度,而是将开发的难点从动手转移到了动脑,从写代码转向了清晰表达自己的想法。通过实践上述策略,你可以显著提高AI编程的效率和质量,让AI真正成为你的得力助手,而不是反复返工的负担。记住,AI不会取代程序员,

AI 时代如何保持领先?OpenAI 发布最新白皮书:五大原则助力企业破局
OpenAI发布《在AI时代保持领先:领导力指南》,提出五大原则帮助企业应对AI时代的挑战。

DeepSeek被曝年底推出AI智能体,下一代人机交互时代要来了?
智能体爆发元年,DeepSeek也要入局了?

OpenAI编程模型重磅升级!GPT-5-Codex发布,动态思考机制实现编程效率倍增
OpenAI Codex重磅升级:实现动态思考,编程效率飞跃,能独立编程7小时。

中国AI突破!DeepSeek-R1论文登《自然》封面,首次披露更多训练细节
DeepSeek-R1登上《自然》封面,开源与科学检验能否成为AI新范式?
