登录社区云,与社区用户共同成长
邀请您加入社区
在 规则引擎 的数据处理链路中,TDengine 作为国产时序 database 的代表之一,帮助用户把分散的传感器数据收敛到统一的时序数据库中。某设备管理平台统计显示,其日均告警超过 10 万条,其中超过 70% 为误报,运维团队被迫花费大量时间处理无效告警,真正需要关注的异常反而被淹没。平台应关注时序库在边缘网关的轻量部署,以及在云端的集中分析能力,形成边云协同的数据架构。信息删除和修改操作缺
本文针对支付风控、对账等强时序业务场景,对比分析了时序数据库TDengine和OLAP引擎ClickHouse的选型方案。通过支付流水业务实例,详细展示了两者在表结构设计、数据写入、查询优化等方面的实现差异:TDengine采用超级表模型,天然支持多租户隔离和时序快照追加,适合高并发写入和实时监控;ClickHouse凭借MergeTree引擎和强大分析能力,更擅长复杂宽表分析和历史数据回溯。文章
从令人头痛的回调地狱,到如今基于协程的同步式异步写法,C++为开发者提供了一条愈发优雅的并发编程路径。传统的异步编程高度依赖回调函数。这种模式在简单场景下尚可接受,但一旦涉及多个嵌套的异步操作,代码会迅速演变为所谓的“回调地狱”。更重要的是,多个异步操作的顺序执行仍然需要手工编排,无法真正实现同步写法的简洁性。从回调到协程,C++异步编程的革新之路反映了语言设计哲学的演变:从提供基础工具到关注开发
1.优先选择智能指针而非原始指针:对于动态分配的资源,默认使用智能指针来管理生命周期。2.优先使用`std::make_unique`和`std::make_shared`:它们是创建智能指针的首选方式,提供了更强的异常安全性。3.正确选择智能指针类型:- 明确独占所有权时,使用`std::unique_ptr`。- 需要共享所有权时,使用`std::shared_ptr`。- 需要观测`shar
Python编程从入门到实践的全方位指南》旨在为读者铺就一条清晰的学习路径。从最基础的语法知识到复杂的项目实战,每一步都需要耐心和练习。编程的本质是解决问题,而Python则为你提供了一套强大且优雅的工具。只要保持好奇心和毅力,任何人都能掌握这门语言,并利用它创造出有价值的作品。
Cargo 是 Rust 的官方构建系统和包管理器。它负责下载项目依赖、编译代码、运行测试、生成文档等多项任务。从你创建新项目到最终发布,Cargo 始终陪伴左右。
deepseek 搭建 IDMP 需要的元素
本文介绍了工控系统中时序数据存储的完整解决方案。针对MySQL存储工控时序数据的四大痛点(写入拥堵、查询超时、索引失效、磁盘占用高),提出采用TDengine作为专业时序数据库。文章详细讲解了SpringBoot集成TDengine的关键技术点,包括工业级配置、超级表设计规范、通用入库工具类实现、批量写入优化策略等,并给出了历史数据查询示例。通过结合前三篇的采集协议(Modbus/OPC-UA/M
近日,中国信息通信研究院(简称"中国信通院")2026 上半年"可信数据库"评估测试结果正式揭晓。经来自联通软研院、陕西移动、瑞众人寿、上海国际汽车城、中国航信、邮储银行等单位的行业专家评审,涛思数据 TDengine 系列产品一举通过三项专项测评,成为本批次中同时斩获 AI 大模型时序数据管理平台、时序数据库性能、时序数据库稳定性三大领域认可的数据库产品。
摘要:本文分析了SpringBoot项目同时集成TDengine和DM8数据库时出现的驱动冲突问题,举例了两种网上无效果的方法:1)通过配置独立类加载器隔离驱动解析逻辑;2)更换达梦驱动版本(推荐8.1.2.18或8.1.1.193)。文章末尾分享了最终能解决冲突问题的方法,并提供了完整的application.yml配置示例。最终方案有效解决了两种数据库驱动的兼容性问题,适用于类似的多数据源集成
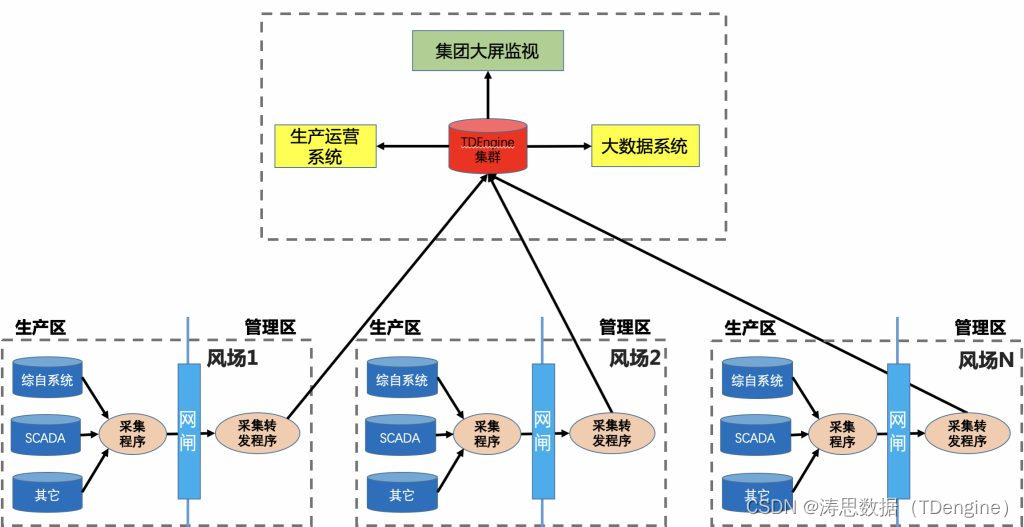
云鼎科技采用TDengine TSDB和TDgpt优化煤矿与风电数据管理 云鼎科技在煤矿安全生产管控平台中选用TDengine TSDB,实现对75对矿井、1100余个系统的工业数据采集与分析,构建了云端协同的时序数据体系。
【摘要】本文基于TDengine时序数据库设计了一套地铁综合监控系统(ISCS)的通用SOE(事件顺序记录)存储架构,适用于电力、环控(BAS)、火灾报警(FAS)等所有子系统。通过统一数据结构和标签分类实现毫秒级事件记录,满足地铁行业强制规范要求。方案包含实体类设计、TDengine超级表创建、事件生成工具、查询接口等完整实现,解决了多设备连锁故障时的根因定位问题,并通过实际项目验证了其有效性。
摘要:地铁ISCS综合监控系统面临海量工控测点存储挑战,传统MySQL方案存在写入瓶颈、查询超时等问题。本文基于国产TDengine时序数据库,设计了一套完整的时序数据归档方案:通过独立Kafka消费组获取实时测点数据,自动按线路/车站建立时序表结构,实现毫秒级批量入库与冷热数据分层。方案提供历史查询、极值统计等标准化接口,无缝对接数字孪生大屏和故障追溯功能,满足地铁运维的7天原始数据保留和90天
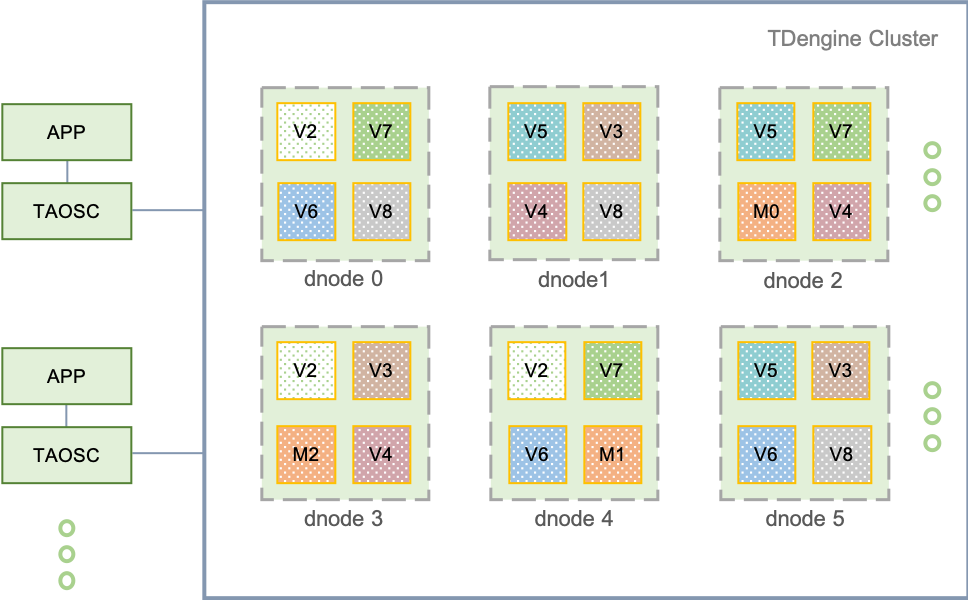
TDengine 的设计是基于单个硬件、软件系统不可靠,基于任何单台计算机都无法提供足够计算能力和存储能力处理海量数据的假设进行设计的。因此 TDengine 从研发的第一天起,就按照分布式高可靠架构进行设计,是支持水平扩展的,这样任何单台或多台服务器发生硬件故障或软件错误都不影响系统的可用性和可靠性。同时,通过节点虚拟化并辅以自动化负载均衡技术,TDengine 能最高效率地利用异构集群中的计算
只能识别正脸,侧脸低头戴口罩全歇菜光线影响很大,要是考勤机对着窗户,逆光根本抓不到脸戴隐形眼镜有时候识别率会下降(可能是我扒的ORL库戴眼镜的样本少?没有集成摄像头,只能拿拍好的图片测试抓脸的时候可以加个眼睛检测,确保是正脸降维之后可以加个LDA(线性判别分析),提升类间距离集成MATLAB的摄像头工具箱,实时抓脸实时识别加个Excel导出功能,记录考勤时间。
TDengine 中的流计算,功能相当于简化版的 FLINK , 具有实时计算,计算结果可以输出到超级表中存储,同时也可用于窗口预计算,加快查询速度。
TDengine数据订阅基本概念,可参考之前写的文章 [数据订阅](https://blog.csdn.net/ticktick999/article/details/143118127), 本文重点从实操方面介绍数据订阅的使用。
在应对海量时序数据处理需求时,如关系型数据库、工业实时库、Hadoop 大数据平台在内的传统数据库解决方案问题重重,严重阻碍数字化进程。在此背景下,一些企业开始尝试进行数据架构改造,选择适合的时序数据库产品。
在软件定义汽车的时代,电动汽车每天产生数十GB的时序数据,包括电池电芯电压温度、电机转速、传感器读数、自动驾驶轨迹等。高效管理这些数据,直接影响车辆安全、用户体验和商业模式创新。本文结合行业最佳实践,提出四大关键选型维度。基于以上四个维度的综合分析,电动汽车企业在选择时序数据库时,除了考察产品的基本技术指标外,更应关注其在行业内的权威认证和市场地位。
本文系统阐述了实时数据库高可用与容灾备份的核心技术与实施方案。首先分析了高可用架构的价值,指出金融等行业数据库停机的高昂成本。详细介绍了主从复制、双活架构等关键技术,强调数据同步与一致性的保障措施。在容灾方面,对比了实时容灾、跨地域备份等方案的优缺点,提出RTO/RPO指标对方案选择的关键影响。文章还提供了部署指南与最佳实践,包括读写分离、故障切换演练等具体方法。最后展望了云原生、智能化等未来发展
在使用或者实现分布式数据库(Distributed Database)时,会面临把一个表的数据按照一定的策略分散到各个数据库节点上的情况,随之而来的是多节点数据查询复杂性的问题,例如 Join 和子查询。本文将会为你解读分布式数据库下子查询和 Join 等复杂 SQL 如何实现,来帮助你更好地解决上述问题。......
TDengine的技术引领性,体现在它并非在现有数据库基础上“打补丁”,而是从第一性原理出发,围绕时序数据的核心特点,对数据库的存储、计算、分发等各个环节进行了彻底的、一体化的重构。技术引领点: TDengine的存储引擎不是对通用组件的简单封装,而是从时序数据强时序、多设备、低价值密度的特点出发,从数据结构层面进行的原生设计,这是其性能实现数量级提升的根本原因。技术引领点: 内建的多级缓存与存储
一种基于YOLOv8改进的高精度红外小目标检测算法 (自研)创新点:1)SPD-Conv特别是在处理低分辨率图像和小物体等更困难的任务时优势明显;2)引入Wasserstein Distance Loss提升小目标检测能力;3)YOLOv8中的Conv用cvpr2024中的DynamicConv代替;组合创新,可直接使用至其他小目标检测任务;实验结果:在红外小目标检测任务中mAP由原始的0.755
在金融量化交易的世界里,时间就是金钱,而延迟则是最大的原罪。现代量化交易系统需要处理来自各大交易所的 Tick 级(逐笔交易)甚至 Order Book(订单簿)深度行情数据。这些数据呈现出极端的爆发性、海量性以及对时间精度的严苛要求。为了在瞬息万变的金融市场中抢占先机,量化机构的 IT 团队正在将传统的关系型数据库或普通的文件系统,全面升级为 TDengine 等拥有极致性能的 时序数据库。本文
本文围绕时序数据库国产化替代需求,分析 InfluxDB、TimescaleDB、TDengine 在合规、兼容、性能及运维上的痛点,介绍自主可控、高兼容、高性能与多模融合等技术优势。结合能源、政务、工业互联网等真实落地案例,验证其可平滑替代主流时序库,并在写入、查询、存储成本上显著优化。文章给出可落地的迁移方案与实施要点,为企业时序数据库国产化升级提供实践参考。
tdengine
——tdengine
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
 AMD开发者中国社区
AMD开发者中国社区

 AI Agent技术社区
AI Agent技术社区









 DAMO开发者矩阵
DAMO开发者矩阵