登录社区云,与社区用户共同成长
邀请您加入社区
Cargo 是 Rust 的官方构建系统和包管理器。它负责下载项目依赖、编译代码、运行测试、生成文档等多项任务。从你创建新项目到最终发布,Cargo 始终陪伴左右。
涛思数据库
把库卡给的GSDML-V2.3-KUKA-PN-20190312.xml扔进去,这时候设备目录里就能看到KUKA机器人选项了。用Wireshark抓包发现PLC疯狂发诊断请求,最后在机器人配置里把Profinet看门狗时间从默认2s改成5s,世界安静了。库卡机器人与西门子PLC通讯案例中文版,有配置资料,库文件可以拿来直接用,也可以参考借鉴学习研究,送相关手册资料。库卡机器人与西门子PLC通讯案例
ruoyi-vue框架添加涛思数据源,同时修改原有框架的数据库连接池
TDgpt 在企业版中提供预测分析模型和异常检测模型有效性评估工具,该工具能够使用 TDengine 中的时序数据作为回测依据,评估不同预测模型或训练模型的有效性。该工具在开源版本中不可用使用评估工具,需要在其相关的配置文件中设置正确的参数,包括选取评估的数据范围、结果输出时间、参与评估的模型、模型的参数、是否生成预测结果图等配置。在具备完备的 Python 库的运行环境中,通过shell调用 T
时序数据基础模型是专门训练用以处理时间序列数据预测和异常检测、数据补齐等高级时序数据分析功能的基础模型,时序基础模型继承了大模型的优良泛化能力,无需要设置复杂的输入参数,即可根据输入数据进行预测分析。序号参数说明1tdtsfm_1涛思时序数据基础模型 v1.02time-moeMoE 时序基础模型3moiraiSalesForce 开源的时序基础模型4chronosAmazon 开源的时序基础模型
TDengine 中定义了异常(状态)窗口来提供异常检测服务。异常窗口可以视为一种特殊的,即异常检测算法确定的连续异常时间序列数据所在的时间窗口。与普通事件窗口区别在于,时间窗口的起始时间和结束时间均由分析算法识别确定,不通过用户给定的表达式进行判定。因此,在WHERE子句中使用关键词即可调用时序数据异常检测服务,同时窗口伪列(_WSTART_WEND_WDURATION)也能够像其他时间窗口一样
上面是 TDgpt 的下一代新产品的技术介绍发布会, 会上将有重大技术革新公布,欢迎大家扫码预约直播!
analyse.sh脚本用于在 TDengine 数据库上执行时间序列预测和异常检测分析,支持滑动窗口算法处理。时间序列预测 :使用 HoltWinters 等算法进行未来值预测。异常检测 :使用 k-Sigma 等算法识别数据异常点。自动窗口滑动 :支持自定义窗口大小和步长进行连续分析。
TDengine 持续扩展 SQL 语法,新版本可能将之前的标识符变为保留字。业务命名避免使用 SQL 标准关键字对可能成为关键字的名字(如countorder)一律用反引号。
4.查询引擎 |:03 语义分析:TDengine v3.x(v3.3.x / v3.4.x)|最后更新:2026-06-09语义分析(Translator)是连接 Parser 与 Planner 的桥梁。它验证 SQL 在语义上是否合法(表是否存在、列类型是否匹配、聚合函数使用是否正确等),并对 AST 做规范化重写,为后续计划生成准备一棵"干净"的逻辑表达。
先学习什么是正常,然后发现任何不符合"正常模式"的东西。**Autoencoder(自编码器)**是 TDgpt 内置的深度学习模型。学习阶段:模型学习如何"压缩"正常数据,然后再"还原"它检测阶段:如果一个数据点能被很好地压缩和还原,说明它符合正常模式;如果还原误差很大,说明它是异常的想象一下,你让一个艺术家临摹各种人脸照片。对于正常的人脸,他能画得很像;但如果给他一张外星人的脸,他就画不像了—
中国软件行业协会发布《"人工智能+工业软件"融合应用成熟度评价规范》(T/SIA 064—2026),填补行业空白。该标准由27家单位共同起草,历时一年完成研制,明确了评价体系与分级架构,涵盖数据管理、智能分析等核心指标。北京涛思数据作为主要参与单位,依托其TDengine时序数据库和IDMP工业数据管理平台的技术积累,为标准提供重要支撑。标准实施将推动工业智能化升级,促进产业链协同发展,助力企业
标签:GEO、JSON-LD、Schema、AI爬虫、前端优化GEO(生成式引擎优化)的核心不是内容和外链,而是。本文聚焦技术实现,适合前端开发者、技术负责人阅读。
Tag(标签)是 TDengine 数据模型中区别于传统数据库的核心创新之一。Tag 将设备的静态属性(如位置、型号、楼层)从时序数据中分离出来,既避免了大量重复存储,又提供了高效的多维度过滤和分组能力。Schema 变更(ALTER TABLE/STABLE)则解决了生产环境中不可避免的"表结构演进"需求——添加新指标列、增删 Tag、修改列宽——且在线执行,不阻塞读写。Tag 的设计哲学与最佳
TDengine 的数据模型围绕一个核心设计理念——一个数据采集点一张表这与传统关系型数据库"所有设备共享一张宽表"的思路截然不同。为了在"一设备一表"的基础上实现高效的聚合查询和统一管理,TDengine 创造了**超级表(STable)**机制——同类设备共享 Schema,通过 Tag 区分个体。本文深入解析三种表类型的设计理念、内部存储结构和适用场景。超级表是同类数据采集点的模板-- 列(
工业数据必须开放,但仅有开放是不够的。如果数据在开放的过程中失去了上下文,那么它也失去了价值。下一代工业数据系统,必须在保证数据自由流动的同时,保留并增强其上下文信息。只有这样,工业数据才能真正支撑现代分析、AI 系统以及智能化运营。关于 TDengineTDengine 专为物联网IoT平台、工业大数据平台设计。其中,TDengine TSDB 是一款高性能、分布式的时序数据库(Time Ser
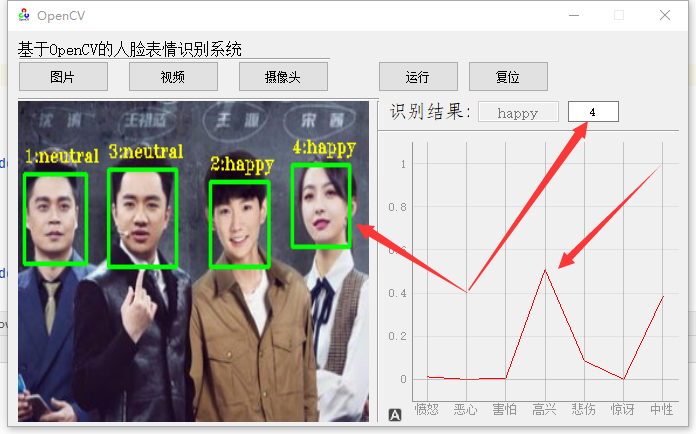
如果想优化性能,可以把MobileNet换成ONNX格式,速度还能再提20%。界面右上角的模式切换按钮建议加个快捷键,比如按V切换视频文件,按C切回摄像头,用户体验直接上档次。最后说个骚操作——在requirements.txt里加opencv-python-headless版本,打包后的体积能瘦身30%。这个项目改改还能做课堂签到系统,把表情识别换成学号二维码扫描,又是一篇毕业设计(手动狗头)。
焊缝缺陷检测,YOLO检测和分割模型,目标检测和图像分割一起实现。在工业制造领域,焊缝质量直接关系到产品的安全性和可靠性,焊缝缺陷检测至关重要。今天咱就唠唠如何借助YOLO检测和分割模型,把目标检测和图像分割一起实现,助力焊缝缺陷检测。
中原油田作为中国石化的重要油气生产基地,其生产过程控制系统(PCS)是保障油田安全生产、优化运行的核心枢纽。为解决高并发写入性能瓶颈、高昂的存储成本、复杂的实时分析需求以及多业务数据孤岛等问题,项目组于 2023 年正式引入 TDengine作为新一代数据底座。在本案例中,TDengine TSDB 作为 PCS 核心业务模块的,并通过 taosX 工具,实现了从分公司到总部的数据实时同步。
通过新增动画帧,逐帧自定义动画。
仪表板用来综合展示多个图表和数据,帮助用户快速了解整体情况。
面板数据解读功能,利用 AI 对当前面板的所有数据进行分析,自动生成结构化、易于理解且具有业务洞察力的专属分析报告,帮助用户快速抓住数据核心价值,降低数据解读门槛。
关系与非关系型数据库的开发思维转变
通过引入 TDengine TSDB,我们成功解决了智慧消防业务中的海量时序数据处理挑战,实现了从传统消防工程向智能化、数据驱动型服务的转型升级。TDengine TSDB 的高性能时序数据处理能力为公司的消防预警、设备管理和数据分析提供了坚实的技术支撑。未来,辰安科技计划与 TDengine TSDB 进一步深化合作,在消防预测性维护、人工智能火灾识别、数字孪生等前沿领域开展探索,持续推动消防安
依托“超级表”“虚拟表”等核心概念,TDengine几乎无需关联查询(Join操作),虚拟表可将多个设备、多个采集点的数据整合为一张“大宽表”,大幅降低了SQL查询的复杂度,为面板自动生成奠定基础。首先,数据交互模式从“冰冷表格”向“语义化输出”变革。时序数据库的发展趋势是整合多环节能力,成为一站式数据平台:既要具备高效的时序数据存储与计算能力,又要拥有智能分析、可视化呈现、异常报警等上层应用功能
TDengine 遇到报错 “failed to connect to server, reason: Connection refused“ 怎么办的解决方案
还在用命令行运维数据库?你真的了解 taosExplorer 吗?过去,TDengine 的管理和运维操作大多需要通过命令行执行。虽然 CLI 足够灵活,但对不熟悉 SQL 的用户来说,并不友好。更重要的是,很多企业用户并不希望把数据库操作的“主动权”只交给 DBA 或开发人员。taosExplorer 的设计目标,就是打破这种门槛。
Thingsboard 中“设备配置”和“设备”的关系是一对多的关系,通过设备配置为每个设备设置不同的配置,每个设备都会有一个与其关联的设备配置文件。等等,这不就是TDengine 中超级表的概念:超级表是一种特殊的表结构,用于代表一类具有相同数据模式的数据采集点。一个超级表有多个子表,一个子表只能隶属于一个超级表。因此,将两者有机结合起来:TDengine 中创建超级表作为“设备配置”,Thin
可以在mybatis xml文件中写入你需要的sql语句 具体你需要什么样的sql语句 可以看一下官方文档。可以解决mybatis集成涛思 执行sql的时候被拦截报错的问题。本文记录一下在实际工作中使用涛思时序数据库的问题。问题2:集成了mybatis 如何切换数据源呢?问题4:mybatis集成涛思数据库如何批量插入。一个是多表多条批量插入 ,一个是单表批量插入。问题1 : 如何使用mybati
使用docker实现emqx桥接数据到taos数据库
参考文章https://www.taosdata.com/blog/2020/09/11/1824.html
湖南维冠房地产咨询有限公司(以下称“我们”)深知隐私对您的重要性,并会尽全力保护您的隐私。本《”WFCF”数据安全及隐私保护声明》(以下简称“《声明》”)是有助于您了解我们收集、处理、存储、使用、共享和保护用户(“您”)个人信息(以下或称“信息”)的有关条款。我们希望通过本《声明》向您清晰地介绍我们对您个人信息的处理方式,因此我们建议您完整地阅读本《声明》,以帮助您了解维护自己隐私权的方式。如您对
多协议数据采集网关结合TDEngine时序数据库在车辆环境监测中的应用一、项目背景随着经济发展,国家对环境越来越重视,为贯彻《中华人民共和国大气污染防治法》,落实《汽油车污染物排放限值及测量方法(双怠速法及简易工况法)》(GB18285-2018)、《柴油车污染物排放限值及测量方法(双自由加速法及加载减速法)》(GB3847-2018)两项标准的实施,根据中国环境科学研究院发布的《在用汽车排放检验
在github上跟官方的人反馈,得到的意见是升级taos版本和驱动版本。但是这个参考的开启是基于官网的,官网也是配置了这个参数的。
过去几十年,工业系统一直在解决“如何获取数据”和“如何展示数据”的问题。但真正的挑战,从来不是数据本身,而是如何获得洞察。AI 驱动的运营洞察,正是在消除这道门槛。它让企业无需依赖复杂的分析能力,也能从数据中获得洞察,从而更快地做出决策。这不仅是一种技术进步,更是一种范式转变。从“数据系统”,走向“洞察系统”。关于 TDengineTDengine 专为物联网IoT平台、工业大数据平台设计。
涛思数据
——涛思数据
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI Agent技术社区
AI Agent技术社区


 DAMO开发者矩阵
DAMO开发者矩阵


 AI编程社区
AI编程社区





 AI硬件创业社区
AI硬件创业社区




 AtomGit开源社区
AtomGit开源社区




 腾讯云开发者社区
腾讯云开发者社区